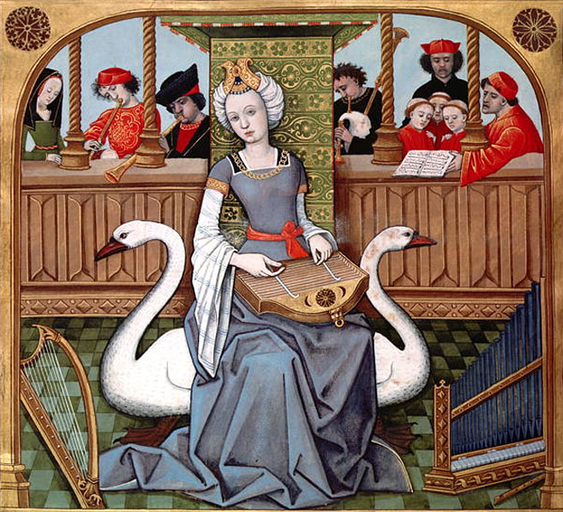
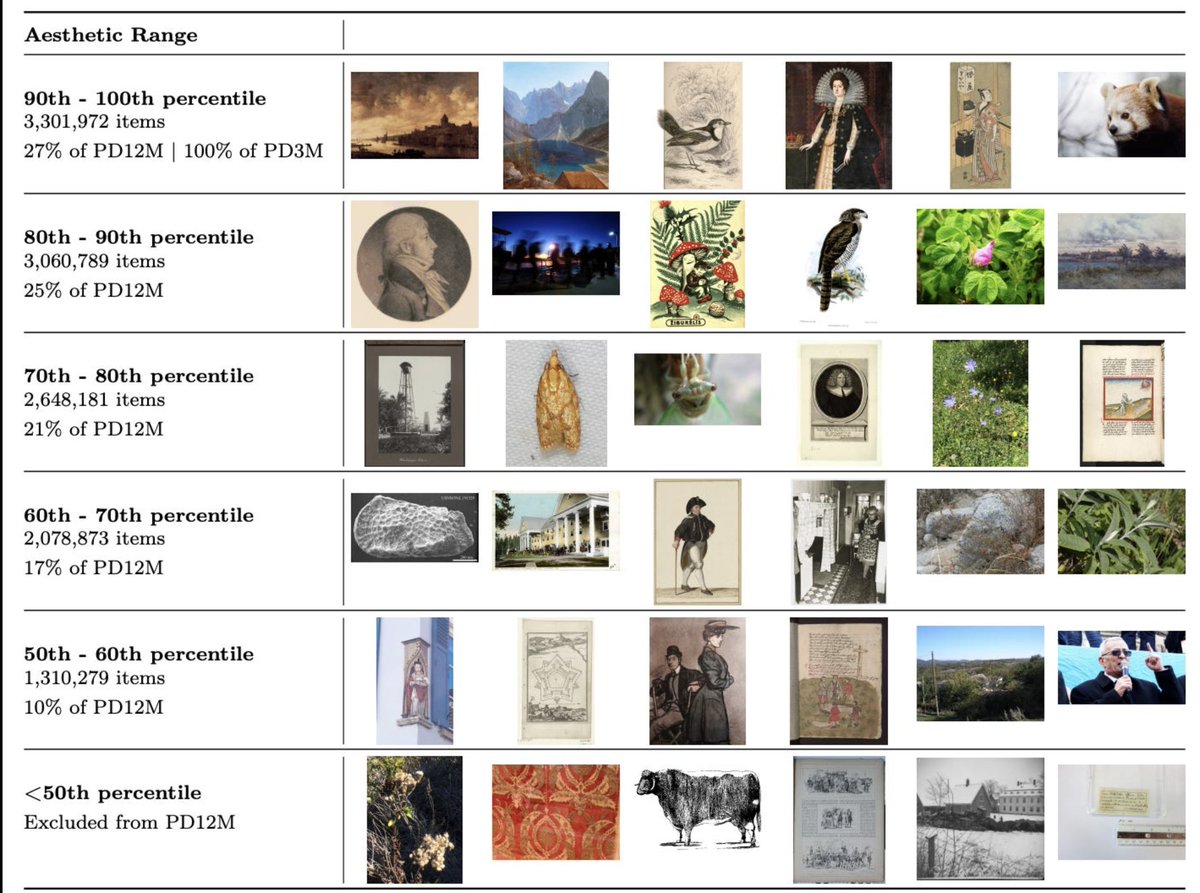
We’ve put 12.4 million of the most beautiful images in the public domain into an image-text dataset with community governance.
Public Domain 12M is completely free. Its 30+ terabytes of images are hosted on AWS, so downloading them is fast and won’t negatively impact the cultural heritage organizations who originally shared them.
I sat down with CEO Jordan Meyer and CTO Nick Padgett to talk all things Public Diffusion, from fine-tuning, to prompting like a photographer and what’s next for beta testers. Link to the interview, and some choice quotes, in 🧵
A peek into what’s planned for beta testing: “this early beta is a crucial step towards our goal of releasing an open-weight model into the commons next year. . . .”
https://t.co/2ZP2o9uNoY
I sat down with CEO Jordan Meyer and CTO Nick Padgett to talk all things Public Diffusion, from fine-tuning, to prompting like a photographer and what’s next for beta testers. Link to the interview, and some choice quotes, in 🧵
What CEO Jordan Meyer hopes PD will be known for: “[enabling] a whole class of users—who were uncomfortable with other methods—to engage with AI seriously and professionally and deeply, and to come up with new techniques in their own artistic practice that they're excited about.”
https://t.co/QTrZMtQxwQ
Help us shape Public Diffusion—our t2i model trained on 30 million highly-aesthetic public domain images. Join the private beta!
https://t.co/EqzL4QVlwf
More Public Diffusion samples! It’s still very early on (<33% done), but I’m optimistic with the quality of these outputs.
Some interesting examples in 🧵, all prompts in the alt text. My favorites:
More Public Diffusion samples! It’s still very early on (<33% done), but I’m optimistic with the quality of these outputs.
Some interesting examples in 🧵, all prompts in the alt text. My favorites:
Here are some images from our first candidate model for Public Diffusion.
It still needs a lot more time in the oven, but these early results are very promising.
Prompts in the alt text.
Public Diffusion proves a radical idea: you don’t need infinite data—you need curated data. With just public domain images, the early results rival top-tier AI art models with just 30% training complete. The future isn’t owned. It’s shared. cc: @spawning_@ncpadge@JordanCMeyer
First visual model trained on fully open data coming. Like for text, the striking thing is not only that it is possible in the first place but that it brings so much more variety and diversity of outputs. There’s an entire world beyond web archives.
With Public Diffusion, @spawning_ set out to prove that it's possible to train a beautiful AI Art model using only images from the public domain.
As of today, we’re 30% into training our first model, and the early results speak for themselves.
Take a look…🧵
███░░░░░░░░░ ~25% trained
"A painting of a mountain lake with a boat in the foreground, surrounded by lush green grass, trees, and rocks. The sky is filled with white, fluffy clouds, creating a peaceful atmosphere."
While lawsuits about training data and copyright law wend their way through the courts...
...@spawning_ is building image generation tools trained on public domain/CC0.
Check out Public Diffusion.
Early access: test Public Diffusion, our image-text model training on 30 million public domain images. Sign up to join the private beta!
https://t.co/EqzL4QUNGH