Release 3 of the Soynade Open Source Month.
Oolel-Voices: a speech generation model supporting voice cloning with expressive, modular control over tone and pace, making it suitable for content creation.
Try it now: https://t.co/vJltnEKH6V
Model: https://t.co/3O1egcmFt4
We are releasing Oolel-Corrector, a new model in the Oolel family trained to fix non-standard Wolof orthography as commonly written on social media.
The model is available on Hugging Face.
https://t.co/PVKNy43TnA
We're releasing a dataset of non-standard Wolof orthography. The goal is to help models understand Wolof as it's actually written online, not just as it should be.
Dataset: https://t.co/KtP7O00aYB
We're releasing a dataset of non-standard Wolof orthography. The goal is to help models understand Wolof as it's actually written online, not just as it should be.
Dataset: https://t.co/KtP7O00aYB
We're releasing a dataset of non-standard Wolof orthography. The goal is to help models understand Wolof as it's actually written online, not just as it should be.
Dataset: https://t.co/KtP7O00aYB
Oolel-Embed est efficace grâce aux représentations Matryoshka, permettant de représenter l'information dans des espaces vectoriels très petits.
Voyez Oolel-Embed en action:
4e publication du mois de l'open-source de Soynade.
Oolel-Embed: un modèle permettant de récupérer des documents directement à partir de la parole, sans passer par des étapes intermédiaires coûteuses de reconnaissance vocale et de traduction.
Model: https://t.co/sDTZoT2iV7
Release 3 of the Soynade Open Source Month.
Oolel-Voices: a speech generation model supporting voice cloning with expressive, modular control over tone and pace, making it suitable for content creation.
Try it now: https://t.co/vJltnEKH6V
Model: https://t.co/3O1egcmFt4
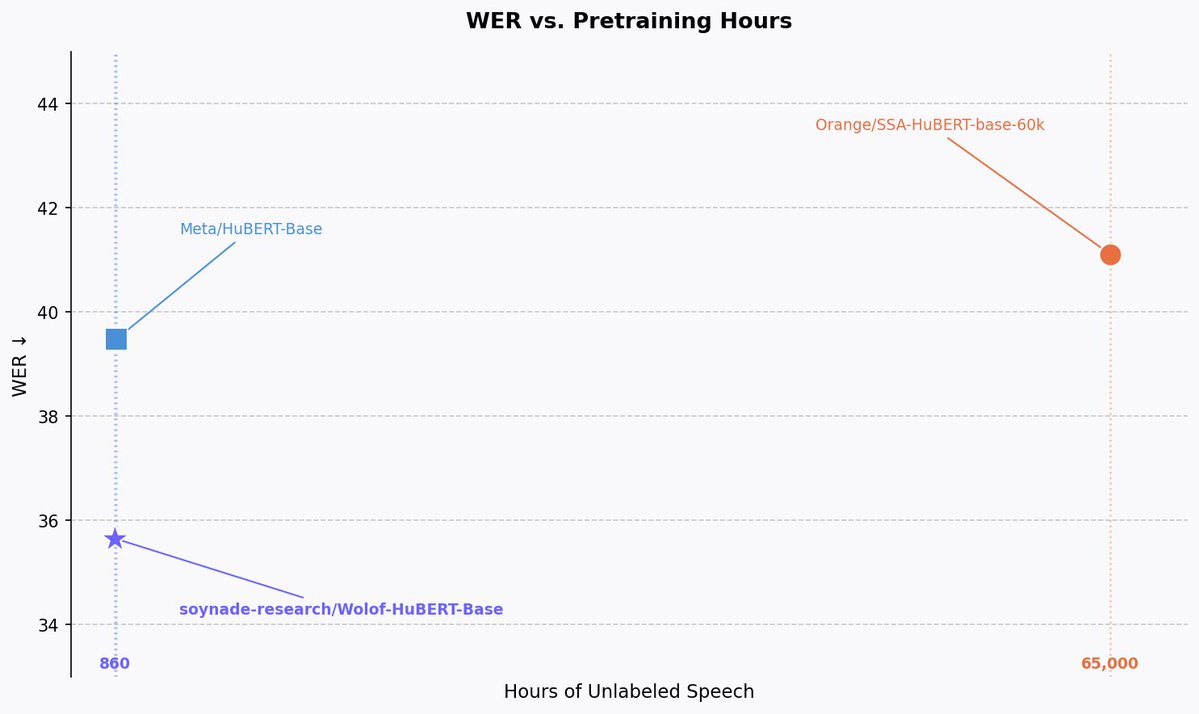
Release 2 of the Soynade Open Source Month.
A small foundational speech representation model for Wolof, continued pretrained from Meta/HuBERT on 860 hours of Wolof speech. This improves the ASR performance using only unlabeled speech data.
https://t.co/vQizR2galx
Continued pre-training allows us to be more compute-optimal than Orange's model while significantly outperforming the base Meta/HuBERT-Base model.
We release the ASR fine-tuned model along with 100 hours of clean Wolof ASR data.
Models and dataset here:
https://t.co/dlHyl8Q20o
Today we kick off Soynade's Open Source Month, four weeks of releasing models, datasets, and tools for African languages.
Learn more: https://t.co/6xv2yMrluu
The first release is live:
→ AfVoices-Translated: +200k Bambara-English speech translation dataset with acoustic tags.
Ce qui permettra d'avoir des capacité multimodales pour les langues africaines à moindre coût 💸
Stay tuned! On a plein de modèles ouverts qui arrivent.
Oolel peut voir des images et vidéos : un vision LLM ouvert pour le wolof.
Et il n’a été entraîné sur aucune donnée visuelle en wolof !
On explore des pistes de recherche pour transférer les capacités multimodales d’une langue à une autre, sans entraînement multimodal direct.
It has been optimized for essential tasks like natural text generation in Wolof and English, translation, and RAG capabilities, while maintaining a compact size.
𝐎𝐨𝐥𝐞𝐥-𝐒𝐦𝐚𝐥𝐥-1𝐁: On-device AI for Wolof with a Lightweight Language Model
🚀 Meet Oolel Small, the lighter version of the Wolof LLM Oolel - bringing on-device AI to Wolof speakers. You can run it locally without any internet connectivity
En attendant, vous pouvez d'ores et déjà combiner ces deux technologies. C'est la beauté de l'open source - des innovations qui se complètent pour faire avancer les technologies pour les langues sous-représentées.
Petite expérience intéressante que vous pouvez reproduire : générer du texte avec notre LLM 𝐎𝐨𝐥𝐞𝐥 et le vocaliser à l’aide du modèle Text-to-Speech de @galsenai.
La combinaison de ces deux modèles open source ouvre la voie à de nombreux cas d'usage : création de contenus audio, assistants vocaux, etc. Les prochaines versions d'Oolel intégreront directement des capacités vocales.