This is Huge, read this.
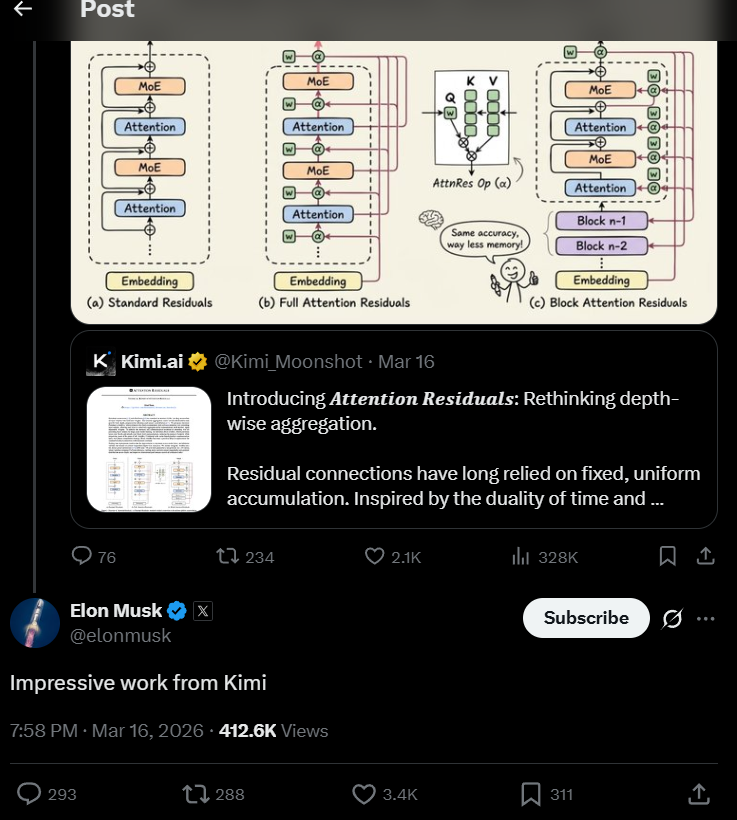
Moonshot AI company that build KimiAI just released new model for residual attention that boosting AI compute efficiency to 1.25 times on a 48 billion parameter
https://t.co/QQ1ATLvUZ4
For a decade residuals have blindly summed prior layers causing dilution. Each new layer now learns to attend over all previous outputs instead.
Block AttnRes scales it with under 2% latency and lifts benchmarks like 7.5 on GPQA
And the craziest thing about this is the first author of kimiAI team is a 17 years young boy @nathancgy4
Elon also just interact with their new development last night
https://t.co/IdMYwNsDHI
No one has ever send a fees to nathan, so i will send all the creator fees to his github to support him and his team
https://t.co/fEbm4wm9gV