Introducing Mirage, a unified virtual filesystem for AI agents!
6 weeks. 1.1M+ lines of code. We rewrote bash from the ground up so cat, grep, head, and pipes work across heterogeneous services. S3, Google Drive, Slack, Gmail, GitHub, Linear, Notion, Postgres, MongoDB, SSH, and more, all mounted side-by-side as one filesystem.
Bash that AI agents already know works on every format! cat, grep, head, and wc parse .parquet, .csv, .json, .h5, even .wav! One pipe can stitch S3, Drive, GitHub, Slack, and Linear together, same Unix semantics throughout.
Workspaces are versioned too. Snapshot, clone, and roll back the whole thing with one API call. A two-layer cache turns repeated reads into local lookups, so agent loops stay fast and cheap.
Drop a Workspace into FastAPI, Express, or a browser app. Wire it into OpenAI Agents SDK, Vercel AI SDK, LangChain, Mastra, or Pi. Run it alongside Claude Code and Codex.
Site: https://t.co/zo1orc2wA9
GitHub: https://t.co/zeRAKri7I9
#AIAgents #OpenSource #AgenticAI #Strukto #Filesystem #VFS
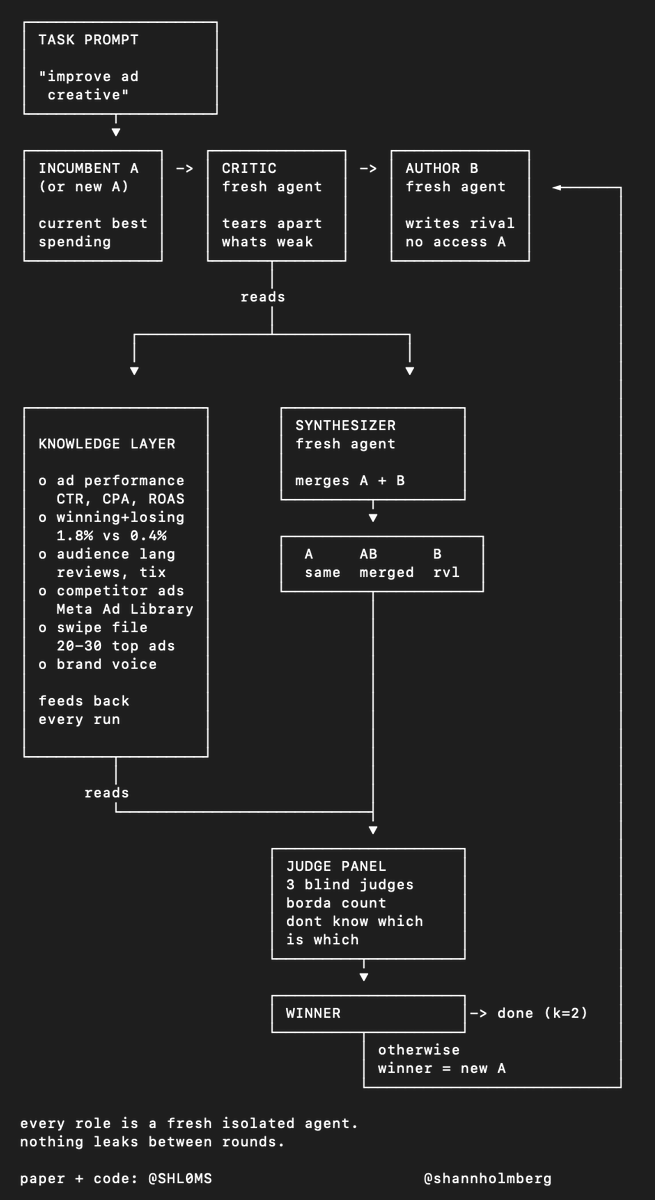
how to use autoreason for ad creative
you run Meta ads, your best creative has a 1.8% CTR and $19 CPA, and you want both numbers to improve. most marketers would prompt an LLM with "write me 10 ad variations" and test whatever comes back.
the problem with asking AI to rewrite its own work is it never says "this is already good." it invents problems that don't exist, drifts from the original angle with every pass, and keeps changing things even when the output was fine two rounds ago.
autoreason tries to fix that with adversarial isolation. every role in the loop is a fresh agent that can't see what the others wrote.
your current best ad is incumbent A, the one that's live and spending.
the critic:
a fresh agent reads your knowledge layer and tears incumbent A apart. it pulls from:
> your last 50 ads with performance data, what patterns separate the 1.8% CTR creatives from the 0.4% ones
> audience language from reviews, support tickets, reddit threads, how customers describe the problem in their own words
> competitor ads from Meta Ad Library and TikTok Creative Center
> a swipe file of 20-30 high performing ads in your vertical, the ones you know are spending heavy because spending heavy means working creative
the critic doesn't rewrite anything, it just produces a teardown. whats weak in the hook, whats generic in the body, whats missing compared to ads that convert better.
author B
a fresh agent that has never seen the original ad. it only gets the critics teardown and the knowledge layer, then writes a rival version from scratch.
if author B could see incumbent A it would just rearrange the same words. keeping it blind is what forces a different angle instead of a tweak.
the synthesizer
a fresh agent takes both and produces three candidates:
> A unchanged (keeping the original is always an option, this is how the system knows when to stop)
> AB merged, pulling the strongest hook from one and the strongest body from the other
> B the rival as-is
the judge panel
3 blind agents score all three using borda count. they dont know which is original, which is rival, which is merge. they look at hook strength, clarity of the offer, social proof, CTA friction, and how each version stacks up against the swipe file.
the loop
winner becomes the new incumbent. if A wins twice in a row (k=2), the system stops because further iterations would just be scope creep. otherwise it loops back with fresh agents for every role.
nothing leaks between rounds. the judges have none of the context that produced the revisions, which is why their scoring stays clean.
the knowledge layer is one of the things that makes this work for ad creative instead of just generic prompt chaining:
> full ad performance history, CTR, CPA, ROAS per creative
> winning and losing patterns across your account
> customer language from reviews, tickets, reddit
> competitor ads from Meta Ad Library and TikTok Creative Center
> swipe file of high performing ads in your vertical
> your brand voice and positioning
without reference points for what a 3%+ CTR ad looks like in your space, the critic has no benchmark and the author writes copy that could be for any product. pull 20-30 ads from competitors and adjacent brands that you know are spending heavy, screenshot them, feed them in.
you still run the winner through real A/B testing in Meta. autoreason just narrows the search space so youre testing strong candidates instead of random shots.
results feed back every run so the next one is sharper
paper + code: SHL0MS / Nous Research
i think the original statement is unfalsifiable as stated, so might help to add a quantitative dimension
"what tasks is the cost of human explanation significantly lower than cost of explaining it to an AI"
this would be based on cost of representation and compression ratio
what if the explanation (komolgrov complexity) is as complex as the solution?
a lot of things that are hard to explain have computational processes running @ ~80 years * 16 waking hours * continuous sensory input 24/7 parallel processing
certain formulations arrive with unusual authority
they feel found, not manufactured
taste seems like tuning, not arbitrary preference
repeated exposure refines receptivity
creation feels partly receptive
1. if you don't know how to solve a problem, just reframe it as collecting data. journaling / taking notes / trying shit -- just make sure it accumulates. this makes time your ally and often solves it for you.
2. the feeling that you're smart / clever / invincible is right before you're about to get fucked / humbled. proceed with caution.
3. pick a "bread-and-butter" gym workout -- something that takes 25-30 min instead of intense 90-120 min bodybuilder stuff. momentum will carry you.
4. we treat things like discipline / high agency / focus as if they were moral character traits vs. mechanistic failure modes. they are systems output and can be engineered, not moral judgment.
5. people do not think in terms of absolutes, giving somebody a justified market-value salary doesn't feel the same as starting lower and feeling like they earned it
6. conspiracy theorists are actually great systems thinkers -- they get the conclusion right but the mechanism wrong, and "debunkers" focus too much on the specifics.
people mistake rawness / rough for authenticity
the most authentic voices feel exceptionally eloquent and articulate at random moments
many writers report perfectly phrased sentences pop out of nowhere, from the spirit world and build the essay / paragraphs around those sparks
Durable Objects Facets were just added to @Cloudflare for Agents Week
There's now four ways of running AI-generated code on this AI cloud
→ Dynamic Workers
→ Sandbox / Container
→ Durable Object Facet
→ Workers for Platforms
Detailed breakdown below 🧵
Here’s a cheat code: find something that fascinates you and then share your fascination.
The energy of genuine fascination is the most compelling force in human communication. More than eloquence. More than authority. More than charisma. A person who is visibly, unreservedly excited about something is magnetic.
matches with my intuitive sense of "agency" --
agency = your ability to be CAUSAL, you possess it when you feel like you can make shit happen
∴ high agency = high causal leverage
literally yes
agency does not = working hard
high agency = accomplishing your goals with as little effort as possible, since there are endless good uses of your time and energy, and spending less of them where they’re not needed frees them up to spend somewhere else
I have coding agents try to do 100 different experiments in 100 different dimensions, search my past, search the web, search the last four months back, test with some skills for simulating myself, prepare thoughts I probably would think of. Then that set of 100 different experiments I can index, I can embed that, that becomes this new ensemble that has statistical properties that are interesting. You can see the central limit theorem applied to yourself.