Qwen-Scope is cool because now you can observe the model.
You ask it a question and instead of only seeing the answer, you can peek at which concepts lit up inside.
We’ve gone beyond “trust me bro” black box models.
• µLMs (8M–30M params) generate the first 4–8 words on-device in ~55 ms
• A cloud LLM then continues the same response seamlessly
• This “commit-and-continue” design masks cloud latency
• Result: near-instant, context-grounded AI on wearables and other constrained devices
🚨 In 2 weeks, a final decision on amendments to the EU AI Act and the GDPR will be made. What is at stake is nothing other than the future of Europe.
Many don't know, but the stream of events leading to this moment began much earlier, with the publication of the Draghi report on European competitiveness in September 2024.
In his long report, Mario Draghi diagnosed various areas in which European competitiveness was lagging behind and suggested that one of the reasons was overregulation and the excessive number of laws governing the digital space.
Laws such as the GDPR and the AI Act were to blame.
Before I continue, here is something many overlook: the Draghi report was finalized in September 2024, while the AI Act was officially enacted one month earlier.
The AI Act had barely been enacted, and it was already considered 'wrong,' excessive, and to blame for Europe's less-than-ideal (to be light) position in the AI race.
From that moment on, the European discourse on the protection of fundamental rights was never the same.
Its narrative shifted, and after that, the new dogma was that the path to innovation would be to "remove the red tape," and "apply the AI Act in a business-friendly way." (whatever that means from a legal perspective).
The AI Action Summit last year made this new narrative loud and clear to the public, as EU officials abandoned fundamental rights-focused statements.
Last year, the narrative shift was legally materialized. The EU published the Digital Omnibus with proposed amendments to some of its most important laws regulating data protection and AI: the GDPR and the AI Act.
Strangely, the main justification for the AI Act's amendments was the designation delays by EU member states and the work delays by EU standardization organizations.
If these were the real reasons, wouldn't it be more coherent to pressure them to move faster, hire more people, increase the budget, or help address the bureaucratic obstacles...?
Does the EU need to amend some of the AI Act’s core obligations because EU bodies are delayed?
I didn't buy it. Given the context, it felt more like a broader political shift.
The time has arrived, and in two weeks, EU officials will meet to make a final decision on the Digital Omnibus and the amendments to the GDPR and the AI Act (among other topics).
As I wrote in my newsletter, several of the proposed amendments weaken AI regulation in the EU and go against the protection of fundamental rights.
If you are European, if you were hopeful for a Brussels Effect in AI, or if you are interested in the protection of fundamental rights, I invite you to read my full article below.
-
���� To learn more:
- Read my article about the Digital Ominibus first draft and join my newsletter's 93,500+ subscribers (link below).
- Join the 29th cohort of my Advanced AI Governance Training. Among the topics I cover in depth are the EU AI Act, the Digital Omnibus, and the European AI strategy (link below).
RAG is broken and nobody's talking about it.
Stanford researchers exposed the fatal flaw killing every "AI that reads your docs" product in existence.
It’s called "Semantic Collapse," and it happens the second your knowledge base hits critical mass. If you've noticed your AI getting "dumber" as you add more data, this is exactly why.
Right now, companies are dumping thousands of documents into their AI, thinking it’s getting smarter.
When you add a document to RAG, it converts it into a high-dimensional vector.
Under 10,000 documents, this works perfectly. Similar concepts cluster together.
But past 10,000 documents, the space fills up. The clusters overlap. The distances compress.
Everything starts to look "relevant."
It is a mathematical law called the Curse of Dimensionality. In a 1000-dimensional space, 99.9% of your data lives on the outer edge. All points become equidistant from each other.
That perfect, relevant document you are looking for now has the exact same mathematical similarity as 50 completely irrelevant ones.
The Stanford findings are brutal:
At 50,000 documents, precision drops by 87%. Semantic search actually becomes worse than old-school keyword search.
Adding more context doesn’t fix the AI. It makes the hallucinations worse.
Your "nearest neighbor" search isn't finding the best answer anymore. It's finding everyone.
We thought RAG solved hallucinations.
It didn't. It just hid them behind math.
The #MLSys2026 program is out, and it is awesome!
📄 107 research papers + 28 industry papers spanning the full AI systems stack
🏆 Three exciting contests: AWS Trainium programming, Google graph scheduling, and NVIDIA AI kernel generation
🎤 Keynotes from an outstanding lineup: Amin Vahdat (Google) on infra; @LukeZettlemoyer (UW & Meta) on models; @kozyraki (Stanford & NVIDIA) on architecture; Lidong Zhou (Microsoft) on systems; and @marksaroufim (GPUMode) on GPUs and kernels.
Join us in Bellevue, WA in a month! Early registration ends April 19 — don’t miss it: https://t.co/trj383wuVB.
🇮🇷🇺🇸📽️ FLASH | « Hello loser. » La propagande iranienne reprend les codes visuels et narratifs américains dans plusieurs clips, comme ici, où elle met en scène la destruction d’une force d’invasion de l’île de Kharg.
1/10 🚀 Qwen3.5-Omni is here! Scaling up to a native omni-modal AGI.
Meet the next generation of Qwen, designed for native text, image, audio, and video understanding, with major advances in both intelligence and real-time interaction.
A standout feature:
Audio-Visual Vibe Coding: Describe your vision to the camera, and Qwen3.5-Omni instantly builds a functional website or game for you.
Highlights:
Script-Level Captioning: Generate detailed video scripts with timestamps, scene cuts & speaker mapping.
SOTA Performance: Qwen3.5-Omni has secured 215 SOTA scores across various sub-tasks, matching the top-tier text/vision capabilities of the Qwen3.5 series.
Audio-Visual Understanding: From auto-segmentation to fine-grained script generation, it understands the relationship between characters and their environment like never before.
Seamless Interaction: With native API support for Semantic Interruption, voice conversations feel human-like and background-noise resistant.
Global Multilingual Mastery: Pioneering support for 74 languages in speech recognition and 29 languages in expressive speech generation, breaking down global communication barriers.
Autonomous Intelligence: Native support for WebSearch and complex Function Calling—the model now independently decides when to pull real-time data.
Qwen3.5-Omni is built to be the backbone of next-gen AI applications, empowering developers and users alike with true multimodal reasoning.
📢 Appel à manifestation d’intérêt pour le test d’un outil d’audit #RGPD des modèles d’#IA.
🧠Lancé par l'ANSSI, la @CNIL, le PEReN et l'@Inria, le projet PANAME vise à développer un outil pour auditer la confidentialité des modèles d’IA.
+ d'infos :
🔗 https://t.co/CvxuaSCqgT
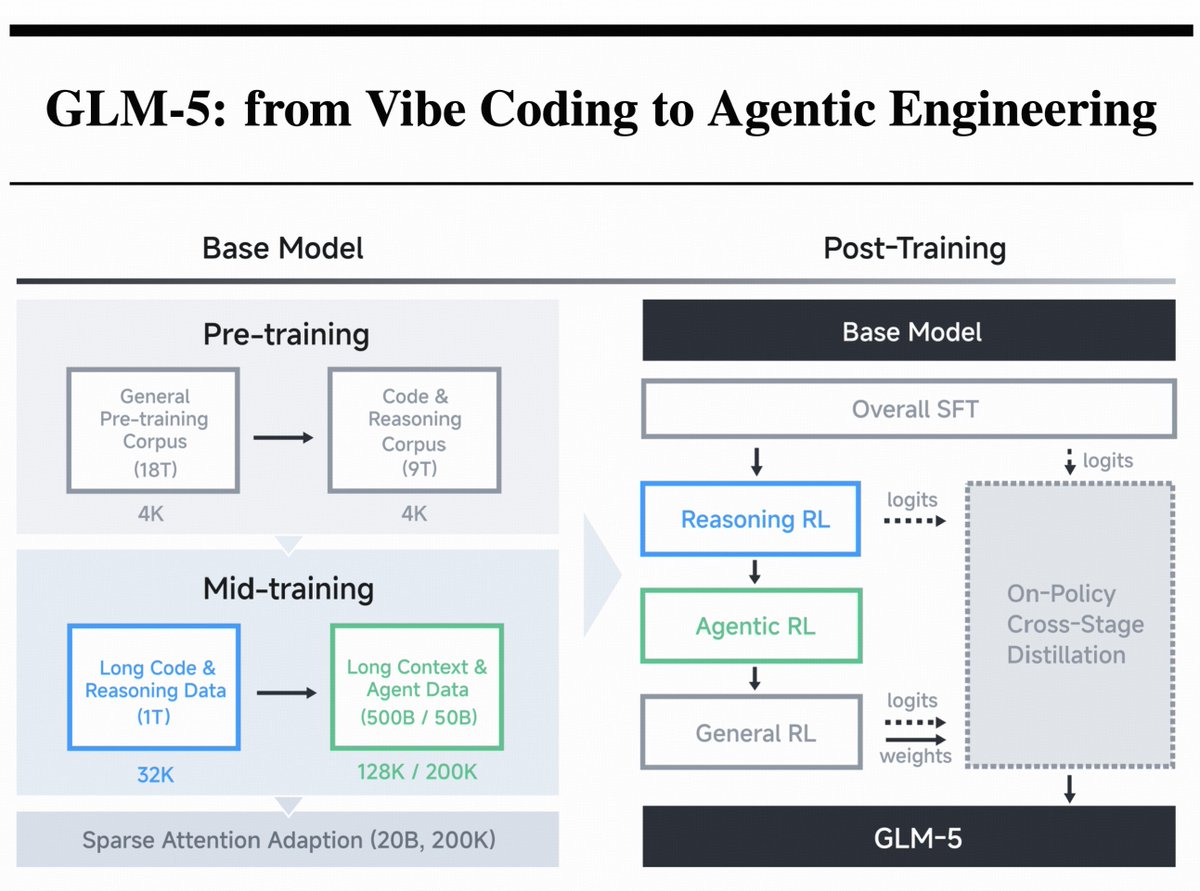
Presenting the GLM-5 Technical Report!
https://t.co/CGjxEISvFK
After the launch of GLM-5, we’re pulling back the curtain on how it was built. Key innovations include:
- DSA Adoption: Significantly reduces training and inference costs while preserving long-context fidelity
- Asynchronous RL Infrastructure: Drastically improves post-training efficiency by decoupling generation from training
- Agent RL Algorithms: Enables the model to learn from complex, long-horizon interactions more effectively
Through these innovations, GLM-5 achieves SOTA performance among open-source models, with particularly strong results in real-world software engineering tasks.
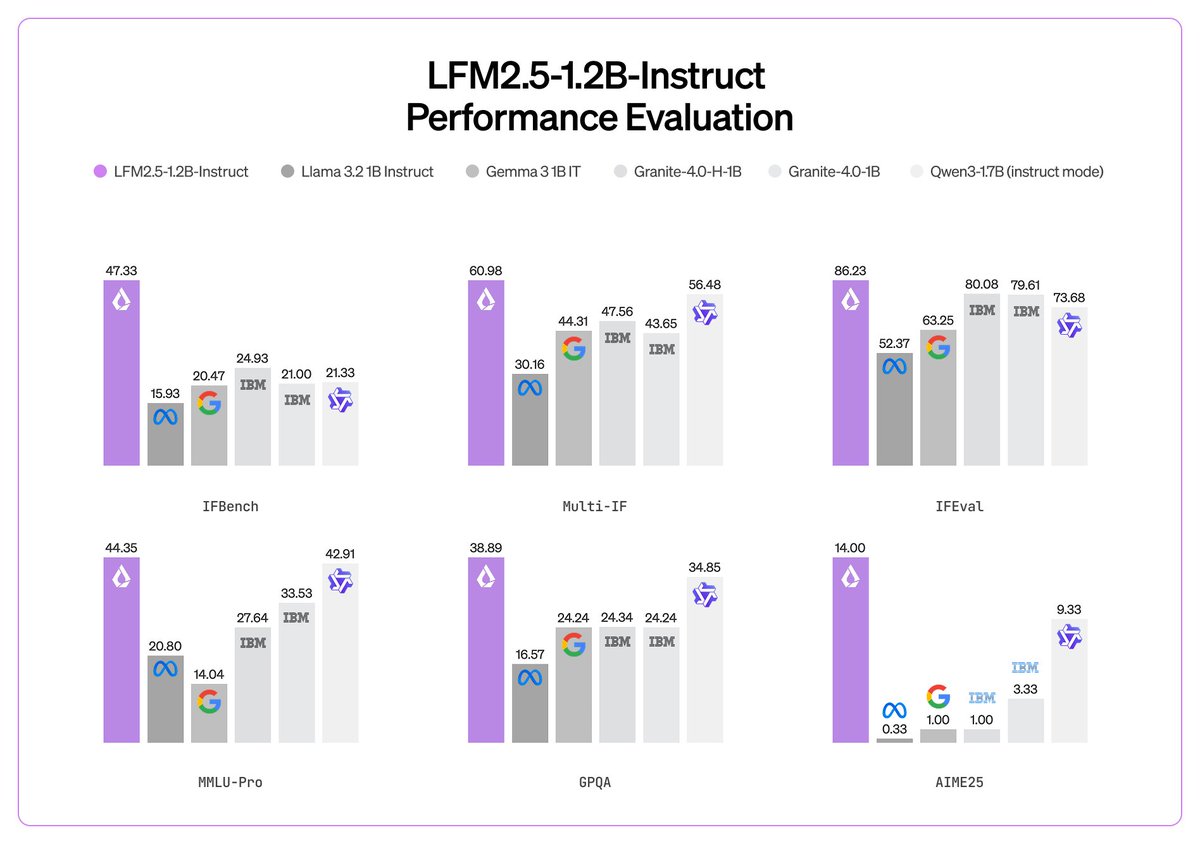
Today, we release LFM2.5, our most capable family of tiny on-device foundation models.
It’s built to power reliable on-device agentic applications: higher quality, lower latency, and broader modality support in the ~1B parameter class.
> LFM2.5 builds on our LFM2 device-optimized hybrid architecture
> Pretraining scaled from 10T → 28T tokens
> Expanded reinforcement learning post-training
> Higher ceilings for instruction following
🧵
La CNIL met à disposition un démonstrateur pour naviguer à travers la généalogie des modèles d’IA publiés en source ouverte et étudier la traçabilité de cet écosystème, notamment pour faciliter l’exercice de droits d’opposition, d’accès ou d’effacement👉https://t.co/g8hcEjVkTP
R.I.P. to the illusion of 'distinction.' Our new framework, Bourdieu Vectors, finally quantifies the exact coordinates of your social class. Your "good taste" is just statistically average for your tax bracket. Ready to see where you really belong?
Thrilled to release our new paper MAP: Measuring Agents in Production ⚙️🚀
2025 is the year of agents… but do they actually work in the real world? Is it just hype?
A group of 25 researchers from Berkeley, Stanford, UIUC, IBM, and Intesa Sanpaolo investigated what makes agents deployable in the wild. So…
📈 Why agents? Productivity gains
➕ How to build production agents? Simple & controllable methods
🧑💻 How to evaluate agents? Heavy human oversight
🛑 Top challenge now? Reliability remains unsolved
We surveyed 306 agent builders and ran 20 in-depth interviews across 26 agent application domains to understand the current landscape of production agents.
Check out our latest paper: MAP - more in the thread 👇
(1/N)
Thanks again all for a wonderful #EMNLP2025! For future reference, you can now find all accepted papers, award winners, and outstanding reviewers, area chairs, and senior area chairs on the conference website: https://t.co/dMWGwPej05
this is big... 50 AI researchers from Bytedance, Alibaba, Tencent, and other labs/universities just published a 300-page paper with surprising lessons about coding models and agents (data, pre and post-training, etc). key highlights:
> small LLMs can beat proprietary giants
RL (RLVR specifically) gives small open-source models an edge over big models in reasoning. a 14B model trained with RLVR on high-quality verified problems can match the performance of OpenAI's o3.
> models have a hard time learning Python.
mixing language models during pre-training is good, but Python behaves different from statically typed languages. languages with similar syntax (Java and C#, or JavaScript and TypeScript) creates high positive synergy. mixing Python heavily into the training of statically typed languages can actually hurt because of Python's dynamic typing.
> not all languages are equal (coding scaling laws)
the amount of data required to specialize a model on a language drastically depends on the language. paper argues like C# and Java are easier to learn (less training data required). languages like Python and Javascript are actually more tricky to learn, ironically (you see AI most used for these languages :)
> MoE vs Dense (ability vs stability)
MoE models offer higher capacity, but are much more fragile during SFT than dense models. hyperparams in training have a more drastic effect in MoE models, while dense models are more stable. MoE models also require constant learning rate schedules to avoid routing instability.
> code models are "insecure" by default (duh)
training on public repos makes models learn years of accumulated insecure coding patterns. safety fine-tuning often fails to work much on code. a model might refuse to write a hate speech email but will happily generate a SQL-injection vulnerable function because it "works."
> structure matters more than content in reasoning training
when fine-tuning on CoT the template and the step-by-step reasoning pattern matter much more than the factuality of the reasoning! the model actually learns the "cognitive template" of breaking down a problem. when creating synthetic training data for reasoning, the step-by-step structure (the "how") matters more than making sure every single intermediate fact is perfect.
> "lost in the middle" problem still persists
newer models support massive contexts, but accuracy still degrades when important code is in the middle of the prompt (or context) rather than at the beginning or end.
> multi-agent debate reduces hallucination
it is significantly better for complex software engineering tasks. i believe setting up the debate is very critical, it can even cause agents to reinforce hallucinations if not tuned correctly.
> the"alignment tax" on code
safety alignment can degrade general coding ability. the paper actually proposes a solution to do the alignment in a way to mitigate this tax.
read the full paper: https://t.co/UMcKuRnJ5H
AI scientists are coming.
However, current AI research tools work in isolation. Paper summarizers, experiment automators, and hypothesis generators are all done separately and disconnected from the research process. But real science isn't linear. It's collaborative, iterative, and deeply human.
This new research introduces OmniScientist, a platform where AI and human scientists work together in a symbiotic ecosystem. The key idea: mutual feedback loops. Human expertise refines AI capabilities. AI insights then expand human research scope. Both evolve together.
The platform integrates literature analysis, hypothesis generation, experimental design optimization, and results interpretation. Humans provide oversight at critical decision points.
An exciting vision is AI systems that augment scientific discovery across physics, chemistry, biology, and computational sciences. The work is not about replacing the scientific process but rather about enhancing and augmenting it.
What makes this powerful: AI handles scale and pattern recognition. Humans provide intuition and validation. Together, they tackle problems neither could solve alone.
(bookmark it)
Paper: https://t.co/xwvDQ56s4W
EURECOM and EDF built France’s largest energy #knowledgegraph powering a new era of energy intelligence, read on at
https://t.co/zwP901okGx
Great collaboration between @EURECOM and the SEQUOIA R&D team at @EDFofficiel#research#energy
core pitch is running a simulation of an entire city with emulated consciousness for consumer market research by 2033. though quickly unclear where reality really stands.