Excited to share our work evaluating an LLM (GPT-4) vs. physicians at clinical reasoning across four stages of data acquisition. Who do you think was superior?
Many thanks to my awesome co-authors @AdamRodmanMD @DrDanRestrepo @zahirkanjee @philipvvilson@BageLeMage@byrondcrowe
How good is #AI at clinical reasoning? An early, simulated assessment
https://t.co/5fXdgwBXRJ
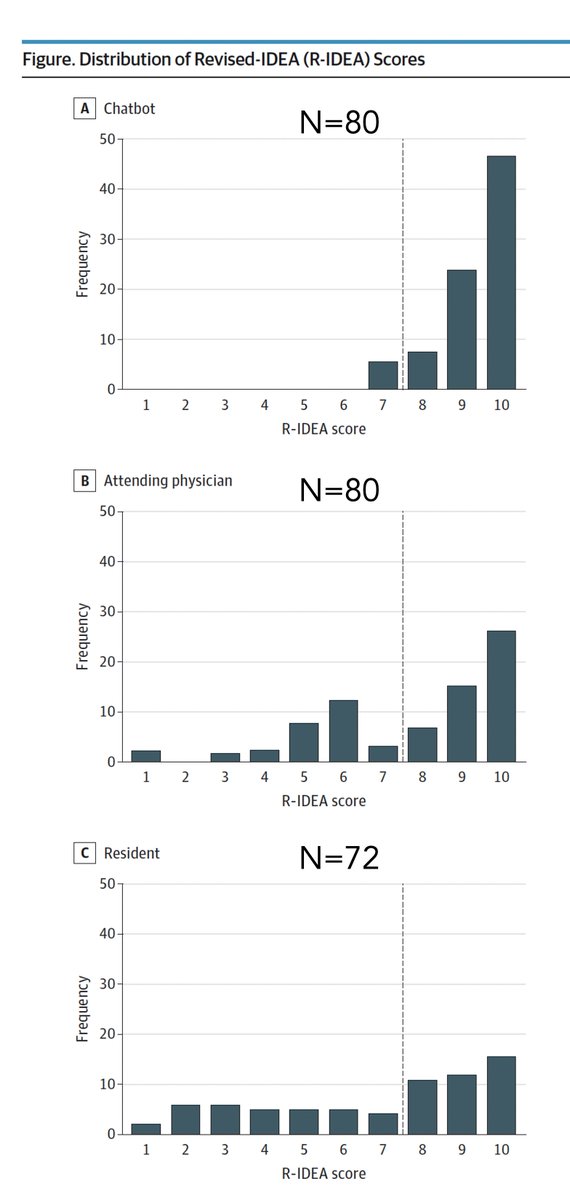
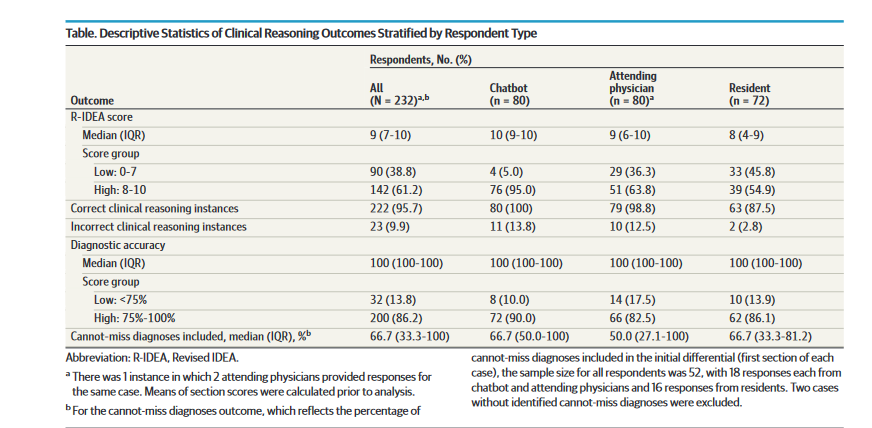
“An LLM was better than physicians in processing
medical data and clinical reasoning using recognizable frameworks as measured by R-IDEA”
Exciting updates!!
(1) I just opened my lab at Boston Children’s Hospital (Harvard-affiliated)
(2) I’m hiring a postdoc focused on integrating GWAS and functional genomic data. Reach out if you’re interested or connect at ASHG next week!
(3) Learn more at https://t.co/XHx4vh2niE
My husband is starting his lab in statistical genetics at @Bos_CHIP this fall! Very proud of him—reach out if you’re looking to join his group (I can attest he’s great!)
I'm excited to share I'll be starting a faculty position at Boston Children's Hospital in the Computational Health Informatics Program (@Bos_CHIP ) this October!!
There is a lot of buzz about our new paper in Nature Medicine on the effects of LLMs (GPT-4) on physician management reasoning! I had TONS of fun working on this -- but what it MEANS requires some unpacking.
A 🧵⬇️
https://t.co/yLZJw1U5IE
Excited to kick off 2025 with our latest publication! We've developed TGFM, a new statistical method for identifying the causal tissue and gene underlying GWAS disease loci—providing new insights into the biology behind GWAS signals.
https://t.co/Qx5WLtMmjc
We're so proud to congratulate our senior residents on graduation! They have been a truly outstanding class and it has been an honor to watch them care for patients. As you head to fellowships or faculty roles near and far, we can't wait to see your bright futures unfold! 🌟🎓🩺
Thanks @Anacapa17 and @jonc101x for the fantastic talks on machine learning and LLMs in medicine! Lots of great discussion but more importantly some wild magic 🪄🪄🪄 (@jonc101x is a magician if you can believe it)
We are INCREDIBLY excited to host (real magician) @jonc101x and @BIDMC_IM alum @Anacapa17 to talk about their research in AI in medicine. Anyone at @BIDMC_IM is welcome -- Deac 312/315 at 6 PM!
(not on Zoom -- in person only!)
Excited to share our work evaluating an LLM (GPT-4) vs. physicians at clinical reasoning across four stages of data acquisition. Who do you think was superior?
Many thanks to my awesome co-authors @AdamRodmanMD @DrDanRestrepo @zahirkanjee @philipvvilson@BageLeMage@byrondcrowe
How good is #AI at clinical reasoning? An early, simulated assessment
https://t.co/5fXdgwBXRJ
“An LLM was better than physicians in processing
medical data and clinical reasoning using recognizable frameworks as measured by R-IDEA”
Our new study in @JAMAInternalMed looking at the reasoning abilities of GPT-4 compared with human physicians just came out.
Big picture: AI displays (much) better reasoning than humans, makes diagnoses similarly, but hallucinates considerably more.
A 🧵to put in context ⬇️
An LLM outperformed human clinicians in the ability to process medical data and display clinical reasoning, raising hopes that LLMs might be able to serve as “copilots” in clinical workflows. https://t.co/xL9CXR0atc
Anxiously awaiting future #AI research that will assess the efficacy of LLMs working with physicians in actual clinical practice! @AdamRodmanMD@arjunmanrai@jonc101x@EricTopol @DrEricStrong
We know LLMs can ace multiple-choice exams. Taking us deeper, an important new study led by @stephcabral_ and @AdamRodmanMD conducts a nuanced evaluation of the clinical reasoning abilities of GPT-4 wrt physicians. Guess who wins?
Need more of these!
https://t.co/yGq9OTSwWx
It is remarkable how routine it has become for careful studies to show that GPT-4 (not trained specifically for medicine) outperforms most doctors in key aspects of diagnosis.
That doesn't mean that GPT-4 is reliable in all circumstances, but it still seems like a big deal.
How good is #AI at clinical reasoning? An early, simulated assessment
https://t.co/5fXdgwBXRJ
“An LLM was better than physicians in processing
medical data and clinical reasoning using recognizable frameworks as measured by R-IDEA”