We're excited that one of our reliably excellent mentors is back. Stefan Heimersheim (@sheimersheim, Adecco/Google DeepMind) has run great projects with Pivotal fellows for three cohorts running, and is taking on fellows again to push on the more neglected corners of mech interp: activation plateaus, computation in superposition, and toy models that actually capture what's happening in LLMs.
Excited to share our new paper (+ LW post):
"Transformers Don't Need LayerNorm at Inference Time"
We show that LayerNorm (LN) can be removed from GPT-2 models (even XL) with minimal performance loss
📄 https://t.co/QI4pgrAVK1
🧵
🧵Excited to announce our work on analyzing toy models of computation in superposition (CiS) -- was fun working with @molas_sara, @giglema, and @sheimersheim on this!
❗Main takeaway: we show that toy models in Apollo Research's APD paper are not actually performing CiS!
Applications are open for the Pivotal 2025 Q3 Research Fellowship (June 30 to August 29, London). Come work with me on cool mechanistic interpretability projects!
Feel free to email or Slack-DM me if you have questions or want to discuss project ideas!
Applications to our Q3 Research Fellowship are now open!
→ June 30 – Aug 29 in London at the London Initiative for Safe AI
→ Work on AI safety with the guidance of your experienced mentor and research manager
→ £5,000 stipend + meals, travel & housing support
(link in bio)
1/7 Excited to share our recent project from LASR Labs! We investigated on the utility of SAE latents in language models. #MechanisticInterpretability#SAE Here's what we discovered: 🧠🔍
We’ve released a new mechanistic interpretability approach. We use the loss landscape to identify computationally relevant features and interactions. Then, we build a full interaction graph and interpret it.
Theory: https://t.co/oaa2TL4XCh
Experimental: https://t.co/A9cTFIpkIe
Excited to share our write-up on activation patching best practices for mechanistic interpretability, with @NeelNanda5! Discussing noising vs. denoising and what's necessary vs. sufficient. Plus tips on which metrics to use to avoid common pitfalls. https://t.co/4kRp9VqDJt
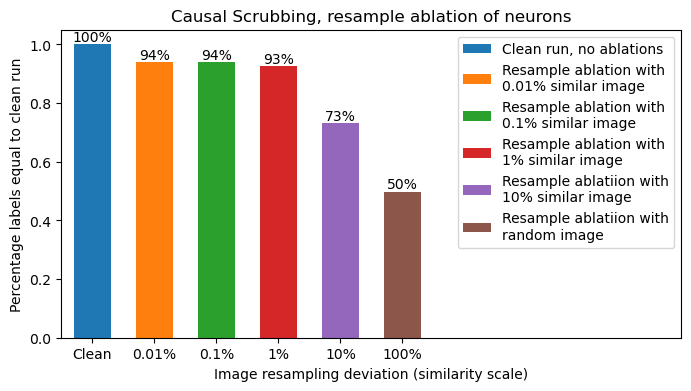
Our second claim is that the MLP simply implements an AND gate between these two filters (illustrated below), we test this using Causal Scrubbing and recover >94% performance under all allowed resample ablations.
@MariusHobbhahn and I also solved @stephenlcasper's second challenge "A Challenge for Mechanists"! Our write-up: https://t.co/AE8SdF3q3c
Summary in thread 🧵
@MariusHobbhahn@StephenLCasper Our first claim is that the model embeddings just learned two input filters (shown below in red/blue). We test this by picking inputs according to the filter colors, and indeed see that those determine the internal representation of the inputs in the residual stream (right plot).
Finally we use Causal Scrubbing to test whether our interpretation of the 200 neurons was correct, replacing every neuron's activation by that from a different input, randomly selected only to have a similar "1"-ness or "Anti-1"-ness, and it works, we recover 94% performance!
@MariusHobbhahn and I solved the first mechanistic interpretability challenge in @stephenlcasper's "A Challenge for Mechanists"! Our write-up: https://t.co/vD2sj9X33E
Summary in thread 🧵
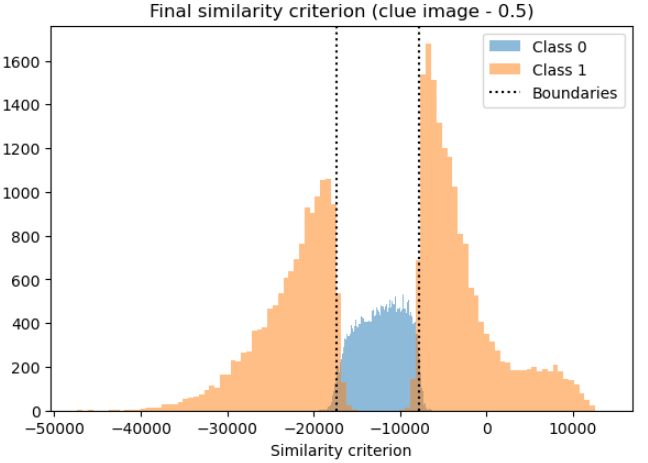
We test this if our hypothesis, that classification corresponds to similarity with "1" and "Anti-1", by manually computing the similarity manually (dotted lines) and find a 96% overlap with the neural network output (colors)!