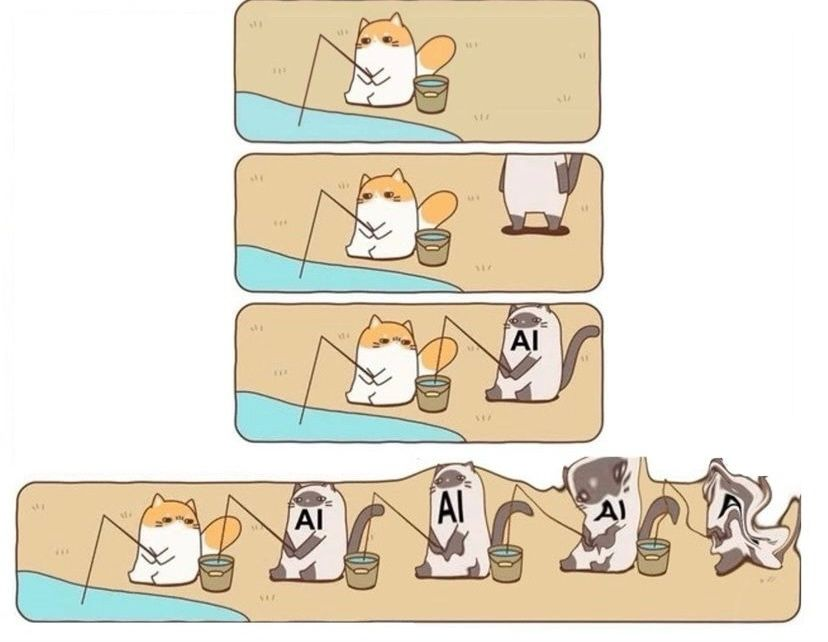
We worry that AI will become Skynet. But the real threat might be far more subtle: What if it simply understands us too well?
We are racing to build digital worlds that are smoother, more engaging, and less friction-filled than reality.
But friction, messiness, and even pain are often where growth happens. They are the crucibles of human resilience. If we engineer away the struggle, do we also engineer away our humanity?
This isn't just a sci-fi dilemma; it's a product choice we face today.
As we build the next generation of AI and immersive tech, are we empowering users to face reality, or building a gilded cage of gentle illusions?
https://t.co/0MCDDs9siv
Inspired by the recent release of Alibaba's Qwen3-VL, I decided to spend my Thanksgiving break building a "mini" Vision-Language Model (VLM).
I put together a ViT with a small LLM Qwen2.5 1.5B. The result is a model with just under ~2B parameters—small enough to load and run comfortably on my laptop. The training cost is <$20.
This is currently just in the "pre-training" phase. As you can see from the attached image, the grounding, instruction following, and language matching still have a long way to go. But it's a start!
In the spirit of Thanksgiving, I found myself reflecting on two things during this process:
* The power of Open Source: This project wouldn't be possible without the community. I didn't have to train a vision encoder or an LLM from scratch. We are truly standing on the shoulders of giants, and open-source models allow us all to push forward together.
* The evolution of productivity: Without AI coding assistants, building this system would have likely taken me a month. With them, I finished it in just a few days of spare time over the holiday— less than 20 hours, including model, data loader, training, inference, and model training time.
Code is available here: https://t.co/wU6g2R8pXl
With the latest article "From SFT to RLAIF VI: The Double Helix of Data and Eval", this series on “From RL to Post-Training” is finally coming to a close. I initially didn't expect it would span 10 articles (an intro, a 3-part RL-101, and a 6-part post-training) over four months.
I have to be honest: this series is by no means comprehensive. It’s not even a “mind map.” At best, it’s a “travel log”. All the previous articles in this series can be seen from https://t.co/9HKgVsEBOc.
It’s just my attempt to sketch a rough framework for understanding post-training while we’re all in the middle of it. If, after reading this series, you’ve come away with a rough sense of how post-training has evolved and a feel for the ideas driving it, that’s the best I could ask for.
https://t.co/WSRkUE4MtV
Finally got the access of Tinker service from The Thinking Machine Lab with $150 credit. The post-training price is pretty low, looks like I don't need to pay for the service for a while.
The uniqueness of Tinker is that it abstracts away the distributed training headache, and still maximize the customizability and flexibility of the data and algorithm logic for the users.
Tinder is a training platform, so users needs to manually download the weights and handle the inference themselves. I hope it can integrate with some of the inference platform and make model deployment and inference also lightweight.
Something fun to play during the weekend.
Finally spent some time to read the on-policy distillation article from TML (https://t.co/96CuG76ElE).
The idea is great that it lets the student model to rollout and use the teacher to quantify the token distribution using reverse KL divergence.
But, seems this idea is too similar to the ICLR 2024 paper "On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes" and the DAGGER algorithm published in the paper AISTATS 2011 "A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning".
Claude Skills is the RAG Moment for Thinking/Planning.
If RAG externalizes memory, then Skills externalize planning.
LLMs used to plan and act using only their intrinsic knowledge — patterns learned during training. That’s like a smart person relying purely on intuition: capable, but inconsistent.
Then came RAG (Retrieval-Augmented Generation) — which gave models access to external knowledge. It made them more informed, but their thinking process was still internal, opaque, and often ad-hoc.
Now comes Claude’s Skill system, which extends not what the model knows, but how it thinks. A Skill isn’t a plugin or a code executor — it’s a runbook for reasoning. It injects structured, domain-agnostic methodologies into the model’s planning process. Each skill defines how to approach a task: the steps, the reasoning pattern, the workflow.
"The limits of my language mean the limits of my world," Wittgenstein famously stated. For a long time, this was also the fate of AI, its world confined by the discrete, finite vocabulary of tokenization.
But recent work, exemplified by the DeepSeek-OCR paper, signals a profound shift. AI is no longer content with the linguistic cage we've built for it. In my new article, I explore the two fascinating paths AI is taking to break these boundaries:
The Path of Transcendence (DeepSeek-OCR, Continuous Latent Space): This route bypasses language altogether, operating in a continuous, pre-linguistic space of vision and thought. It's escaping the limits of language by choosing to "see" rather than "say."
The Path of Reformation (VQ-VAE): This path embraces discrete symbols but rejects the inefficiency of human language. It empowers AI to invent its own, more optimal, native symbolic system directly from data. It's redefining its world by creating a new language for it.
https://t.co/PeYzb2POXz
The key takeaway from the DeepSeek-V3.2 paper is clear: its inference cost barely increases with input length. While other models see costs soar linearly, V3.2's cost curve remains nearly flat even at 128K tokens, making true long-context applications economically viable.
What struck me most beyond this incredible efficiency wasn't just the "how," but the "why" behind their approach.
The belows are just my personal conjecture, but I believe their thought process reflects a major trend in LLM architecture.
A year ago, the paradigm shift was Mixture-of-Experts (MoE), turning dense models sparse. We saw it evolve from models with a handful of experts, like Mixtral 8x7B, to architectures with a vast number of them (e.g. snowflake arctic with 128 experts). The clear trend was making feed-forward layers sparse to scale up model size efficiently.
Now, with DeepSeek-V3.2, it seems this "sparsity wave" is hitting the attention mechanism. They've essentially applied the MoE principle—using a cheap router to activate a fraction of a larger system—to the attention layer itself. Their "lightning indexer" acts as the router, selecting the most relevant tokens before the expensive attention calculation.
The current paper presents this as an "experimental" model, created by grafting sparse attention onto the existing DeepSeek-V3.1 with continued pre-training.
This leads me to a further prediction: their next flagship version won't be a hybrid. I think they may build it natively with sparse attention from the ground up. It feels like the logical and exciting next step.
I often wonder why so many engineering interviews still revolve around testing memorization—whether it's LeetCode puzzles or framework-specific trivia. It feels like we're using yesterday's map to find tomorrow's navigators.
The LeetCode-first approach has always been problematic, and the AI era has only amplified its flaws:
- Poor Proxy for Reality: It's often a poor test for real-world engineering, misaligned with the need for architectural wisdom in complex systems.
- The Automation Problem: In the AI era, this misalignment becomes a critical business issue. Even if a role genuinely required only pure coding execution, an LLM can now perform that task at a fraction of the cost, forcing the question: why hire for an automatable skill?
This new reality forces us to ask a more fundamental question: what is the core value of an engineer? It's no longer about the flawless execution of code. Instead, we must seek out thinkers whose true worth lies in their ability to:
1. Formulate Problems: Translate vague, abstract challenges into concrete, executable plans. This is where true creation begins.
2. Architect with Trade-offs: Design robust systems by making difficult trade-offs based on context and values. There is no perfect solution, only wise compromises.
3. Leverage, Don't Compete: Wisely command tools and resources, including AI, to achieve a goal, rather than having the brute force to compete with tools...
4. Stay Curious and Driven: Possess a strong curiosity for the craft, with an internal drive to explore the unknown. This is the true source of innovation.
When execution is commoditized by AI, these uniquely human skills of judgment and strategy become the differentiator.
In this new era, an engineer leveraging AI is the baseline for a 10x engineer.
AI buzzwords, decoded. Here are the core ideas behind the jargon, with a little less of the hype.
- AI Agent: 95% are prescripted data pipelines with fixed workflow. The other 5% are doing the real work.
- CoT: Ask LLM to expose its thought process, or at least to fake one.
- Reward Modeling: Learning to rank in the LLM-era. It learns from human-ranked examples to create a model that can score and rank any future response.
- RLHF: LLM rollout -> real human provide preference -> LLM learns the "ground truth" of that particular annotator.
- RLAIF: Same as the above, but another LLM does the human part.
- RLVF: Same as the above, but tools do the human part, e.g. code runner, pre-defined functions, etc.
- DPO: A direct, rank-aware shortcut that tells the model "rank A over B, no questions asked," attempting to retire the above reward modeling.
- GRPO: Just PPO, but instead of a complex baseline, it simply asks: "Is this better than average?"
30-second summary of paper: Training Large Language Models to Reason in a Continuous Latent Space
This paper introduces COCONUT, a method where an LLM reasons by feeding its own last hidden state back as the next input embedding, instead of decoding it into a language token. This allows the model to perform reasoning in a continuous latent space, enabling a breadth-first-search-like process that outperforms Chain-of-Thought on tasks requiring complex planning.
Paper link: https://t.co/PRTueUlkhV
#AI #LLM #Reasoning #MachineLearning
Just read a paper from DeepSeek-AI on inference-time scaling for reward models. Instead of just making models bigger, they make them "think" more.
TL;DR: They introduce Self-Principled Critique Tuning (SPCT), a method that trains a generative reward model (GRM) to produce its own evaluation principles and critiques. By sampling multiple critiques at inference time and voting, a 27B model can outperform much larger ones.
Key Contributions:
Problem: Reward models often don't improve with more inference compute and lack input flexibility for different query types.
Solution: A pointwise GRM is trained with SPCT (rejective fine-tuning + online RL) to generate adaptive principles and critiques. They scale performance at inference via parallel sampling, voting, and a meta-RM to filter for high-quality generations.
Impact: Their DeepSeek-GRM-27B model with inference-time scaling achieves strong results on RM benchmarks, outperforming models up to 671B.
Why it matters: This presents a more compute-efficient path to powerful, generalist reward models, which are critical for aligning and evaluating the next generation of AI systems.
Kudos to the authors at DeepSeek-AI and Tsinghua University. Paper: https://t.co/ALn4i9v1ox
#AI #DeepLearning #LLM #ReinforcementLearning
How many times have you seen Sam Altman today?
One minute he's dancing in cyberpunk Tokyo, the next he's stealing GPUs on a Mars base. Before the meme fatigue sets in, think about the underlying mechanism.
Sora 2 allowing his likeness isn't a feature. It's the most subtle, large-scale consciousness-seeding operation in history.
It’s not an ad. It’s open-sourcing a human identity as a "narrative primitive," letting millions encode him into our collective subconscious.
This is no longer about personal branding. It's about reality itself becoming a generative asset.
The AI arms race is dominating headlines, with giants spending billions on foundation models. But does every business need to build a nuclear reactor just to power a lightbulb?
For most, the critical question isn't "how to build," but "what to use and why."
This article steps back from the hype to offer a strategic map for applying LLMs. It breaks down the journey from "meal kits" (simple APIs) to "private chefs" (custom fine-tuning), reframing the conversation from a tech race to a clear-eyed choice about ROI. It's about finding the right tool for the job, not just the biggest one.
The link: https://t.co/KdcUisdqQn
From SFT to RLAIF (V): Injecting 'Taste' into AI—Crafting Its Unique Soul
Finished up the 5th piece of the "From SFT to RLAIF" series this weekend.
We've all seen LLMs generate factually correct, yet mediocre responses. This post explores how we teach a model taste—tracing the evolution from SFT's limits to the core ideas of PPO and DPO. It also includes a hands-on case: training a dialogue model with a classic 'dubbed movie' persona, showing how alignment can shape not just correctness, but a unique soul.
My goal remains the same: make complex AI concepts accessible using analogies and first principles, rather than a formula barrage. Hope this series can serve as a 'map' to the terrain, making the technical papers less daunting.
See more: https://t.co/b0YsrqFGTZ
Is the "AI Engineer" simply the Big Data Engineer of a decade ago, but with a new stack? The parallels are getting clearer by the day.
A Decade Ago:
- Debugging YARN memory overflows on Hadoop clusters.
- Optimizing complex Spark SQL joins and shuffle partitions.
- Building real-time streams with Kafka, Storm, or Flink.
- Wrangling terabytes of unstructured data with MapReduce.
Today:
- Debugging non-deterministic outputs from prompt chains.
- Optimizing RAG recall rates and chunking strategies.
- Integrating tools and APIs for Agents via function calling.
- Wrangling embedding models and vector database indexes.
The fundamental task remains: orchestrating a complex, distributed system of powerful but unruly components to deliver a novel capability. We've traded the challenges of data distribution for the quirks of model behavior.
Is this a cyclical return of the "glue engineer," or are we truly evolving into architects of intelligence?