New blackboard lecture w @reinerpope
How do chips actually work – starting with basic logic gates, and working up to why GPUs, TPUs, FPGAs, and the human brain each look the way they do.
0:00:00 – Building a multiply-accumulate from logic gates
0:16:20 – Muxes and the cost of data movement
0:25:59 – How systolic arrays work
0:39:00 – Clock cycles and pipeline registers
0:51:40 – FPGAs vs ASICs
1:03:14 – Cache vs scratchpad
1:07:16 – Why CPU cores are much bigger than GPU cores
1:11:49 – Brains vs chips
1:15:22 – A GPU is just a bunch of tiny TPUs
Look up Dwarkesh Podcast on YouTube/Spotify/etc to watch. Enjoy!
Richard Feynman ganó el Nobel de Física y dijo algo que dejó huella:
"La mayoría de personas saben muchas cosas. Pero no saben pensar."
Feynman dio una clase magistral de 1 hora sobre física e imaginación.
Sus 12 lecciones de vida:
1. La imaginación le gana al conocimiento
Creator of C++, Bjarne Stroustrup:
AI-generated code isn't ready — it generates more bugs, more bloat, more security holes, and is nearly impossible to validate
"senior developers are already retiring rather than deal with it"
The problem is that even a small prompt change can shift the entire codebase in unpredictable ways
Instead of watching an hour of Netflix, watch this 2 hour hour Stanford lecture will teach you more about how LLMs like ChatGPT and Claude are built than most people working at top AI companies learn in their entire careers.
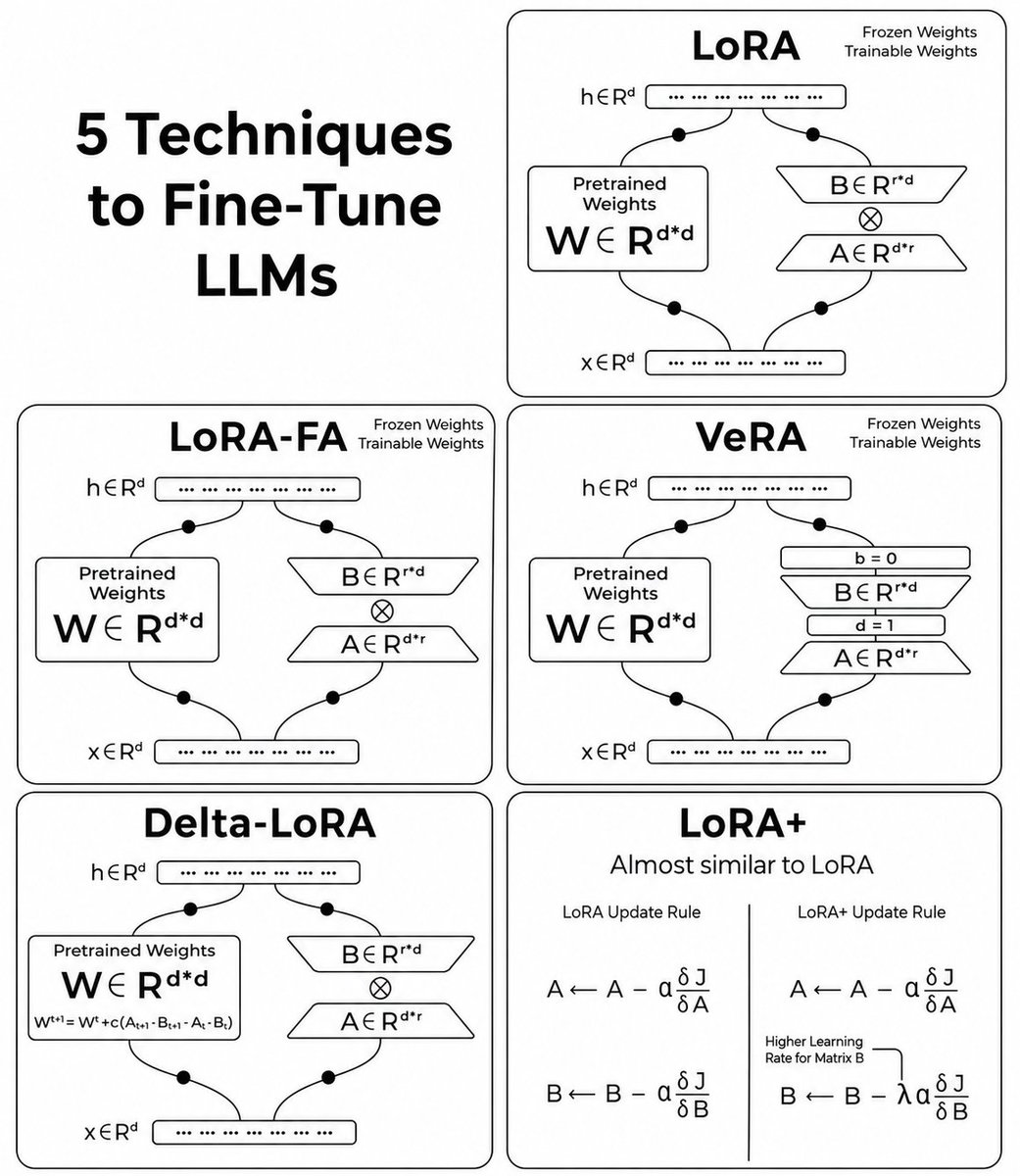
5 Mathematically Efficient Fine-Tuning Techniques for LLMs
This diagram compares the core math behind:
• LoRA – Low-rank decomposition (A ∈ R^{d×r}, B ∈ R^{r×d}) with frozen W
• LoRA-FA – Freezes one low-rank matrix during updates
• VeRA – Vector-based scaling with fixed d=1 and b=0
• Delta-LoRA – Updates pretrained weights using difference of low-rank products
• LoRA+ – Applies asymmetric learning rates to matrices A and B
Clear visual breakdown of weight matrices, dimensions, and update rules for parameter-efficient adaptation.
Linux commands every Infrastructure Engineer runs daily:
uptime → How long has the server been running
df -h → Disk space usage
free -h → Memory usage
top / htop → Live process and resource view
ss -tlnp → Listening ports and processes
journalctl -u <service> -f → Live service logs
systemctl status <service> → Service health
systemctl --failed → All failed services at once
ip a → Network interfaces and IPs
ip r → Routing table
dmesg | tail → Recent kernel messages
last → Recent login history
These 12 commands answer 90% of "what's wrong with this server" questions.
trying to use topological data analysis to map the shape of my x bookmarks through mapper + embedding extraction and generated 3 views:
- density: where attention keeps gravitating
- pca: the dominant axes of variation
- centroid: center vs edge (typical -> outlier)
백준 온라인 저지가 제공하던 3만개 이상의 문제와 채점 데이터에 접근하지 못하게 되면 국내에서 알고리즘 문제 풀이 교육과 관련해 진행되던 모든 것들이 예전 같지 않게 될 것이다.
당장 '스택'을 공부하려고 할 때 BOJ에 있는 한국어로 쓰인 잘 분류된 문제를 줄 수 있었는데 이젠 그럴 수 없다.
리눅스 명령어를 알아야하는 이유:
취업이나 일을 하기 위해서: X
좀비로부터 달아나야하는 포스트아포칼립스 세계에서 좀비가 없는 방이 있는데 방이 잠겨있고 하필 문을 제어하는 컴퓨터에는 깔려있게 딸랑 OS가 아치리눅스 완전 미니멀한 버전과 아주 작은 드라이버 뿐이었다: O
1. 파인만 테크닉은 4단계로 이루어짐.
2. 먼저 공부할 개념명을 백지 맨 위에 쓰고
3. 그 개념을 처음 배우는 아이에게 설명하듯 자신의 말로 써 내려감.
4. 막히는 부분이 나오면 그 지점이 바로 내 지식의 구멍이고
5. 그 부분만 원래 자료로 돌아가 다시 공부한 뒤 보충함.
6. 마지막으로 어려운 용어를 쓰지 않고 비유나 예시로 더 단순하게 만드는 작업을 거치면 개념이 완전히 내 것이 됨.
7. 이 과정을 거친 개념은 오래 기억되고 응용 문제에도 그대로 작동함.
8. 백지 복습법은 파인만 테크닉과 짝을 이루는 방법임.
9. 개념서나 노트를 한 번 읽고 나서 책을 덮고, 방금 읽은 내용을 아무것도 없는 종이에 처음부터 다시 써내려가는 것임.
10. 이때 기억나지 않는 부분이 생기면 그냥 넘기지 않고 표시해둠.
11. 이 과정이 바로 메타인지를 작동시키는 순간인데
12. 내가 뭘 알고 뭘 모르는지를 정확하게 드러내 주기 때문임.
13. 공신들 사이에서 꾸준히 쓰이는 방법이고, 초등 수학 단원 정리에도 그대로 적용 가능함.
14. 개념은 반드시 교과서의 흐름 순서대로 잡아야 함.
15. 특히 수학은 이전 개념이 다음 개념의 토대가 되는 수직적 구조이기 때문에
16. 약수와 배수를 제대로 잡지 못하면 공약수와 최대공약수에서 막히고
17. 통분을 흐릿하게 이해하면 분수의 사칙연산 전체가 불안정해짐.
18. 개념을 건너뛰거나 대충 넘어간 자리는 반드시 나중에 더 큰 구멍이 되어 돌아옴.
19. 교과서 기반으로 흐름을 따라가며 개념을 완성하는 것이 가장 안전하고 탄탄한 루트임.
20.개념을 잡은 뒤 반드시 예제 문제를 풀어봐야 진짜 이해인지 확인이 됨.
21. 개념을 읽고 이해한 것 같아도 막상 문제 앞에 서면 어디서 시작해야 할지 모르는 경우가 많음.
22.이건 개념이 아직 절차적 지식으로 전환되지 않은 상태이기 때문임.
23. 개념 이해 → 개념 설명(백지 또는 구술) → 단순 예제 풀이 → 유형 문제 적용 순서로 이어지는 3단계 확인 과정을 거쳐야 개념이 실전에서도 작동하는 지식이 됨.
24. 개념을 정리할 때 '왜'를 반드시 함께 기록해야 함.
25. 공식이나 규칙을 적을 때 결과만 적지 않고, 그것이 왜 성립하는지 이유를 한 줄이라도 붙여두면 기억이 훨씬 오래감.
26. 예를 들어 최대공약수를 구하는 방법을 적을 때 '공약수 중 가장 큰 수'라는 정의와 함께 왜 소인수분해로 구하면 편한지 이유를 간단하게 옆에 써두는 것임.
27. 이렇게 이유와 함께 기억된 개념은 변형 문제나 서술형에서도 흔들리지 않음.
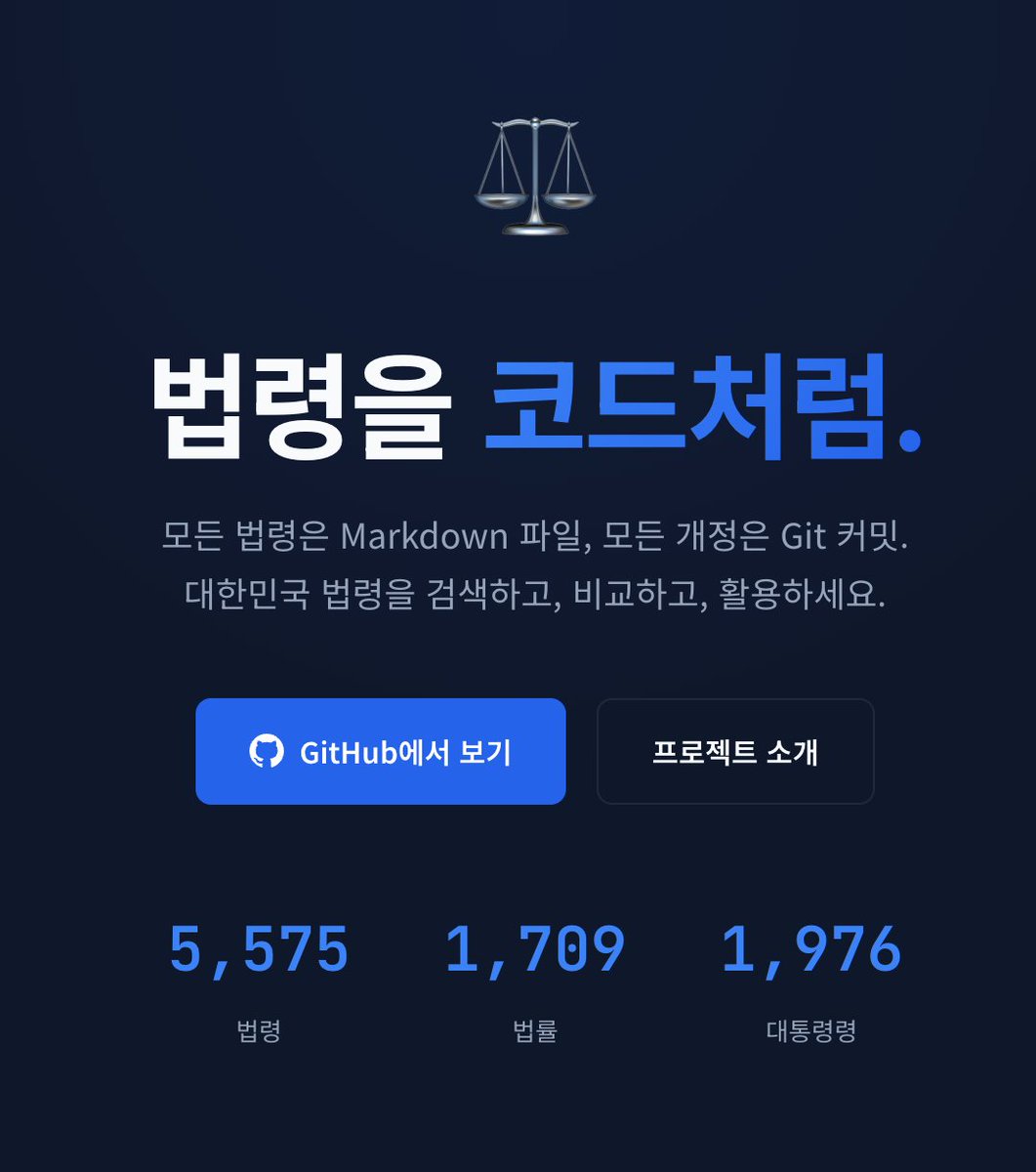
https://t.co/a6AtAxywyN
@junghwan 님께서 한국 법을 모두 git repo로 옮겨주셨다! 한국법령정보 MCP보다 얘가 훨씬 빠르고 편하다!!!!
코드 : https://t.co/l8JqMuHfV9
이거 예전부터 하고싶었지만 은근히 까다로운 처리가 필요해서 미뤘던건데, 시간지나니 다 해주셨다 와와와와
MiroFish 라고 하는 다중 AI 에이전트 기반 미래 예측 시뮬레이터가 높은 정확도로 큰 반향을 얻고 있습니다:
https://t.co/yzGEaUG6Xg
- 중국의 한 대학생이 10일 동안 바이브 코딩으로 만듦
- 다중 에이전트 기술로 구동되는 AI 예측 엔진
- 뉴스, 정부 정책, 금융 신호와 같은 현실 세계의 정보를 시드로 하여
- 수 천개의 에이전트가 존재하는 '평행 우주' 를 구축
- 각 에이전트는 독립적인 성격, 장기 기억 및 행동 논리를 가지고
- 에이전트간 동적 상호 작용을 통해 사회적 진화가 진행
- 이를 통해 금융, 사회 이슈, 비지니스 의사 결정 등의 결과를 높은 정밀도로 예측
지금까지의 과거 데이터 기반이 아닌, 동적 상호작용을 통한 미래 예측이 큰 차이점입니다.
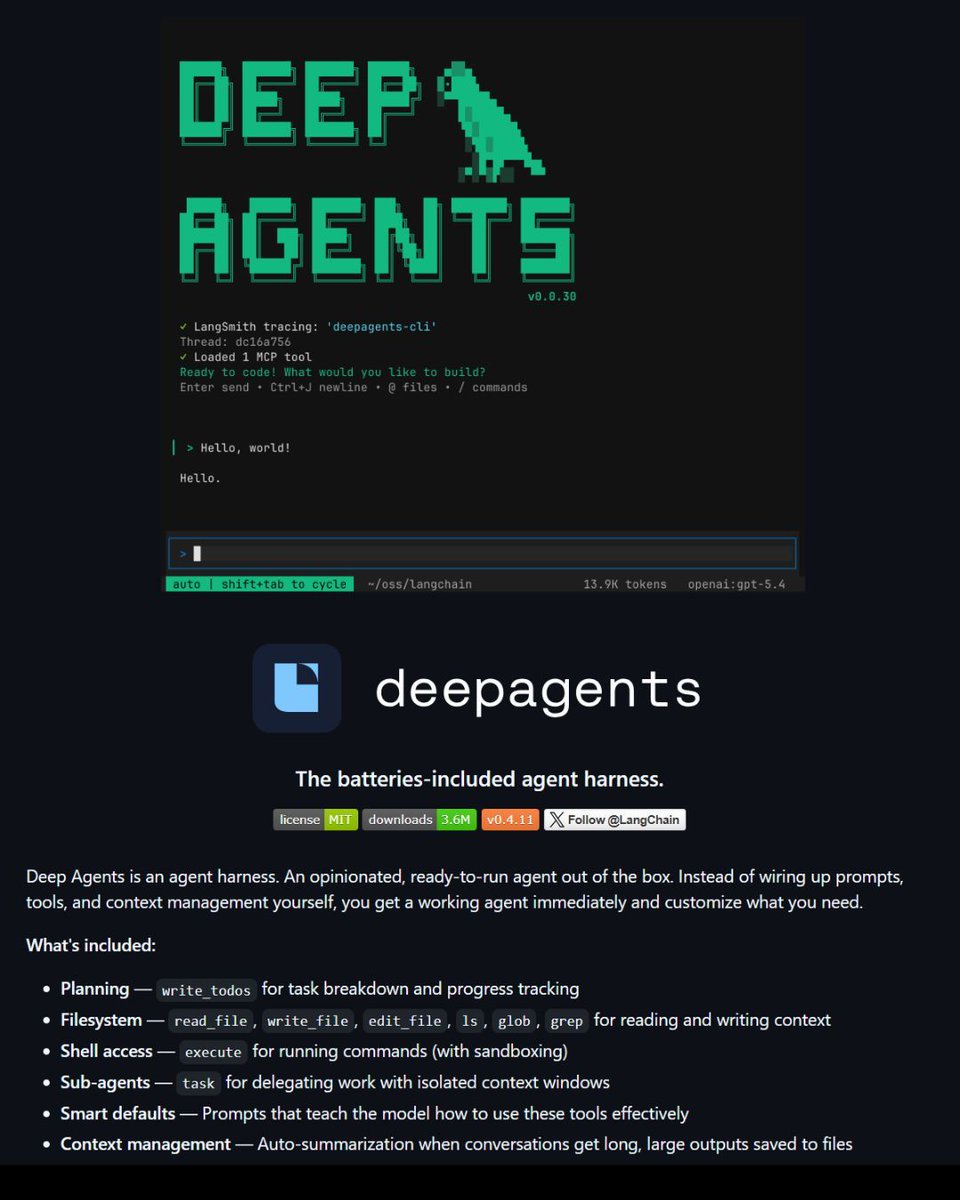
LangChain just open-sourced a replica of Claude Code.
It’s an MIT-licensed framework that recreates the core workflow behind coding agents like Claude Code but in an open system developers can inspect and modify.
It is called Deep Agents.
I spent a bit of time looking through the repo and it’s actually a pretty helpful reference if you’re trying to understand how these coding agents are structured.
Here's what's inside:
→ Planning tools for breaking down tasks
→ File system access for reading, writing, and editing code
→ Shell command execution with sandboxing
→ Sub-agents for handling complex work in parallel
→ Auto-summarization when context gets too long
Another useful aspect is that it’s model-agnostic, so you can plug in different LLMs and experiment with building your own coding agents on top of the same structure.
If you’re exploring agent frameworks or just curious how tools like Claude Code work under the hood, this is a pretty good repo to bookmark.
Link in the comments.
[엔비디아 인턴에서 업스테이지 부사장까지 오른 손해인님]
코딩이라고는 거리가 멀었던 아주대 경영학과 출신
1. 입학과 동시에 빡세기로 유명한 경영학과 마케팅 소학회(RPM)에 들어감. 4학년 1학기까지 쉬지 않고 프로젝트를 하면서 취업준비. 그러나 내가 뭘 좋아하고 잘하는지 어떤 사람인지 모르겠다는 고민에 빠짐.
무작정 프랑스 배낭여행을 떠남. 답은 못찾았지만 프랑스가 좋아 젱 비지니스 스쿨 1학기 교환학생을 다녀옴. 그리고 1년 더 머무름.
2. 여전히 답을 찾지 못하고 자소서를 쓰며 취업준비에 돌임. 시중은행 한 곳에 합격. 그러나 독취사 모범답안을 외웠을 뿐 진짜 자신은 없다고 생각. 취업포기. 3년을 나에게 시간을 주자고 다짐. 어떤 선택이든 돈을 우선순위에 놓지 않기로 함.
3. 첫 직장은 최저시급도 안되는 월 70만원 비영리재단 인턴. 온갖 잡무를 맡다가 홈페이지를 만드는 일을 맡음. 문과생이라 아무것도 모르고 멘땅에서 시작. 다행히 이 재단을 만든 분이 당시 이용덕 엔비디아 지사장에게 도와달라 부탁. 그분을 도움을 받아 월급은 적지만 밤낮, 주말 안가리고 열심히 일했음. 그러다 이런 모습을 좋게 여긴 엔비디아 지사장이 엔비디아 코리아 인턴 제안을 함.
4. 2015년 엔비디아는 그렇게 유명한 회사가 아니었음. 뭐하는 곳인지도 잘모르고 경영 출신이고 예술 경영을 하고 싶어서 처음에는 거절.
그러나 한 번도 생각해보지 않은 분야라고 거절 하는건 원래의 목표와 어긋나는 결정이라는 것을 깨달음. 다시 한 번만 기회를 달라고 부탁. 인턴 채용과정을 밟고 인턴 진행.
























![mindmoon_108's tweet photo. [엔비디아 인턴에서 업스테이지 부사장까지 오른 손해인님]
코딩이라고는 거리가 멀었던 아주대 경영학과 출신
1. 입학과 동시에 빡세기로 유명한 경영학과 마케팅 소학회(RPM)에 들어감. 4학년 1학기까지 쉬지 않고 프로젝트를 하면서 취업준비. 그러나 내가 뭘 좋아하고 잘하는지 어떤 사람인지 모르겠다는 고민에 빠짐.
무작정 프랑스 배낭여행을 떠남. 답은 못찾았지만 프랑스가 좋아 젱 비지니스 스쿨 1학기 교환학생을 다녀옴. 그리고 1년 더 머무름.
2. 여전히 답을 찾지 못하고 자소서를 쓰며 취업준비에 돌임. 시중은행 한 곳에 합격. 그러나 독취사 모범답안을 외웠을 뿐 진짜 자신은 없다고 생각. 취업포기. 3년을 나에게 시간을 주자고 다짐. 어떤 선택이든 돈을 우선순위에 놓지 않기로 함.
3. 첫 직장은 최저시급도 안되는 월 70만원 비영리재단 인턴. 온갖 잡무를 맡다가 홈페이지를 만드는 일을 맡음. 문과생이라 아무것도 모르고 멘땅에서 시작. 다행히 이 재단을 만든 분이 당시 이용덕 엔비디아 지사장에게 도와달라 부탁. 그분을 도움을 받아 월급은 적지만 밤낮, 주말 안가리고 열심히 일했음. 그러다 이런 모습을 좋게 여긴 엔비디아 지사장이 엔비디아 코리아 인턴 제안을 함.
4. 2015년 엔비디아는 그렇게 유명한 회사가 아니었음. 뭐하는 곳인지도 잘모르고 경영 출신이고 예술 경영을 하고 싶어서 처음에는 거절.
그러나 한 번도 생각해보지 않은 분야라고 거절 하는건 원래의 목표와 어긋나는 결정이라는 것을 깨달음. 다시 한 번만 기회를 달라고 부탁. 인턴 채용과정을 밟고 인턴 진행.](https://pbs.twimg.com/media/HDNWhgSbQAMFudC.jpg)






























