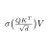It has not been reported much, but I believe ETH Zurich has, as of last week, banned new Master and PhD students who attended a long list of universities in China, Russia, and Iran. 🧵
Fixed a bug which caused all training losses to diverge for large gradient accumulation sizes.
1. First reported by @bnjmn_marie, GA is supposed to be mathematically equivalent to full batch training, but losses did not match.
2. We reproed the issue, and further investigation showed the L2 Norm betw bsz=16 and ga=16 was 10x larger.
3. The culprit was the cross entropy loss normalizer.
4. We ran training runs with denormalized CE Loss, and all training losses match.
5. We then re-normalized CE Loss with the correct denominator across all gradient accumulation steps, and verified all training loss curves match now.
6. We've already updated @UnslothAI with the fix, and wrote up more details in our blog post here: https://t.co/VdUkKN8dsB
This issue impacts all libraries which use GA, and simple averaging of GA does not work for varying sequence lengths.
This also impacts DDP and multi GPU training which accumulates gradients. Please update Unsloth via pip install --upgrade --no-cache-dir unsloth and use from unsloth import unsloth_train
We have a Colab notebook using our fixed GA: https://t.co/1j3kxuD4mb and a Kaggle notebook: https://t.co/LVJPtOqSPw
We put OpenAI o1 to the test against ARC Prize.
Results: both o1 models beat GPT-4o. And o1-preview is on par with Claude 3.5 Sonnet.
Can chain-of-thought scale to AGI? What explains o1's modest scores on ARC-AGI?
Our notes:
https://t.co/sV6LM1foGx
Mario Draghi's new report on EU competitiveness doesn't mince words.
"Across different metrics, a wide gap in GDP has opened up between the EU and the US, driven mainly by a more pronounced slowdown in productivity growth in Europe. Europe’s households have paid the price in foregone living standards. On a per capita basis, real disposable income has grown almost twice as much in the US as in the EU since 2000."
"First – and most importantly – Europe must profoundly refocus its collective efforts on closing the innovation gap with the US and China, especially in advanced technologies. Europe is stuck in a static industrial structure with few new companies rising up to disrupt existing industries or develop new growth engines. In fact, there is no EU company with a market capitalisation over EUR 100 billion that has been set up from scratch in the last fifty years, while all six US companies with a valuation above EUR 1 trillion have been created in this period. This lack of dynamism is self-fulfilling."
"There are not enough academic institutions achieving top levels of excellence and the pipeline from innovation into commercialisation is weak. [...] However, while the EU boasts a strong university system on average, not enough universities and research institutions are at the top. Using volume of publications in top academic science journals as an indicative metric, the EU has only three research institutions ranked among the top 50 globally, whereas the US has 21 and China 15."
"Regulatory barriers to scaling up are particularly onerous in the tech sector, especially for young companies. Regulatory barriers constrain growth in several ways. First, complex and costly procedures across fragmented national systems discourage inventors from filing Intellectual Property Rights (IPRs), hindering young companies from leveraging the Single Market. Second, the EU’s regulatory stance towards tech companies hampers innovation: the EU now has around 100 tech-focused laws and over 270 regulators active in digital networks across all Member States. Many EU laws take a precautionary approach, dictating specific business practices ex ante to avert potential risks ex post. For example, the AI Act imposes additional regulatory requirements on general purpose AI models that exceed a pre-defined threshold of computational power – a threshold which some state-of-the-art models already exceed. Third, digital companies are deterred from doing business across the EU via subsidiaries, as they face heterogeneous requirements, a proliferation of regulatory agencies and “gold plating” of EU legislation by national authorities. Fourth, limitations on data storing and processing create high compliance costs and hinder the creation of large, integrated data sets for training AI models. This fragmentation puts EU companies at a disadvantage relative to the US, which relies on the private sector to build vast data sets, and China, which can leverage its central institutions for data aggregation. This problem is compounded by EU competition enforcement possibly inhibiting intra-industry cooperation. Finally, multiple different national rules in public procurement generate high ongoing costs for cloud providers. The net effect of this burden of regulation is that only larger companies – which are often non-EU based – have the financial capacity and incentive to bear the costs of complying. Young innovative tech companies may choose not to operate in the EU at all."
More: https://t.co/x1d1ApvG2Z.
I usually consider these as "oh, interesting. Since that doesn't look too complicated to implement, let's bookmark this and use this in a project and see if it actually works as well as advertised. (Spoiler: it usually doesn't.)" With DPO itself, you find that it works pretty well but not as well as RLHF+PPO. It's good enough that more people use it than PPO at this point though -- thanks to the added convenience of not having to train a separate reward model.
Now with SimPO, since it's super, super easy to implement, I will actually use it and see what I find. I'll probably add that to the bonus materials for Chapter 7 of my LLMs from Scratch book.
But all that being said, if you wait a few months, you will find follow-up papers where it turns out that the original paper was perhaps too good to be true. E.g., I saw this with DoRA the other day: https://t.co/kMhmdndPES
The OpenAI superalignment team was only one kind of “safety”—the unproven kind.
Meanwhile, there are so many actual harms that require serious thought and research.
If you are panicking because OpenAI stopped caring about “safety”, you’ve probably bought into too much hype.
It's amazing to me that the year is 2024 and some people still equate task-specific skill and intelligence. There is *no* specific task that cannot be solved *without* intelligence -- all you need a sufficiently complete description of the task (removing all test-time novelty and uncertainty), and you can achieve arbitrary levels of skills while entirely by-passing the problem of intelligence. In the limit, even a simple hashtable can be superhuman at anything.
apparently Google laid off their entire Python Foundations team, WTF!
( @SkyLi0n who is one of the pybind11 maintainers just informed me, asking what ways they can re-fund pybind11)
The team seems to have done substantial work that seems critical for Google internally as well.
There's a hackernews thread if folks want to read more: https://t.co/iz6uVNk4Q9
Swiss academics criticise a “major discrepancy” between the resources available and Switzerland’s “ambitious” strategic objectives, which remain unchanged. https://t.co/P9lLv9ff92 @snsf_ch @Innosuisse @CH_universities@ETH_Rat@ETH_en@EPFL
In 2022, we at WIRED told the story of P4x, a hacker who singlehandedly took down the entire North Korean internet.
Now he's revealing his name—Alejandro Caceres—and his strange experience since then: trying to teach the US military to be more like him. https://t.co/urNDXgwzHM
Even in a welfare state like Switzerland more and more people are struggling to find somewhere to live. Most emergency shelters are full. Why? Some homeless people tell their stories. https://t.co/5mgzh4m0P4
Over half of Swiss families are struggling to make ends meet, according to a survey. We’ve interviewed Philippe Gnaegi, director of @ProFamiliaCH, who is now calling for swift political action. 👇
https://t.co/KXeuPDNl7i
Drivers of cars by General Motors, Kia, Subaru and Mitsubishi may not realize that their driving data — like when they sped or braked too hard — is being shared with insurance companies. Numerous people have complained about spiking premiums as a result. https://t.co/4cil1HHsCe