Well kind of, you get the answer as a quantum state, to get it out into classical information you need to measure that state. The measurement collapses the state. So you need to repeat the computation and measure again. That slows things down and negates the speedup.
So you unfortunately cannot just use a QPU to simply speed up linear algebra. The quantum speedups are very subtle especially when classical information is involved.
What I am talking about is: you have a quantum algorithm that does the matrix-matrix multiplication. You now need to measure that to get it back to the classical world, the number of measurements that are required is such that it negates any speedup. This is not about how fast you transfer between QPU and CPU or GPU, this is about basic physics of measuring a quantum state.
The same is with getting the classical matrix onto the QPU, that operation also requires more operations than just doing it on a GPU. This is also not about any faster hardware or whatever.
It is unrelated, they are talking about decoding for error correction, yes you need fast data transfer there.
We are talking about using QPUs to accelerate LLMs. Data loading and readout of a QPU for linear algebra is not related to this at all, like zero connection. It's not even about speed, it's about the computational complexity of the algorithms that exist for putting classical data into a quantum state and reading that out after the quantum linear algebra algorithm was applied.
what you linked is about error correction.
speeding up LLMs requires speeding up the attention mechanism. so you need to do matrix matrix multiplication fast on a QPU.
Any algo that does that already assumes working error correction (the research you linked). But the data input and readout problem still remains.
@JKeynesIonQ @_Freeder_ if the data was already fully quantum or we had QRAM and you would only need the final output in quantum form, I agree QPUs could help
but that is not the case
yeah I think he is pumping the stock, which is great since I may or may not have shares 😂
but on a more serious note, the bottleneck of LLMs is the attention mechanism, so a matrix-matrix multiplication.
QPUs cannot help with that since data loading and readout negates any algo speedup
@Hamptonism that's not new - QCNNs are basically MERA tensor networks. MERAs cannot represent volume law entanglement entropy scaling, so they are classically simulatable by construction.
Free market vs. degrowth, bureaucracy, and regulation
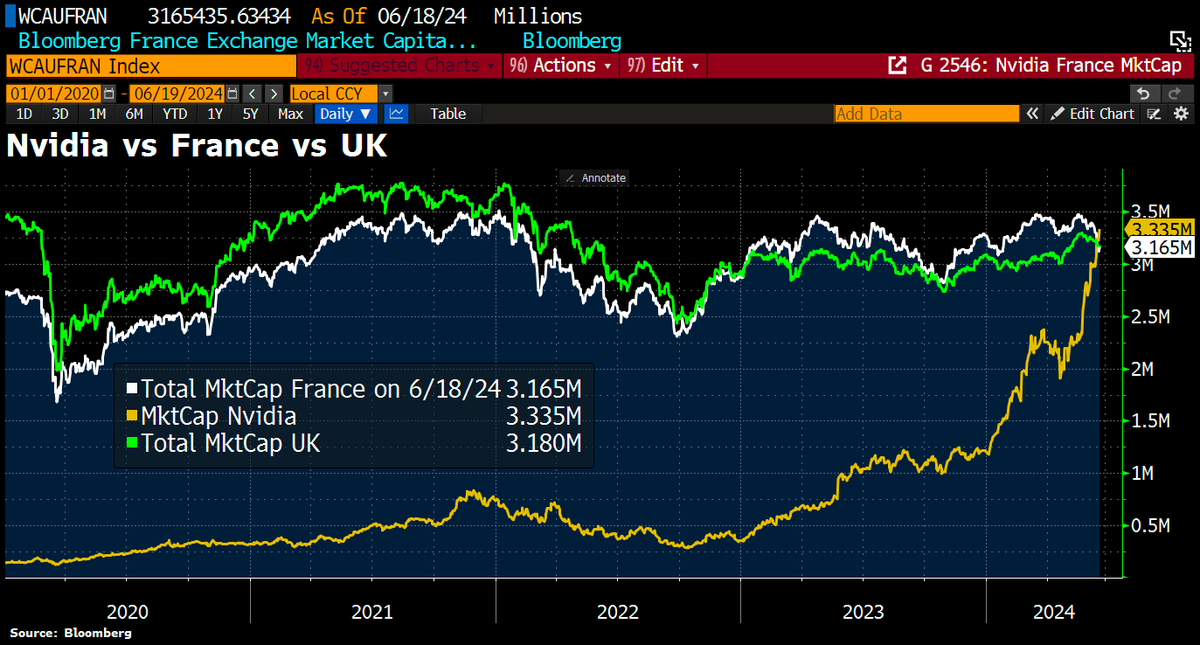
Europe is still well off due to centuries of free market and competition, however, the current economic trajectory will undo that.
When will Europe wake up and start addressing the obvious elephant in the room?
@JKeynesIonQ@RealTimShady42 Idk, AQ is their own metric so I have no feeling for it. What’s the expected log(quantum volume)? Two qubit fidelity?
Do you perhaps have source?