Palantir CEO Alex Karp on what customers actually want, the real business of frontier labs, and the importance of open source models:
“What the technical customers want is control over their compute, their models, their data stack, and their alpha. They want to know they own the means of production, and it's not being transferred to someone else.”
"Who owns the data? Are the prompts secure? Is this being transferred to you?"
"If it was so valuable, and I can make you a billion dollars, wouldn't I say I'll make you a billion dollars and I want 30%? Why are they charging for tokens if it's so valuable?"
Legacy Media types are calling this Alex Karp interview a “crash-out” so that’s your first clue that he is actually saying something extremely insightful. He is articulating what real “AI safety” looks like in the enterprise.
Not abstract alignment research or certification by a government-run DMV for AI. Real AI safety for businesses is the ability to control their own data, model weights, and compute — so a frontier lab can’t hoover up their proprietary knowledge and turn it into their next product.
As Karp explains, technical customers want “control over their compute, their models, their data stack, and their alpha. They want to know they own the means of production, and it’s not being transferred to someone else.”
Don’t think that can happen? Just look at Figma. According to The Information, Anthropic “blindsided” its then-business partner with the launch of Claude Design. Figma’s founder said Anthropic had not been “consistently honest” with them. Anthropic’s chief product officer had even served on Figma’s board until three days before the launch of Claude Design. Figma’s stock has fallen sharply this year while Anthropic’s valuation has surged.
This isn’t an isolated example. Anthropic has launched Claude Science, Claude Security, Claude Legal, and of course Claude Code — each expanding into categories previously served by companies building on top of their models. The pattern is consistent: watch where value is being created, then move in directly. Dominate the model layer, then use that position to capture the most lucrative verticals.
Dario has argued that open source models powerful enough to compete with Anthropic are “dangerous.” But dangerous to whom? Not to enterprises that want to retain control over their data and workflows. Dangerous to a business model that benefits from customers having few real alternatives at the model layer.
As Karp exposes, true enterprise safety isn’t trusting that a lab’s future roadmap won’t include your business. It’s retaining the ability to choose — at the model layer — who gets to see and use your alpha.
GLM 5.2 DSpark preview is here! ✨
https://t.co/DQOMYEiY1o
This is the first DSpark speculator for a non-DeepSeek frontier model, trained with Speculators and running on vLLM nightly for ~1.5× faster decode for GLM-5.2-FP8 on 4×B300. Stronger checkpoints to come!
Meituan, basically China’s DoorDash, trained a 1.6T parameter LLM on 50K Chinese chips.
It reminds me of Jensen Huang’s point on the Dwarkesh podcast: export controls on Nvidia GPUs won’t stop China. They’ll just accelerate the development of AI that runs on Chinese chips.
👀 vLLM community is working non-stop to get @deepseek_ai's new DSpark spec decode algorithm for vLLM! Faster inference for everyone!
https://t.co/g5zo25aimb
Great to see the @NVIDIAAI Nemotron team put out a step-by-step guide for self-hosting Nemotron-3-Ultra 550B without a datacenter. Four compact DGX Spark boxes pool into a single OpenAI-compatible endpoint, served from vLLM's official out-of-the-box container.
If you're building a private cluster of your own, don't miss this guide:
🔗 https://t.co/6kxdG5Ztde
🤖 Then wire that endpoint into your agent workflows, all on hardware you own.
The best attitude towards AI is treating it like a dumbass to bounce ideas off, which nevertheless helps you think of the correct answer. Much like how House treats his team
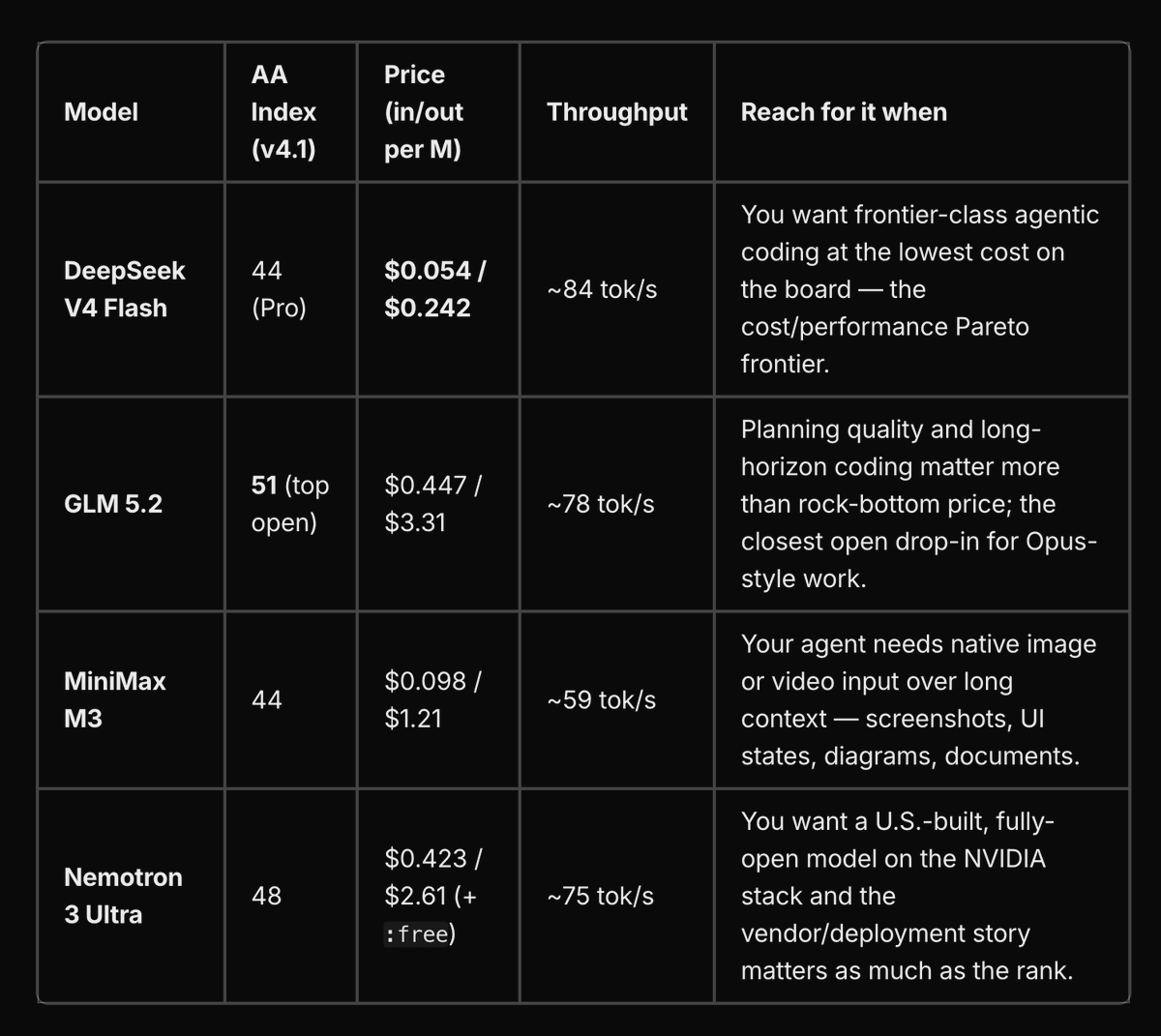
Four open-weight models have crossed into territory where they are powering real agentic pipelines.
New post in our Insights blog about why companies are choosing them in June: https://t.co/zFaXlhdX2M
This is very interesting. Coinbase seems to have lowered their token spend ($$) to about half, by
1) routing to cheap inference like GLM 5.2 and Kimi 2.7 that are still pretty performant
2) Smart routing + caching
They still use the same tokens as before. Start of a trend?
Many smart people/AI insiders are saying GLM-5.2 is the first Chinese AI model to match and often beat the American big lab public AI models with no compromises. Incredible timing given current events.
just had a call with yet another company switching to local ai. they were using Qwen 3.6 35b served through my spark so they could test their pipelines through it and see if its a fit and what i heard in that call is pretty crazy and i feel it is something that most anti-local ai misunderstand.
what the customer told me is literally that they kept comparing the results between Claude, ChatGPT and the locally served Qwen 3.6 and largely preferred the results they were getting via Qwen - insane!
the plan is now to deploy a DGX Spark in their office for the MVP + a 6000 pro blackwell-enabled machine for training & later on they're looking to basically buy a DGX Spark per customer they have so they can serve each customers an optimized finetune.
this is the future. literally. and once again, this is the worst it'll ever be.
Absolutely incredible: GLM-5.2 (max) sits at #3 overall on GDPval-AA, a real-world agentic work benchmark, even ahead of GPT-5.5 (xhigh).
Oh and btw: looks like open source is no longer 7 months behind.
GDPval-AA, a benchmark built around real professional and creative tasks. The models had to produce practical deliverables from identical briefs, including a retail supervisor’s task list, an emergency-stop circuit schematic, and a music video moodboard.
Thats why we'll probably see a big leap with GPT-5.6. Even open source competition is catching up insanley fast.
Query your modern Iceberg lakehouse directly through LLMs using nothing but standard SQL. Eliminate complex #Python notebooks and messy ETL pipelines by leveraging Trino #AI Functions and #RedHat#OpenShiftAI to bring intelligence straight to your data. https://t.co/4l8yIlQvgo
16 parallel runs of Gemma 4 26B A4B on a single NVIDIA DGX Spark!
Pushing 18 tok/s per instance and a 300 tok/s aggregate. It can even hit 32 parallel runs.
This level of concurrency highlights how efficient the architecture is.
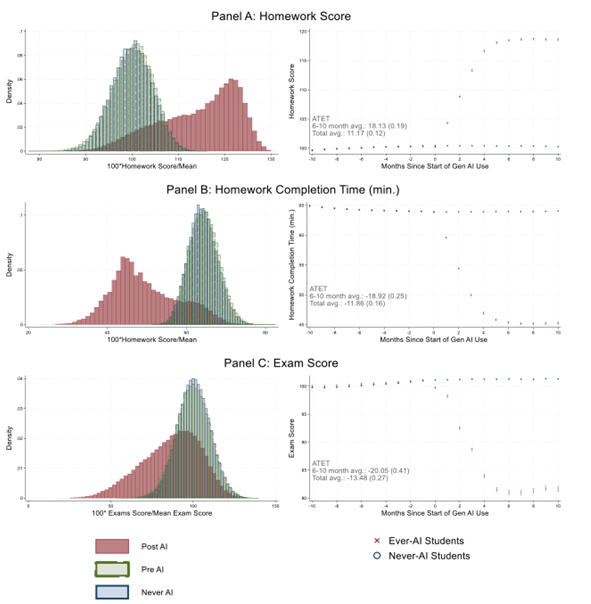
More evidence, from a large-scale study in China, that using AI hurts learning if it undermines mental effort. When homework time drops due to AI use, so do test scores.
Across studies, a theme: AI tutoring in support of classes is good, using AI to "help" with homework is bad.
Maybe the most important chart in the world: the AI arms race.
The question whether a 10% "intelligence gap" which translates into a 90% lower cost, will determine if $5+ trillion in capital is being misallocated