Database transactions don't get enough love but the ability to execute a bunch of code, change a bunch of data, and only commit it when you've validated the results is going to be so critical in the AI era.
I think I just experienced my first AI assisted interview candidate this week.
For every question there was a sigh followed by a loooong pause. Tons of stalling. Glancing at another screen
Then all the sudden answered the question
Every single question was the same stalling
Alexey said it best:
“We optimize ClickHouse… and then optimize it again… and again.”
https://t.co/AO8W3A0aY7
25.11 keeps that tradition alive
Parallel GROUP BY merges. Projections as true secondary indexes. Faster DISTINCT.
More speed everywhere.
From Modular's blog we learn that Mojo (the new programming language) makes SIMD instructions first class citizens:
"CPUs have special registers and instructions to process multiple bits of data at the same time, known as SIMD (Single Instruction, Multiple Data). But the ergonomics of writing this code has historically been very ugly and difficult to use. These special instructions have been around for many years, but most code is still not optimized for it. When someone works through the complexities and writes a portable SIMD optimized algorithm, it blows the competition out of the water, for example simd_json.
Mojo's primitives are natively designed to be SIMD-first: UInt8 is actually a SIMD[DType.uint8, 1] which is a SIMD of 1 element. There is no performance overhead to represent it this way, but it allows the programmer to easily use it for SIMD optimizations. For example, you can split up text into 64 byte blocks and represent it as SIMD[DType.uint8, 64] then compare it to a single newline character, in order to find the index for every newline. Because the SIMD registers on your machine can calculate operations on 512bits of data at the same time, this will improve the performance for those operations by 64x!"
If you're not a stranger to the world of databases, then you have either read or heard about the Database Internals book by Alex Petrov (@ifesdjeen).
However, what many still don't know is that Alex runs a Discord community where you can continue to advance your knowledge of database internals.
Tomorrow, @FranckPachot and I are joining the group to demonstrate how MVCC (Multi-Version Concurrency Control) works in Postgres and YugabyteDB.
Join us: https://t.co/AwYK68aiqB
@fanatec I’ve enjoyed my DD1 so much over the past 4 years. I’m sad the power supply died. I want to get back to racing and streaming.
How can I purchase a replacement power supply?
Thanks so much in advance for such a great wheel base.
Faster hash maps, binary trees etc. through data layout modification
We investigate how to make faster hash maps, trees, linked lists and vector of pointers by changing their data layout.
https://t.co/6jYp3etxPG
This brilliant technique for handling database queries literally saved Discord.
It helped them store trillions of messages and fetch them without bringing their DB cluster to its knees.
The technique is called Request Coalescing.
And it’s too good to ignore.
But what’s so special about it?
If multiple users are requesting the same row at the same time, why not query the database only once?
This is exactly what Request Coalescing helps us achieve.
Here’s what happens under the hood:
- The first user that makes a request causes a worker task to spin up in the data service
- Subsequent requests for the same data will check for the existence of that task and subscribe to it
- Once the initial worker task queries the database and gets the result, it will return the row to all subscribers at the same time.
There are several pros to using Request Coalescing:
- Efficient utilization of database resources
- Ability to handle more concurrent requests without creating hot partitions
- Reduce latency
But there are some cons as well:
- Implementation can be complex with regards to getting a fair distributed reader-write lock. Basically, multiple readers need to access the data simultaneously while preventing conflicting writes
- Overall latency may go down, but certain requests will take more time
Of course, this technique is NOT needed normally.
But at a certain scale, it can actually save your business.
===
That’s all for now!
If you enjoyed this post, don’t forget to:
- Destroy the LIKE button
- REPOST so that everyone can try Request Coalescing wherever applicable.
- BOOKMARK for future reference
- Follow me for more posts like this.
We’ve been working on end-to-end flow control for quorum-replicated writes + LSMs in CockroachDB; it’s all very dapper. Tried writing about it here:
https://t.co/NXx1v8TNEr
With today’s release of @PostgreSQL v16 I wanted share how important the logical replication changes are to change data capture (CDC) pipelines like the ones used with @debezium.
Using CDC with PG16 drastically reduces risk to your primary instances!
https://t.co/T0SjPPwq8d
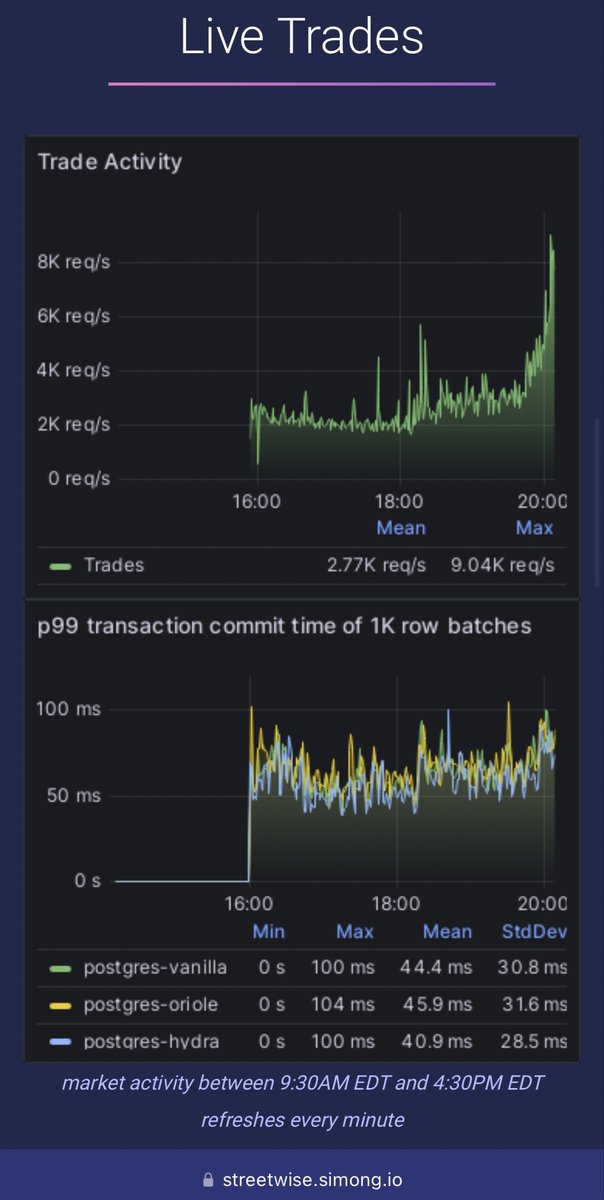
I’m excited to share I’ve launched Streetwise - a live 24/7 benchmark processing real time stock market trades that fans out to 3 flavours of Postgres and measures each.
Running @PostgreSQL and the exciting new @orioledb and @hydradatabase
https://t.co/p3Jm8m41Cs
so tiktok took Clickhouse engine and used a snowflake inspired architecture to build a state of the art Cloud DWH for internal use and recently made it open source !!! this is wild :)
https://t.co/Kzuv46YN5Z