Quick reminder that, yes, “PhD admission email season” is indeed here but you should not share emails on here that potential students send to you in good faith and in confidence. Doesn’t matter if they have a typo, or are annoying or anything else. Just not cool.
Watching PhD students lose their last crumbs of illusion about science when faced with stubborn, unreasonable, or completely absent reviewers is heartbreaking. We've got to do better as a community. #NeurIPS2024
Introducing Stormer, a scalable transformer model for skillful and reliable medium-range weather forecasting. Stormer achieves competitive accuracy for short-range, 1–7 day forecasts, while outperforming Pangu-Weather and Graphcast by a large margin for longer lead times.
Paper: https://t.co/olgCjQUke6
Project website: https://t.co/k3M4eGvM7q
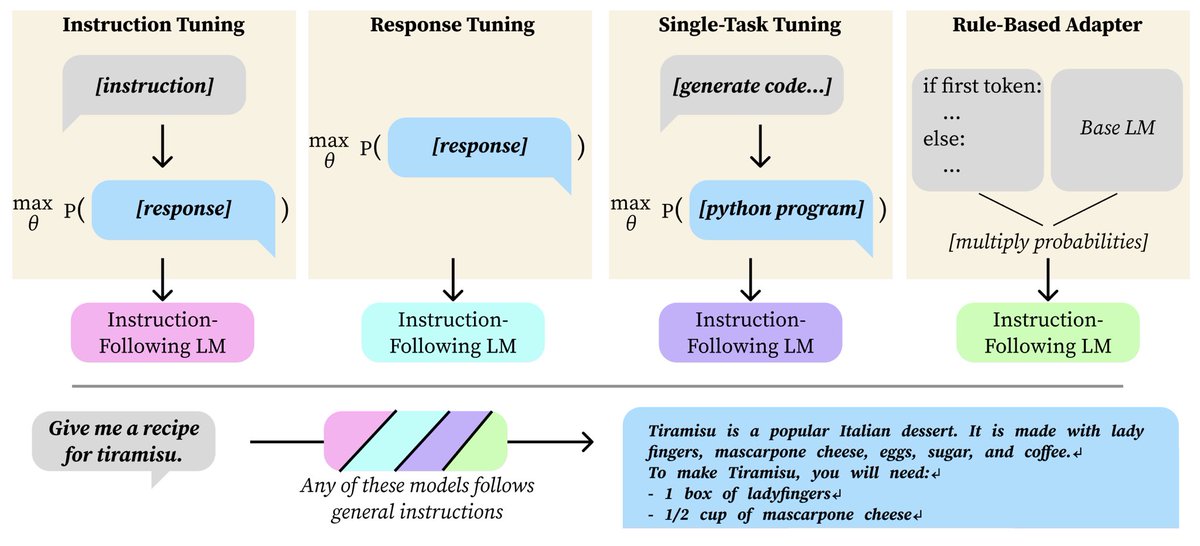
If I finetune my LM just on responses, without conditioning on instructions, what happens when I test it with an instruction?
Or if I finetune my LM just to generate poems from poem titles?
Either way, the LM will roughly follow new instructions!
Paper: https://t.co/Jk3EOtLJXF
I just received the EMNLP reviews, and the quality exceeded my expectations. Thank you to all the area chairs and reviewers for their excellent work and service.🤗
Now that we have a frontier model that's open-weight (not open-source), it's time to go back to all those ambitious use cases where open-weight models failed to deliver (agents) and try again, so we can have reproducible science and not worry about API models getting deprecated.
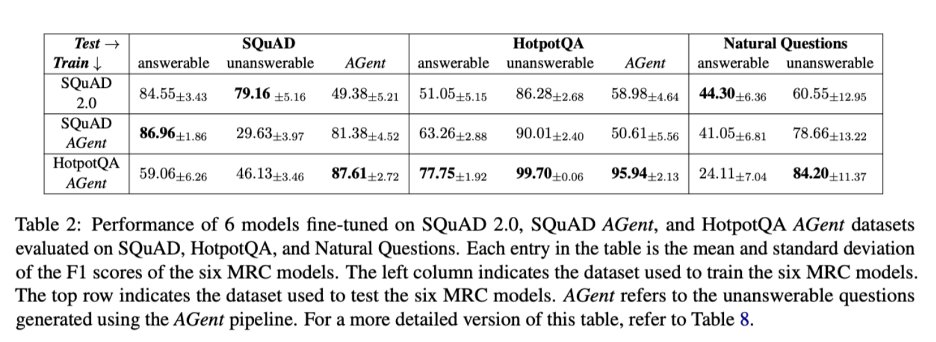
We also demonstrate that models fine-tuned using AGent unanswerable questions exhibit comparable performance to those fine-tuned on human-annotated unanswerable questions from SQuAD 2.0 on 7 out of 8 test sets.
(8/8)
New paper!
Manually annotating unanswerable questions is labor-intensive.
To address this, we propose AGent, a novel pipeline that automatically creates high-quality new unanswerable questions.
(1/8)
Every day I am in awe of international students. Doing a PhD in your native language and home country is hard. Doing it in a non-native language, in a different country and different culture is so much harder. You are not stupid. You are legends.
Holistic Evaluation of Language Models
Percy Liang, Rishi Bommasani, Tony Lee et al..
Action editor: Karthik Narasimhan.
https://t.co/0bDrqwqU3Y
#language#dialects#trustworthiness
@miserlis_@rkdsaakyan Thank you for the resource. The first time I read those policies, I did not even think that I might need it.
On the repercussions, I totally agree. We need new policies to drive this field in the right direction.