⏰Do you want to learn how to use @skrub_data
like a pro ? Accelerate your practice !
🏆Registration an introductory course on skrub aimed at IT personnel, engineers, data scientists, and data analysts
👉https://t.co/2VHksjSoFD
#DataScience#DataDriven#Innovation
Day 5 of using @skrub_data
Back with more skrub nuggets :). The more I read the docs, the more useful things I find. Data cleaning is not the fun part, but it is a core part of any data science pipeline. skrub makes it a lot easier.
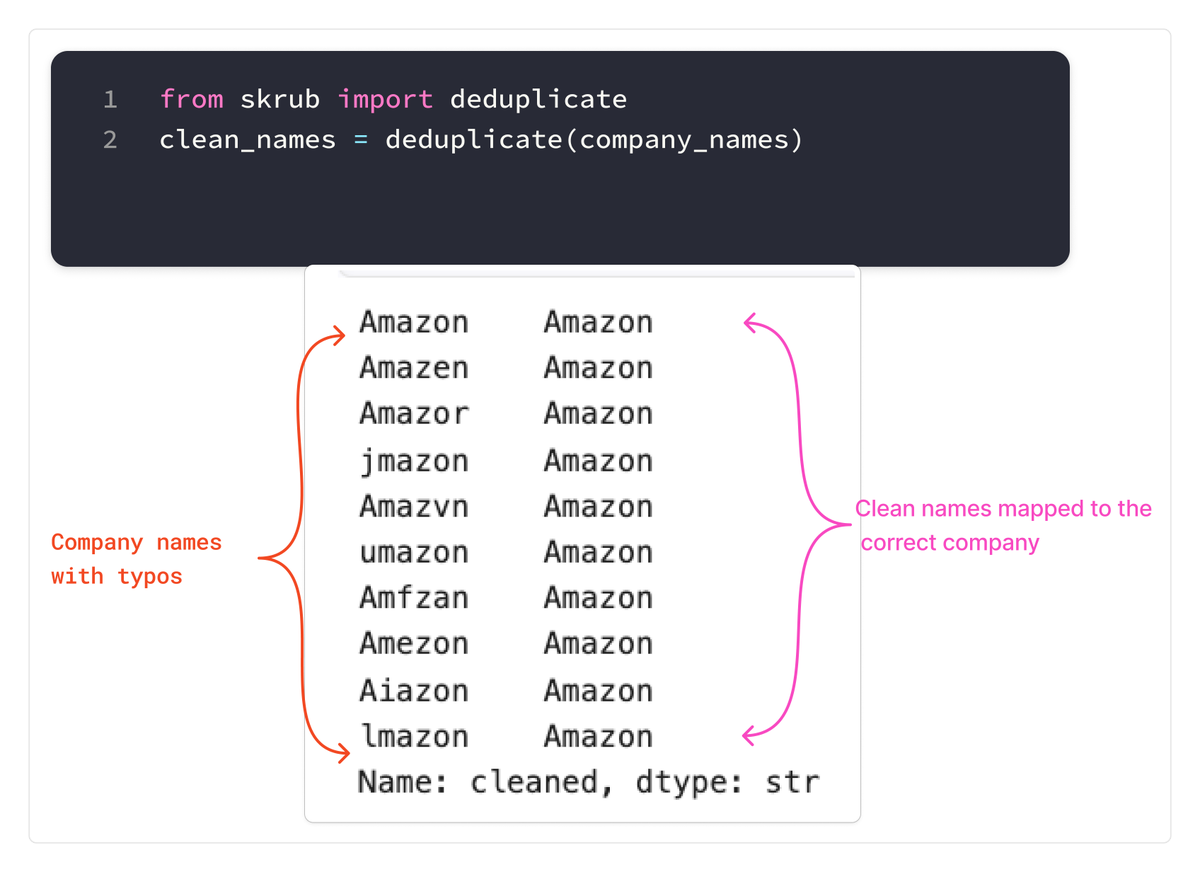
In this post we'll see how to Deduplicate categorical data with skrub
Real-world category columns often contain the same value written in slightly different ways.
For example, company names might show up with small typos:
Amazon, Amazn, Amaozn, Aamazon
skrub has a built-in deduplicate() function for this. It looks for similar strings, groups close variants together, and maps them back to a cleaner category.
This helps when categorical data has spelling errors, duplicate labels, or manual entries that should be treated as one category, especially when you know the correct values or when string similarity does not matter for the task.
Day 4 of using the @skrub_data , very useful library from @probabl_ai if you work with tabular data.
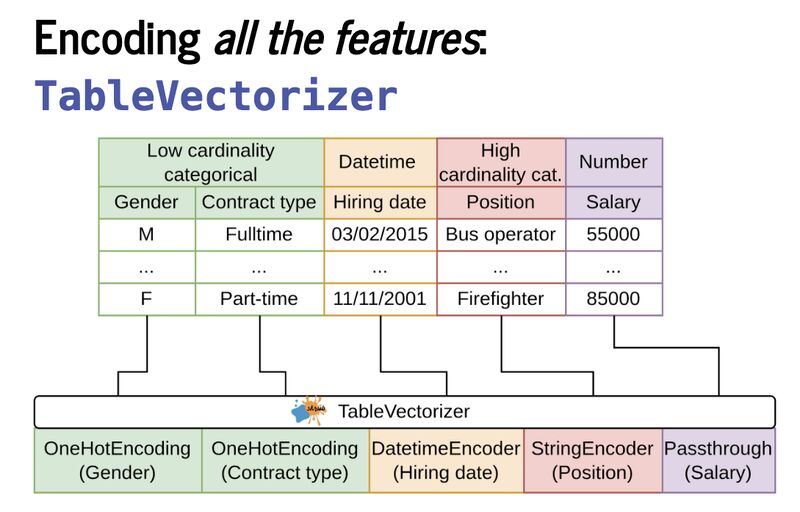
• Encoding features with TableVectorizer to make them model-ready.
Tabular ML models only understand numbers, so strings and categories all need to be converted before training. TableVectorizer handles this end-to-end.
Under the hood:
✅ Data is cleaned to enforce consistent numerical dtypes
✅ Columns are split by dtype and number of unique values
✅ Each column is encoded separately, with categorical features handled differently based on their cardinality
🌟 It's still customizable as you can drop or passthrough columns, or override the defaults entirely.
I have been playing with the @skrub_data package lately and its TableReport feature is quite useful for quickly understanding a dataframe.
You pass in a dataframe and get a clean view with stats, distributions and column relationships in one place.
You can also filter columns by type or missing values and even export it as a simple HTML file to share.
And yes it works in @marimo_io notebooks too 😀
Day 2 of using @skrub_data : Cleaning dataframes with good defaults.
Cleaning the dataframe is usually the first step in any data science pipeline but is also quite repetitive and cumbersome. The Cleaner from skrub handles messy data pretty well and gives you strong defaults to start with. You can always adjust later if needed.
For example, here is a small dataset with some obvious issues like columns with all missing values, string dates and columns that don’t really help.
The Cleaner does this in one go. It scans each column and:
✅ Turns common “fake nulls” like empty strings into actual nulls
✅ Drops columns that don’t add information (like all missing or constant ones)
✅ Parses dates properly instead of leaving them as strings
✅ Keeps categories consistent and
✅ Converts columns to the most meaningful dtype
So instead of writing small fixes everywhere, you get a clean starting point. Great addition to any data processing pipeline.
One of my collaborator sending me a @skrub_data TableReport as an HTML file, with which I can interact, and explore the data, to give him feedback.
Ideal workflow, as far as I am concerned: async, yet interactive, and not needing an infrastructure
With skore v0.10, you now have a data accessor in the EstimatorReport! It consists in a @skrub_data TableReport that allows you to interactively explore your data and gain precious insights before your modelling!
🎬 Check out our short demo video: https://t.co/AtWrfJ5edl
(Re)-watch our session at @PyData Milan in March 2025 where we discussed the latest developments in the @scikit_learn ecosystem: https://t.co/wsb8Lfpvhf
We explore what scikit-learn allows you to do and introduce powerful tools like @skrub_data, skops, and skore.
@PyData@scikit_learn@skrub_data Timeline:
0:00: Intro of PyData Milan
7:30: Presentations of speakers
9:25: What scikit-learn allows you to do
21:15: skrub - less wrangling, more machine learning
32:54: skops - scikit-learn models in production
43:51: skore - an abstraction to ease data science projects
🎤 Next week, our product engineer Marie Sacksick will be presenting how to extend scikit-learn with skore, but also with skrub and skops. Thanks Pyladies Paris for this opportunity!
To book your seat: https://t.co/I7xTLqSOFV
For this recipe, you will need:
- 4 open source libraries,
- 3 vibrant colors,
- 2 enthusiastic speakers,
- 1 welcoming host,
Mix it all, expose to some Milan's sun, and you will get... a talk on @scikit_learn, @skrub_data, skops, and skore, by @glemaitre58 and @MarieSacksick.
🎉⚡️Release 0.5.1:
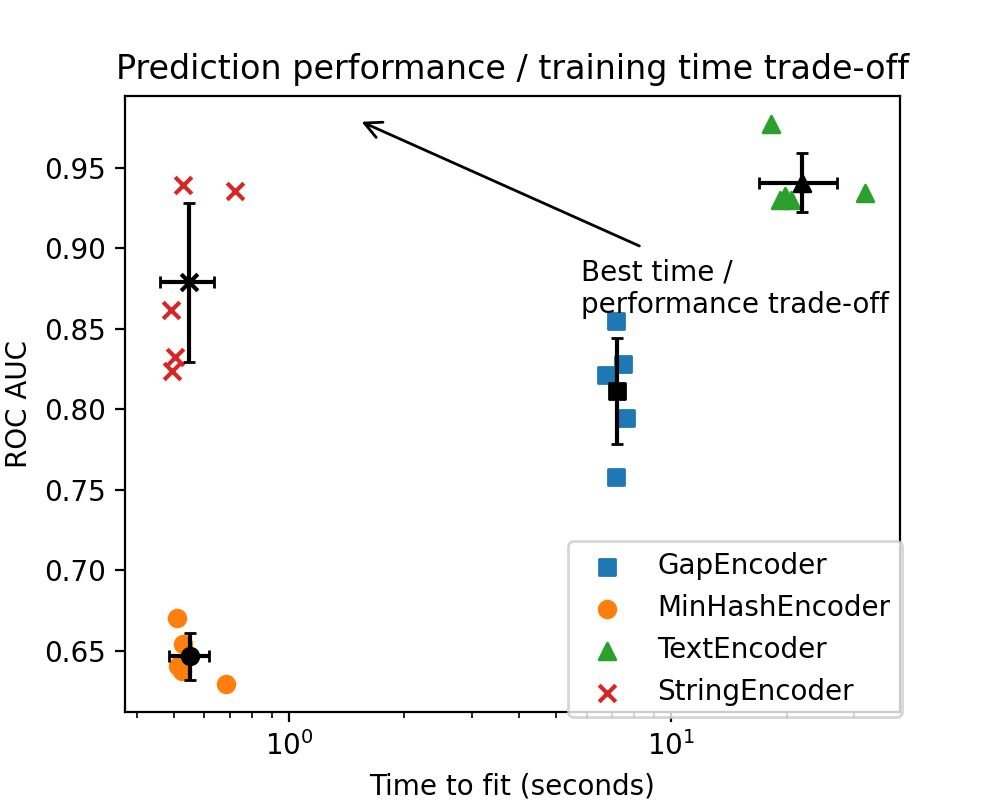
◼ Encode strings faster and better with StringEncoder!
StringEncoder applies a tf-idf vectorization followed by SVD to produce high quality and FAST embeddings of textual and categorical features.
https://t.co/UrPSYc0q6A
There is much more:
skrub.patch_display() adds the TableReport as a default representation for all dataframes
skrub.column_association to check which columns are linked...
Check out the changelog:
https://t.co/N6yF1IjkO3
5/5
🎉⚡️Release 0.4:
◼ Easily use deep learning for text entries
◼ TableVectorizer can remove columns with too many missing values
◼ TableReport more robust and prettier
...
1/5
Improved TableReport:
◼ tighter layout
◼ support any script (any alphabet حب माया) in the plots
◼ robust to outliers
It works without dependencies, in any html-based environment (@ProjectJupyter, @code, a simple web page...)
Check it out on https://t.co/qQMGaeNoEh 4/5
Some ensemble models do not support sparse features, but there is a hashing trick (via the MinHashEncoder in skrub!) that totally circumvents that issue for text/dirty category data.
Details/full explainer just went live here:
https://t.co/GN0znQqKkc