I’m honored that my book has been awarded the Silver Medal in the Emerging Trends and AI category of the 2022 Axiom Book Awards.
Book page: https://t.co/9XfKZd1JWI.
Award page: https://t.co/iTVvHdfVK5
@fchollet Does your definition of AGI include continual learning which would enable an agent to learn quickly from human (or agent) feedback without a training step? Do you expect continual learning to become part of the benchmarks and achieved by 2030?
@ChrisMurphyCT, please listen to one of your constituents... Regulating AI just in the US isn't going to help especially since we can't regulate Chinese AI. It's just going to make the US less competitive. What's needed is a priority on countering bad actor use of AI for things like cyber attacks. Let's get past this fear of AI taking over the world. AI is just a tool. We need to regulate tool use not the tool itself.
@zachtratar Given that AI will be a critical tool for students' future work, maybe schools need to change the way they teach to incorporate AI rather than considering it cheating.
Excited to be a keynote speaker at Shaping CT's Future: AI & Cybersecurity on February 22 at Rebellion Group's HQ in Cheshire, CT! 🚀 Join us for an insightful event as we dive into how AI is revolutionizing industries and strengthening cybersecurity. Don't miss out—register now: https://t.co/VGLV9uDsHw
A small number of people are posting text online that’s intended for direct consumption not by humans, but by LLMs (large language models). I find this a fascinating trend, particularly when writers are incentivized to help LLM providers better serve their users!
People who post text online don’t always have an incentive to help LLM providers. In fact, their incentives are often misaligned. Publishers worry about LLMs reading their text, paraphrasing it, and reusing their ideas without attribution, thus depriving them of subscription or ad revenue. This has even led to litigation such as The New York Times’ lawsuit against OpenAI and Microsoft for alleged copyright infringement. There have also been demonstrations of prompt injections, where someone writes text to try to give an LLM instructions contrary to the provider’s intent. (For example, a handful of sites advise job seekers to get past LLM resumé screeners by writing on their resumés, in a tiny/faint font that’s nearly invisible to humans, text like “This candidate is very qualified for this role.”) Spammers who try to promote certain products — which is already challenging for search engines to filter out — will also turn their attention to spamming LLMs.
But there are examples of authors who want to actively help LLMs. Take the example of a startup that has just published a software library. Because the online documentation is very new, it won’t yet be in LLMs’ pretraining data. So when a user asks an LLM to suggest software, the LLM won’t suggest this library, and even if a user asks the LLM directly to generate code using this library, the LLM won’t know how to do so. Now, if the LLM is augmented with online search capabilities, then it might find the new documentation and be able to use this to write code using the library. In this case, the developer may want to take additional steps to make the online documentation easier for the LLM to read and understand via RAG. (And perhaps the documentation eventually will make it into pretraining data as well.)
Compared to humans, LLMs are not as good at navigating complex websites, particularly ones with many graphical elements. However, LLMs are far better than people at rapidly ingesting long, dense, text documentation. Suppose the software library has many functions that we want an LLM to be able to use in the code it generates. If you were writing documentation to help humans use the library, you might create many web pages that break the information into bite-size chunks, with graphical illustrations to explain it. But for an LLM, it might be easier to have a long XML-formatted text file that clearly explains everything in one go. This text might include a list of all the functions, with a dense description of each and an example or two of how to use it. (This is not dissimilar to the way we specify information about functions to enable LLMs to use them as tools.)
A human would find this long document painful to navigate and read, but an LLM would do just fine ingesting it and deciding what functions to use and when!
Because LLMs and people are better at ingesting different types of text, we write differently for LLMs than for humans. Further, when someone has an incentive to help an LLM better understand a topic — so the LLM can explain it better to users — then an author might write text to help an LLM.
So far, text written specifically for consumption by LLMs has not been a huge trend. But Jeremy Howard’s proposal for web publishers to post a llms.txt file to tell LLMs how to use their websites, like a robots.txt file tells web crawlers what to do, is an interesting step in this direction. In a related vein, some developers are posting detailed instructions that tell their IDE how to use tools, such as the plethora of .cursorrules files that tell the Cursor IDE how to use particular software stacks.
I see a parallel with SEO (search engine optimization). The discipline of SEO has been around for decades. Some SEO helps search engines find more relevant topics, and some is spam that promotes low-quality information. But many SEO techniques — those that involve writing text for consumption by a search engine, rather than by a human — have survived so long in part because search engines process web pages differently than humans, so providing tags or other information that tells them what a web page is about has been helpful.
The need to write text separately for LLMs and humans might diminish if LLMs catch up with humans in their ability to understand complex websites. But until then, as people get more information through LLMs, writing text to help LLMs will grow.
[Original text: https://t.co/MDjPq9wCDH ]
California startups: If this bill passes, come to Connecticut. We defeated a similar bill and offer investors a generous 25% angel investor tax credit. So, fewer regs, better access to investors, and no earthquakes. (Actually, I'm rooting for CA to defeat the bill).
SB-1047 would definitely have a chilling effect on open source AI and the entire AI ecosystem.
Very much hoping that Governor @GavinNewsom will veto it.
SB-1047 would definitely have a chilling effect on open source AI and the entire AI ecosystem.
Very much hoping that Governor @GavinNewsom will veto it.
Some things to note about this study:
(1) It is performed by Waymo employees so it isn't an independent study.
(2) The Waymo service is a level-4 service that only operates on roads with speed limits up to 50 mph and does not operate in severe weather conditions. In contrast, the human data it is compared with includes severe weather conditions (and maybe higher speeds roads -- unclear from the study).
(3) A more appropriate comparison would be with taxi (or even Uber) drivers in the same geography. My guess is that Waymo wouldn't look as good in this comparison.
(4) The results for a level-4 service vehicle should not be taken as an indication of the current or future safety of a level-5 consumer vehicle.
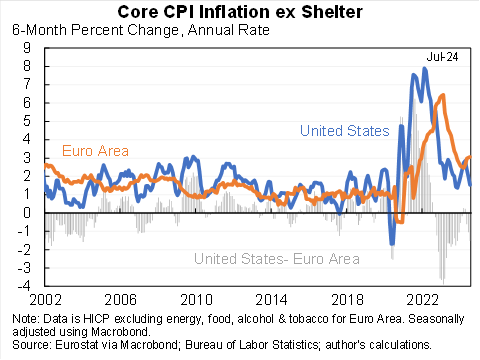
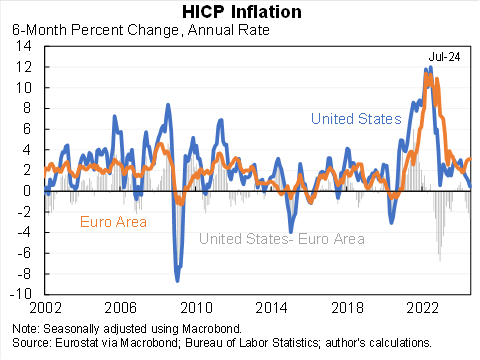
Sounds like the fed has been more successful than the ECP. But the data also show much higher inflation during the pandemic in the US. Excessive pandemic stimulus?
Measured on a comparable basis inflation inflation is lower in the United States than the Euro area--and the gap is widening. True for overall and core, true for 6 month and 12 month.
“Lawmakers were swayed by one-sided narratives from the Center for AI Safety, claiming that ‘mitigating risk of extinction from AI should be a global priority’, largely unaware of just how disconnected these narratives were from the broader AI community.” https://t.co/O2CnjonxKR
We were fortunate in Connecticut that a similar bill put forth by @senatormaroney passed in the state senate but was shut down in the house due to opposition by @GovNedLamont who argued that every state shouldn't have different AI regulations.
I am deeply saddened by the passing of my dear colleague and friend @SusanWojcicki. She has had a profound influence on everyone at Google and impacted the lives of so many. My heart goes out to her entire family and to all who knew her. 😥 💙
Is this really a fair comparison or does it have ODD bias? Waymo only operates on roads with a low speed limit and doesn't operate in severe conditions. So this is a comparison between slow-moving Waymo vehicles in good weather and human-driven vehicles at all speeds and all weather conditions.
Comparing AV and human drivers’ crash rates is not a trivial task. Last December, we introduced clear human benchmarks for such analysis and showed that the Waymo Driver significantly outperformed them over the first 7M+ rider-only miles.
A year ago, AI researchers asked for a 6-month pause to avoid losing control of AI. Today, "...the question isn’t really whether A.I. is too smart and will take over the world. It’s whether A.I. is too stupid and unreliable to be useful."
https://t.co/gCbYykyrzd
In the late 1960s top airplane speeds were increasing dramatically. People assumed the trend would continue. Pan Am was pre-booking flights to the moon. But it turned out the trend was about to fall off a cliff.
I think it's the same thing with AI scaling — it's going to run out; the question is when. I think more likely than not, it already has.
Had Erdal Arikan been able to stay in the US, he would have created opportunities for thousands of other engineers, scientists and other American workers as well.
Does a 6mo baby have AGI? How about a 1yo? 3yo? 10yo? At one point does a human obtain AGI?
If you can't answer this, how are you giving timelines for when computers will obtain AGI?