After almost 12 years it comes to an end.
A massive thank you to Fnatic for believing in me, supporting my growth, and making my childhood dream a reality. Going from watching my idols as a kid to actually sharing the jersey with them is more than I ever could have imagined. For the past 12 years, you’ve been my home, my family, and my life. It has been an absolute honor and privilege to represent the black and orange for such a long time.
To all my past teammates, coaches, and staff: thank you for everything. Through the highs and the lows, we built memories that I will cherish forever. Each of you left a footprint on my journey, and I hope I did the same for yours. I could never have achieved any of this without you. Best of luck boys.
To the fans: I know it’s been a rough ride lately, but I want you to know that we showed up and put the work in every single day. Sometimes things don’t go your way, but I can honestly say I gave it everything I had until the very last day. I’m leaving with my head held high and I’ll always look back on my time at Fnatic knowing I left everything out there.
Just wanted to give a massive shoutout to Samuelsson. We’ve survived every project, many meetings, and chaotic times together. Thanks for being a very professional colleague but most important, a friend for life. You the goat.
The Viking has been on the battlefield for the last time in black and orange.
Over and out. #AlwaysFnatic 🖤🧡
KRIMZ
Hello everyone,
Me and Alter Ego have decided to part ways.
Really thankful for everyone I worked with during this time. Playing and living in Asia was a great experience for me, and I’m happy I had the chance to be a part of it. Now I’m back in Europe and looking forward to what’s next.
As of now, I’m officially a free agent and open to new opportunities. Motivated, hungry to prove myself and ready to do everything for my future team’s success.
Contact me through @Kuba__Chmiel & @OIekFaryna DMs are also open. RT appreciated ❤️
llama.cpp now has an official website: https://t.co/vztdUpdBWL
Our goal is to make local AI accessible to everyone, and improving the user experience is a big part of that. On the new landing page you’ll find a single-line cross-platform installer. The installation provides a single unified `llama` entrypoint which you can use to run/serve models and interface with 3rd-party agentic applications.
While oriented towards simplified user experience, the new `llama` application also provides all the advanced functionality of the existing llama.cpp tooling with which experienced users are already familiar. Also note that all GGUF models that you might have already downloaded with llama.cpp in the past will be automatically available to use without downloading again (they are stored in the common HF cache on your machine).
We have many improvements in the pipeline both at the UX and at the engine level and we plan to iteratively ship new things over the coming months. One of the main focuses will be seamless integration with local-friendly 3rd-party agents (such as Pi). In the meantime, we’ll continue to listen for feedback from the community and adjust accordingly, so keep letting us know what you think and need.
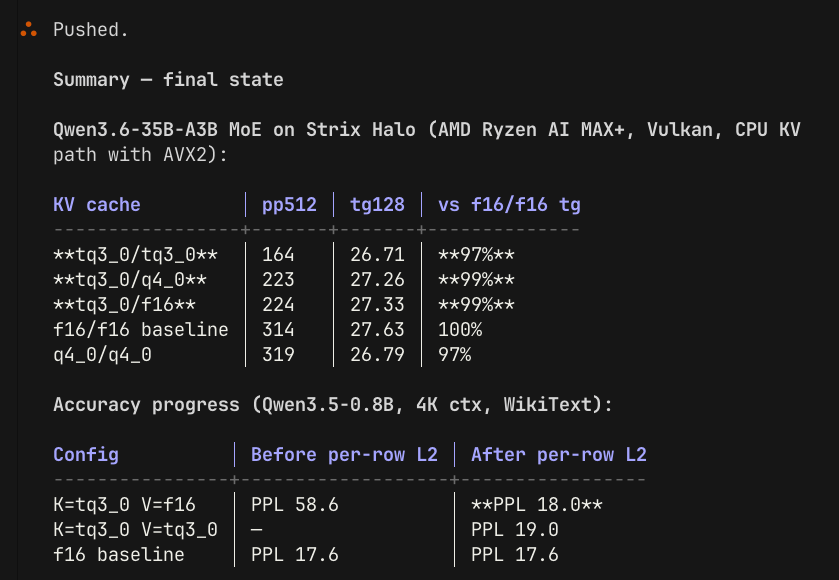
1. Dense Models - Slow and Smart
Example: Qwen3.6-27B / Gemma-4-31B
What it means:
- when a prompt is sent
- it gets tokenised (words are mapped to tokens)
- token generation starts
- the 27B means 27 billion parameters
- each of those parameters will be activated
- 27 billion matrix multiplications
- for every token generated
Active parameter counts are positively correlated with intelligence. That's why Gemma-4-31B is able to compete with Mixture of Experts (MoEs) 10 times their size.
2. Mixture of Expert models - Fast and Efficient
Example: Deepseek-V4-Flash / Qwen3.5-397B
What it means:
- when a prompt is sent it's tokenised
- it's sent to a router
- a router was trained to match prompts with experts
- experts are sub-networks of the model
- when found the experts are activated
- tokens are generated with only a fraction of the params
For example: Deepseek-v4-flash has 284 billion params 11x larger than the dense Qwen3.6-27b.
But only 13B of those 284B will activate per token, which is less than half of the size of Qwen3.6-27B
----
Dense Pros:
- Dense models are easier to train
- They tend to be smaller overall
- They can be very smart per token
Dense Cons:
- Competitive dense models are on average slower than their MoE peers.
- Less parameters to train and specialise.
MoE Pros:
- Can be much larger and be trained longer
- Faster token generation
MoE Cons:
- Larger vram requirements
- Harder to train
--------
Lmk if there's anything i'm wrong with or missing
PECAH TELUR BANGGGG☺️
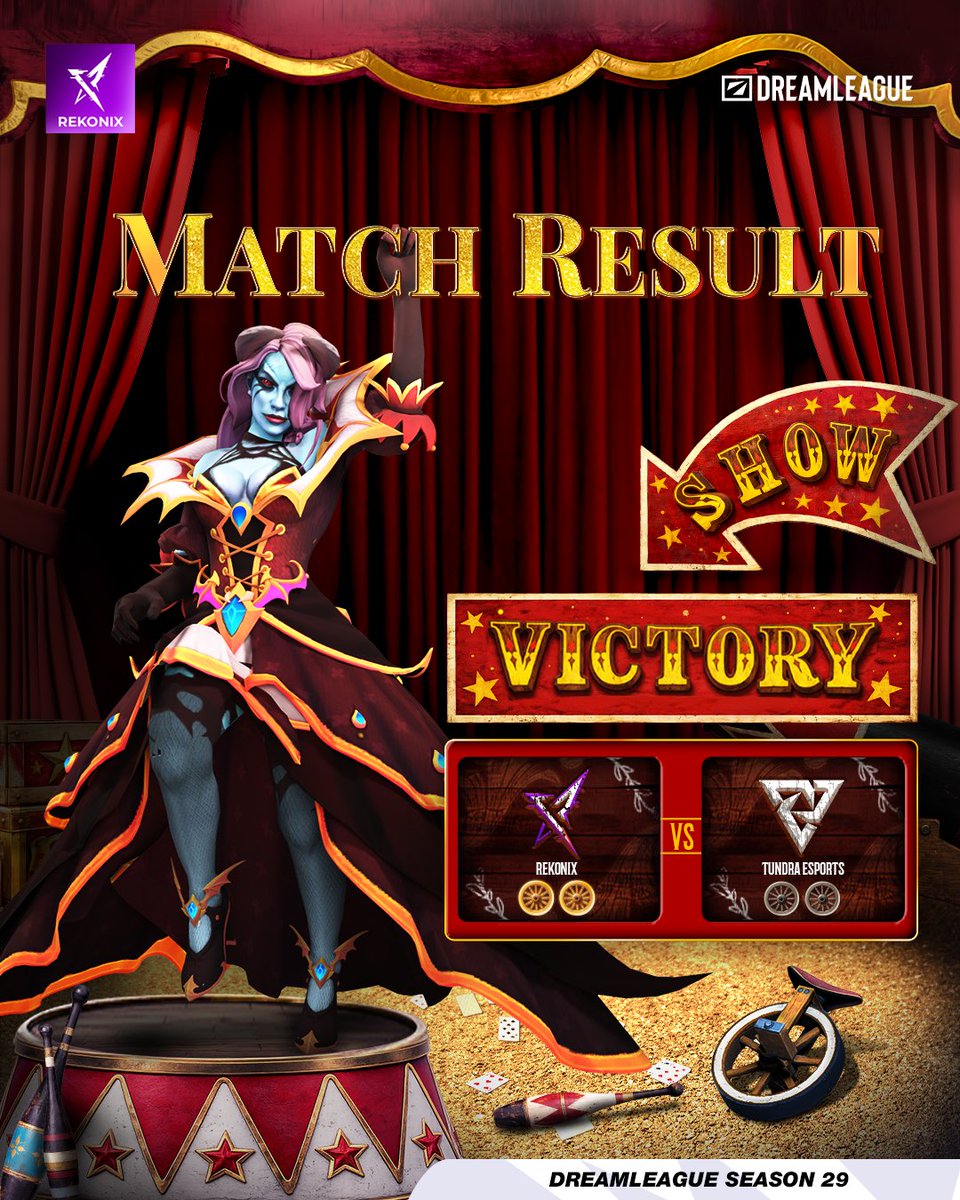
Semoga kemenangan kali ini dapat membawa kemenangan-kemenangan berikutnya, Good Game Well Played @TundraEsports
.
.
Let’s make Dota Indo great again — the REKONIX way 💜⚡
#GGRKX#REKONIX
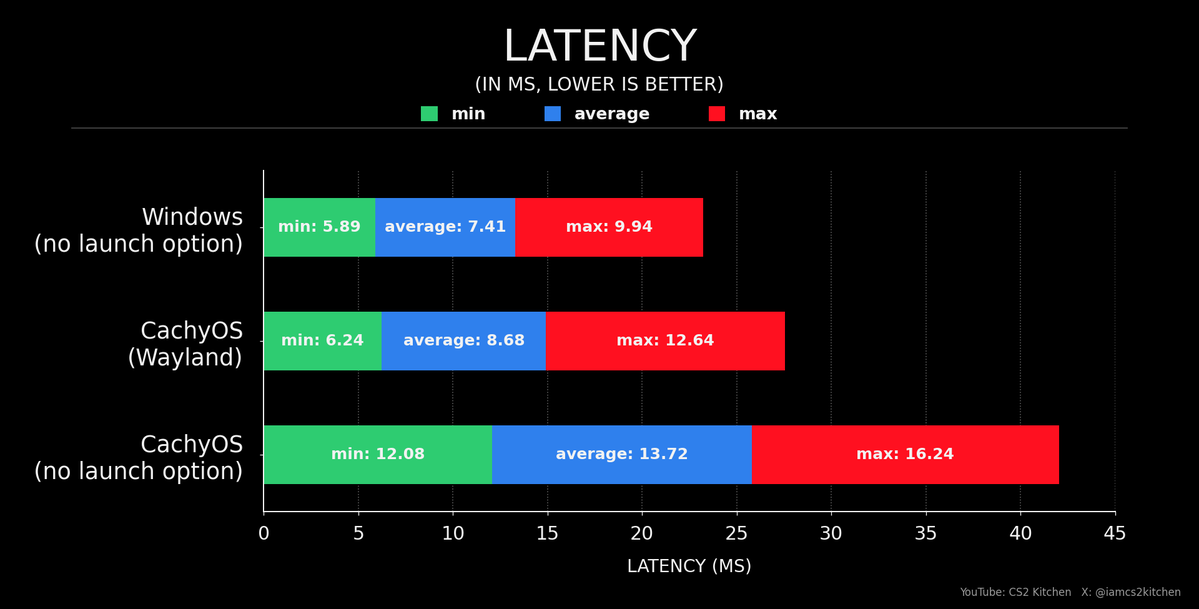
You can get close to Windows Input Latency in @CounterStrike by forcing WayLand Display Protocol for CachyOS. This is good news for Linux users as on default settings you are screwed with way extra latency. Shoutout to @girlglock_ for pointing this out.
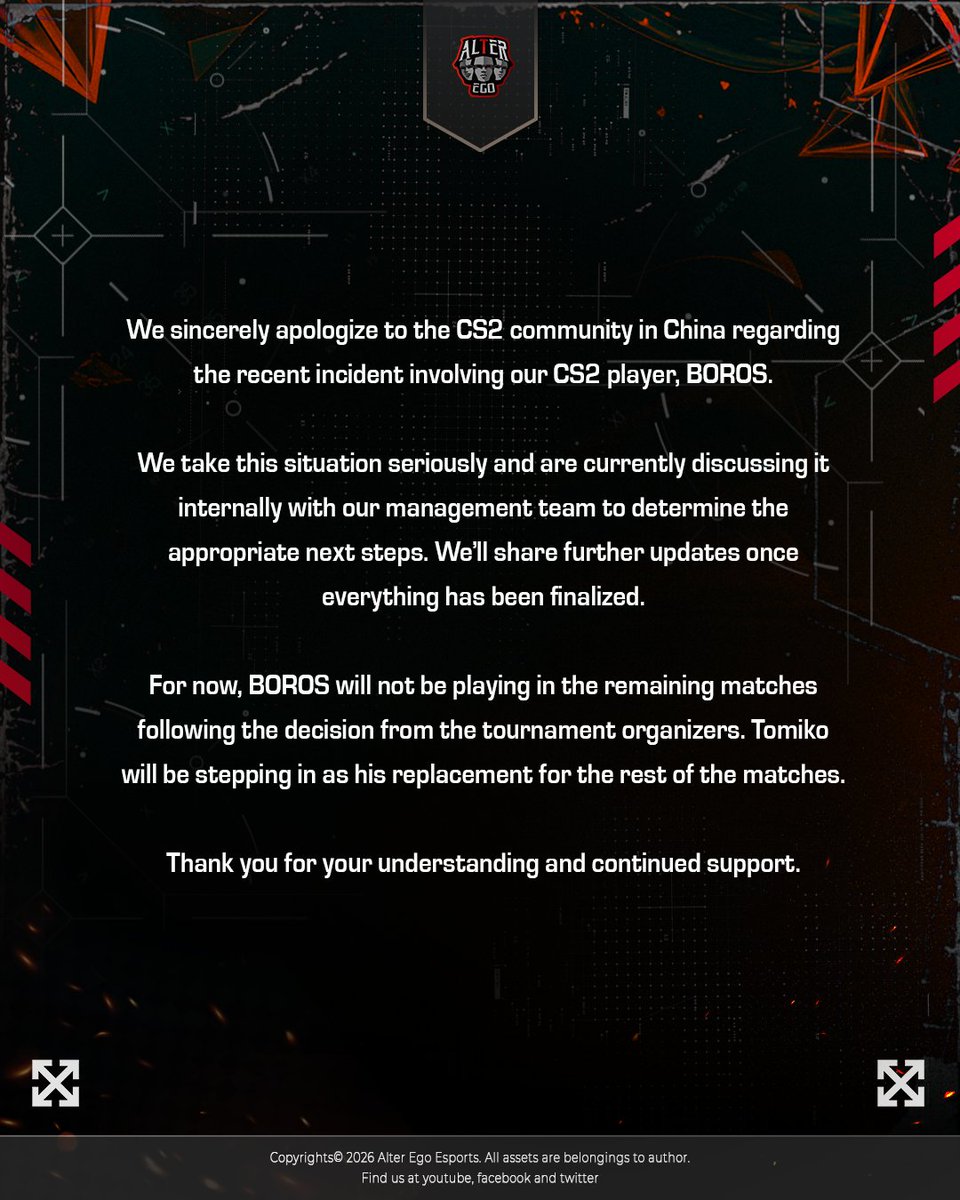
BOROS's teammate Polbandana on why he was really banned from playing ACL ‼️
> According to him, the video going viral isn't the reason... he allegedly "repeated the joke" in front of a tournament admin
We are aware of the situation involving Boros. The matter is currently under internal review, and appropriate actions will be taken accordingly. 🙏
#CS2