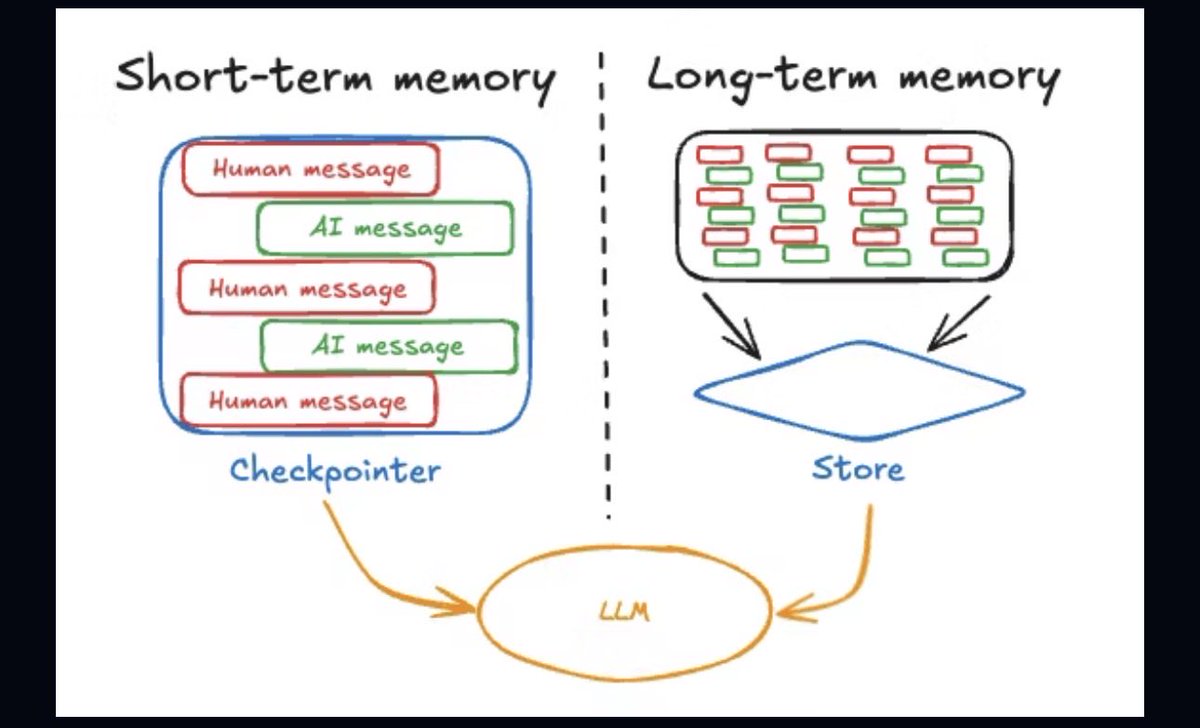
كثير يختصر مفهوم الـ Memory في أنظمة الـ AI على “حفظ المحادثات”، بينما فعليًا الـ AI Agents الحديثة تعتمد على طبقات مختلفة من الذاكرة، وكل طبقة لها وظيفة مختلفة داخل الـ Architecture.
التقسيم الأساسي:
Short-Term Memory
Long-Term Memory
والـ Long-Term غالبًا تنقسم إلى:
Short-Term Memory
ذاكرة مؤقتة مرتبطة بالـ current context.
تُستخدم لتتبع:
آخر الرسائل
الـ active workflow
نتائج البحث الحالية
حالة الجلسة
مثال:
داخل Conversational Search System، الـ Agent يتذكر مؤقتًا آخر query والملفات المفتوحة والـ filters الحالية أثناء الجلسة.
Semantic Memory
ذاكرة “المعرفة”.
النظام يحفظ:
هيكلة البيانات
العلاقات بين الـ entities
تصنيفات الملفات
تفضيلات المستخدم
مثال:
في نظام بحث ضخم، الـ Agent يفهم نوع المستندات والعلاقات بينها باستخدام Embeddings وVector DBs.
Episodic Memory
ذاكرة “الأحداث والتجارب”.
النظام يتذكر:
ماذا حدث سابقًا
نتائج الـ workflows
الأخطاء السابقة
الـ feedback التاريخي
مثال:
يتذكر أن Workflow معين أعطى نتائج ضعيفة مع Dataset محددة أو أن المستخدم طلب تقرير مشابه سابقًا.
Procedural Memory
ذاكرة “كيفية التنفيذ”.
هنا الـ Agent يتذكر الـ execution patterns نفسها.
مثال من الـ pipelines الحديثة:
تحويل الـ query إلى embeddings
تنفيذ Hybrid Search
إعادة ترتيب النتائج
بناء response مع citations
إرسال النتيجة عبر API أو WhatsApp
الفرق الحقيقي يبدأ لما تدمجهم مع بعض:
Semantic → ماذا يعرف النظام
Episodic → ماذا حدث سابقًا
Procedural → كيف ينفذ ويتصرف
وهنا يتحول الـ AI من Chatbot عادي إلى AI-Native System يمتلك:
Context
Experience
Execution Behavior
@KHrbani@Hajajn200 يمرحبا بك وكل عام وانت طيب وبخير بالعكس كل الادعاءات الي قاعد تشير لها وضحها لك مهندسنا المبدع وكان لك الحق في معرفة التفاصيل والفهم الأكثر في الكلام الي طرحته عموما تشرفت فيك ونتمنى نشوفك من مستخدمين @Cranlcom الي يعطون رأيهم ونقدهم البناء في تطوير منتجاتنا السعودية 🫡🇸🇦
كنت ناوي أنقل مشروعي القادم لـ DigitalOcean بسبب الحاجة لـ SSH وتحكم كامل في السيرفر.
Cranl السعودية🇸🇦 اليوم سحبوا البساط:
🔹 Sandboxes كاملة مع SSH access احترافي
🔹 Micro-VMs معزولة (تقنية شبيهة بـ Firecracker اللي تستخدمها AWS Lambda)
🔹 hardware عالي الأداء
🔹 deployment مباشر من GitHub repo
🔹 تحكم كامل في الـ environment
اللي يفرّقها فعلاً:
١. الـ latency منخفض جداً للمستخدم السعودي والخليجي (٥٠-٨٠ms أسرع من فرانكفورت)
٢. بياناتك تبقى داخل المملكة، يعني PDPL compliance تلقائي بدون أي تعقيد قانوني
٣. الـ Micro-VMs تعطيك isolation أقوى من Docker العادي بأداء قريب من bare metal
Cranl السعودية بدأت تنافس بقوة في عالم الـ infrastructure 🇸🇦
Hi (:
Today we FINALLY announce our very new: CranL Sandboxes
A place where you can deploy and host your AI agent from your github repo, comes with:
- SSH access and full control
- Fully isolated Micro-VMs and high performance hardware
- Hosted in Saudi Arabia 🇸🇦 and more!
كنت ناوي أنقل مشروعي القادم لـ DigitalOcean بسبب الحاجة لـ SSH وتحكم كامل في السيرفر.
Cranl السعودية🇸🇦 اليوم سحبوا البساط:
🔹 Sandboxes كاملة مع SSH access احترافي
🔹 Micro-VMs معزولة (تقنية شبيهة بـ Firecracker اللي تستخدمها AWS Lambda)
🔹 hardware عالي الأداء
🔹 deployment مباشر من GitHub repo
🔹 تحكم كامل في الـ environment
اللي يفرّقها فعلاً:
١. الـ latency منخفض جداً للمستخدم السعودي والخليجي (٥٠-٨٠ms أسرع من فرانكفورت)
٢. بياناتك تبقى داخل المملكة، يعني PDPL compliance تلقائي بدون أي تعقيد قانوني
٣. الـ Micro-VMs تعطيك isolation أقوى من Docker العادي بأداء قريب من bare metal
Cranl السعودية بدأت تنافس بقوة في عالم الـ infrastructure 🇸🇦
عشت نفس القصة مع OpenRouter في نظام production لعميل. الـsystem prompt كان 1,800 توكن والكاش ما يشتغل. زودته لـ2,200 (أضفت أمثلة وتعليمات أوضح للموديل) وضبط.
النتيجة: cache hit rate وصل ~85%، والتكلفة نزلت بشكل ملحوظ على الrequests المتكررة.
ملاحظة : راقب cache_creation_input_tokens و cache_read_input_tokens في الresponse، هي المؤشر الحقيقي.
اكتشفت اليوم ليش الـprompt caching ما كان يشتغل مع Haiku 4.5. صار لي اسبوع احاول اصلحه بس ما ضبط مع انه الSonnet شغال زي الحلاوة.
بعدين قريت انه Bedrock حاطين حدّ معين لكل موديل و الحدّ حق haiku اعلى من الموديلات الثانية. الـsystem prompt عندي 2,500 tokens. و الحد من 4,096 و فوق. يعني لازم اخلي الـprompt اطول😂
https://t.co/sRHYTHLoKh