📢MoRight: Motion Control Done Right
"What if your video model actually understood cause and effect?"
Existing motion-controlled video models entangle camera and object motion, and treat everything as kinematic displacement. MoRight changes both.
🔥 Motion Causality — MoRight decomposes motion into actions & consequences. Give an action → MoRight predicts consequences (aka motion simulation) . Give a desired outcome → MoRight recovers the driving action (aka motion planning). Not merely displacing pixels.
🎬 Disentangled Control — MoRight separates camera and object motion, allowing users to independently control each of them. No entanglement.
Project Page: https://t.co/IVIgJopCCI
Paper: https://t.co/t0kQqJfXQE
What is missing to bring real-time motion research into AAA games and real-world robotics?
We present MotionBricks, a step toward bridging this gap with two key components:
- a single generative latent motion backbone covering 350,000+ motion skills, running at 15,000 FPS with 2 ms latency and substantially improved quality and reliability.
- a unified smart primitive interface for locomotion, object / scene interaction, with fine-grained control over generated behaviors.
Webpage: https://t.co/aJE5skUuWD
Code: https://t.co/r56D3TJ8CW
Paper: https://t.co/CtOHXnHZMv (ACM TOG / SIGGRAPH 2026)
We scaled up Lyra to generate explorable 3D worlds! 🚀
Introducing Lyra 2.0 — turning a single image into a 3D world you can walk through, look back, and even drop a robot into 🤖
Code and Model available today!
🌐 Website: https://t.co/plBxCoWkNn
(1/N)
📢MoRight: Motion Control Done Right
"What if your video model actually understood cause and effect?"
Existing motion-controlled video models entangle camera and object motion, and treat everything as kinematic displacement. MoRight changes both.
🔥 Motion Causality — MoRight decomposes motion into actions & consequences. Give an action → MoRight predicts consequences (aka motion simulation) . Give a desired outcome → MoRight recovers the driving action (aka motion planning). Not merely displacing pixels.
🎬 Disentangled Control — MoRight separates camera and object motion, allowing users to independently control each of them. No entanglement.
Project Page: https://t.co/IVIgJopCCI
Paper: https://t.co/t0kQqJfXQE
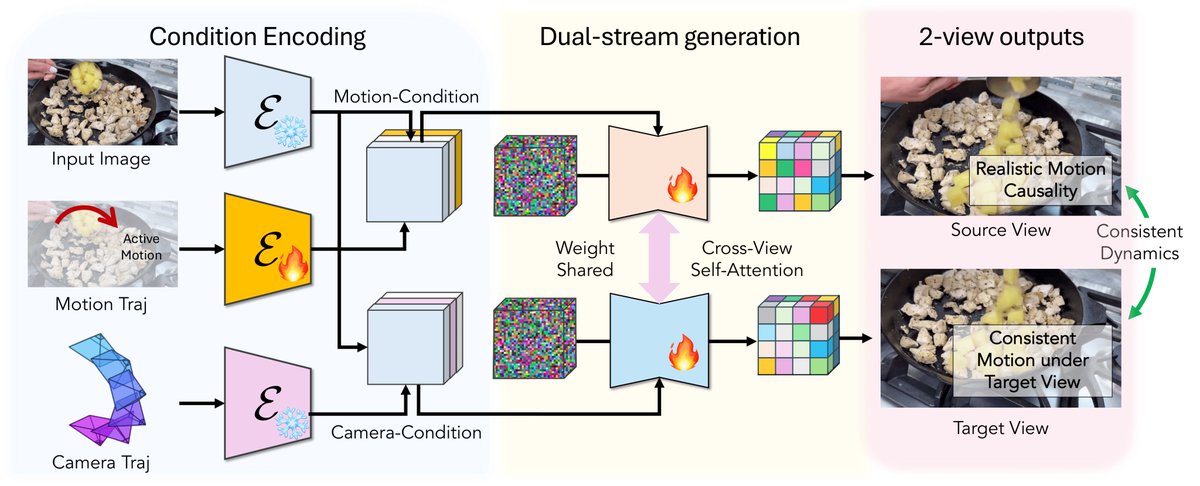
MoRight tackles a core problem in controllable video generation: disentangling camera motion from object motion.
Unlike prior methods that rely on dense future-frame tracks, MoRight uses only first-frame reprojected trajectories + camera poses, yet achieves comparable quality and better motion control.
When doing motion-conditioned video generation, we think the key is in understanding motion causality (what action will lead to what outcome) and camera-motion decomposition (camera changes shouldn't entangle with object dynamics).
MoRight is the first step towards this goal. We support three functionalities:
1. "Simulation": Users provide the action (e.g., moving hands), and the video model generates the consequences (e.g., cups moving and pouring water)
2. "Planning": Users specify the outcome (e.g., balls moving), and the video model generates the action that drives the outcome (e.g., moving legs)
3. "Disentanglement": Users can independently control the camera change and object dynamics, all along with the motion causality mentioned above.
Come and check it at https://t.co/FHScanEtse
P.S. Shaowei is in the job market; you shouldn't miss him!
Our method is straightforward!
Dual-stream architecture: Dual-stream architecture: one stream for object motion on the canonical frame, one for camera motion. Object motion transferred across views via cross-view self-attention.
Data: We curate a systematic data pipeline to decompose the motion sequences in our training video into active and passive motion, allowing the model to learn to capture the motion causality.
Visit https://t.co/4Eqc4p1RoR and try the cool demo at https://t.co/yix9oHF1Bv
Don’t miss our poster session tmr!
Poster: Thur Dec. 3, 11-2pm #4607
Joint work with @david_yao14255, @_saurabhg, @ShenlongWang and @siebelschool
Come and unlock more fun demos at our poster tmr👇
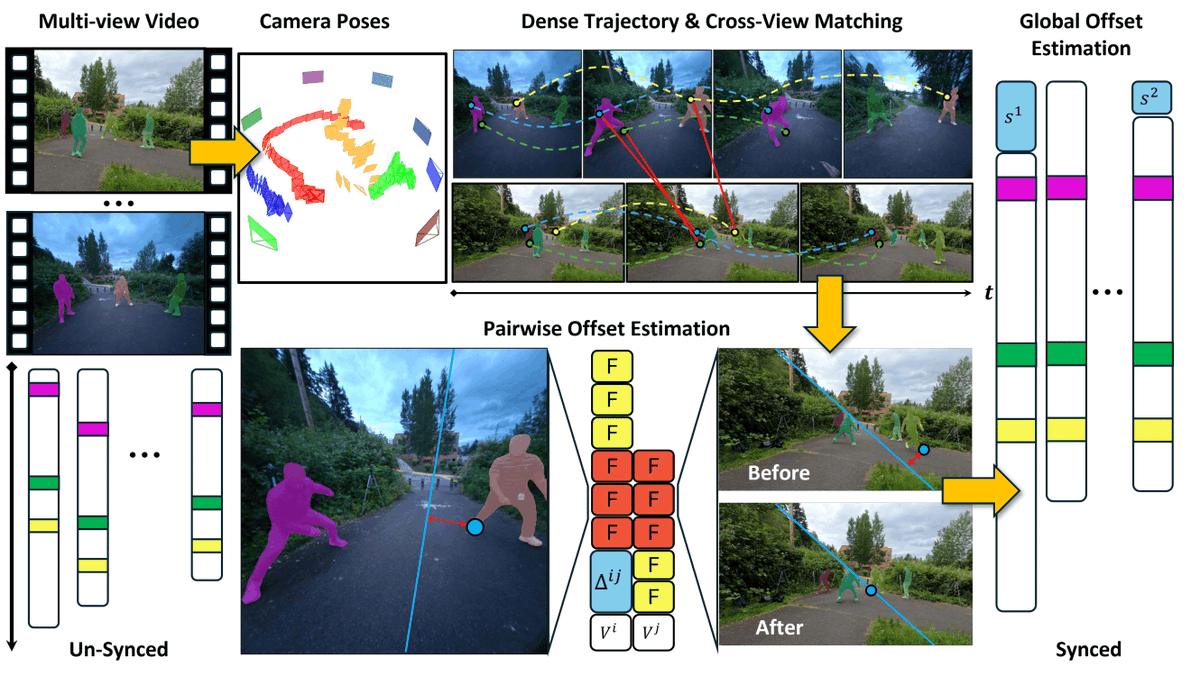
Our method is generic, robust and scalable: we test on ego-exo settings, sports game recordings, multi-person activities, animals. The synched outputs benefit dynamic reconstruction, novel view synthesis, and multi-view data engines. Check demos and applications on our website
Then our method is straightforward: we need cross-view temporal correspondences and camera pose to compute epipolar lines. We estimate pairwise video offsets by minimizing epipolar violations over matched correspondences. Later we perform global optimization to align all videos.
In a dynamic scene with moving camera, the epipolar geometry still holds: In synced videos (left), the green correspondence from one view always align with the red epipolar lines in the other view. In unsynced videos (right), deviations from the red lines indicate the sync error.
Visit https://t.co/PjGSeJagGe and try the cool demo at https://t.co/oE1FWyb5mP
Don’t miss our poster session on Wed Oct. 22 10:30 #1109
Joint work @chuan_guo92603, Bing Zhou, @_JianWang_, @Snapchat and @IllinoisCDS
Warm hug from the most famous statue at Waikiki beach👇