How well do AI systems (LLMs, VLMs, time series FMs) answer questions about time series data📈?
On ARFBench, the best models achieve ~63% accuracy on real incident data. But models and human experts fail in different areas: combining them achieves 87% accuracy.
🧵1/
https://t.co/GZO4Z8jhFn
How good are AI systems at time-series Q&A? On ARFBench, top models hit ~63% on real incident data. But they miss different things than humans; combine both and accuracy jumps to 87%. Read more in our latest blog post!
How well do AI systems (LLMs, VLMs, time series FMs) answer questions about time series data📈?
On ARFBench, the best models achieve ~63% accuracy on real incident data. But models and human experts fail in different areas: combining them achieves 87% accuracy.
🧵1/
9/
This was a very fun and insightful collaboration between Datadog AI Research and collaborators at CMU, including Ben, @MononitoGoswami , @JunhongShen1 , Emaad, Chenghao, David, @ThisIsOthmane , and my advisor @atalwalkar.
Video Editing is great - but what if you want to apply an effect to your input video described by another video??
Introducing RefVFX, the first method that takes in both an input video and a reference effect video for generative video editing!
Are we done with new RL algorithms? Turns out we might have been optimizing the wrong objective.
Introducing MaxRL, a framework to bring maximum likelihood optimization to RL settings.
Paper + code + project website: https://t.co/j9BCBF7K3R
🧵 1/n
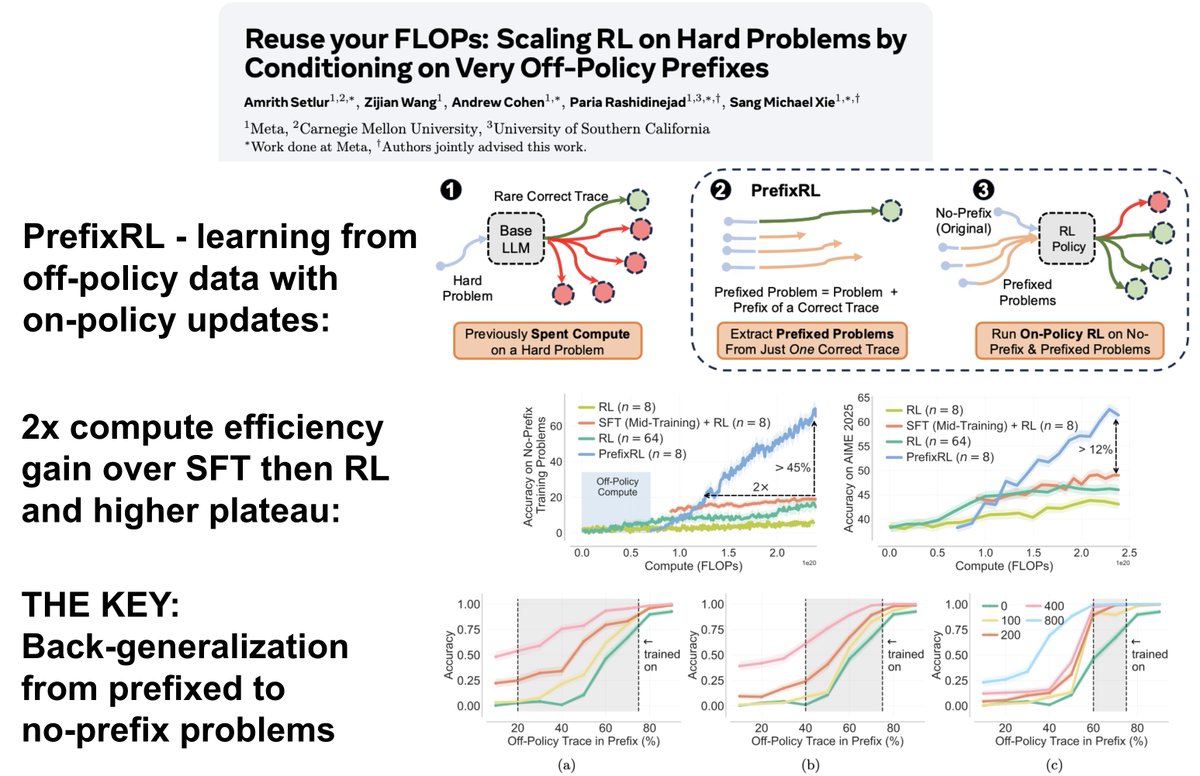
Excited to release PrefixRL, where we achieved what I thought to be a contradiction - learning from off-policy data with purely on-policy updates. This avoids all the instabilities of off-policy RL.
I think this will let us reuse previous RL and sampling FLOPs much more efficiently in the future - just check out PrefixRL’s 2x compute efficiency gain and huge plateau increase over SFT then RL.
https://t.co/MYdhEEpx61
RL on LLMs inefficiently uses one scalar per rollout. But users regularly give much richer feedback: "make it formal," "step 3 is wrong."
Can we train LLMs on this human-AI interaction?
We introduce RL from Text Feedback, with 1) Self-Distillation; 2) Feedback Modeling (1/n) 🧵
Understanding how humans fit into agent workflows is essential, but we still lack concrete ways to measure collaboration.
Our Collaborative Effort Scaling framework introduces metrics grounded in real-world studies and simulations. More details below👇
🤖 Robots rarely see the true world's state—they operate on partial, noisy visual observations.
How should we design algorithms under this partial observability?
Should we decide (end-to-end RL) or distill (from a privileged expert)?
We study this trade-off in locomotion. 🧵(1/n)
💡Can we trust synthetic data for statistical inference?
We show that synthetic data (e.g. LLM simulations) can significantly improve the performance of inference tasks. The key intuition lies in the interactions between the moments of synthetic data and those of real data
Hard to overstate how important observability data is in forecasting! The complex nature of the data led to huge challenges in even evaluating time series models but also helped us make Toto super capable.
Excited to share this work led by Ben and Emaad at Datadog AI Research!
I’m excited to share new work from Datadog AI Research! We just released Toto, a new SOTA (by a wide margin!) time series foundation model, and BOOM, the largest benchmark of observability metrics. Both are available under the Apache 2.0 license. 🧵