Perplexity just launched persistent memory across sessions: the feature users begged for, but also the one that makes everyone nervous.
The idea: it remembers your preferences, interests, and past convos so you stop re-explaining yourself.
You can view/delete memories in settings, but some users opened theirs and found a long list of inferred habits they never explicitly shared.
Useful? Yes.
Creepy? Also yes.
What research says: Memory-augmented LLMs aren't new.
Systems like Mem0 show ~26% better accuracy and 90% token savings with good memory design.
But the privacy trade-offs: aggregated memories can reveal sensitive stuff users didn't mean to expose.
Perplexity's Team: Encrypted, avoidable (incognito mode exists), but deleted memories linger in logs for ~30 days and feed model training unless you opt out.
Do you turn memory ON or keep it OFF?
We've been testing Memory (short-term and long-term) on Perplexity for a while. The results are great, and we are rolling it out widely. You can ask personalized questions, questions about past chats, and use any model or search mode with personal context (both apps and web).
Just saw this from Andrej Karpathy and it hit hard.
We all keep scrolling through these quick “learn AI in 10 minutes” or “master Python while brushing your teeth” videos.
They feel good in the moment- entertaining, easy and you walk away thinking you did something productive.
rereading docs and fixing your own mistakes. The convenience is addictive but the retention is almost zero.
I’m trying to remind myself: if I’m learning just to feel productive, I’m probably not learning.
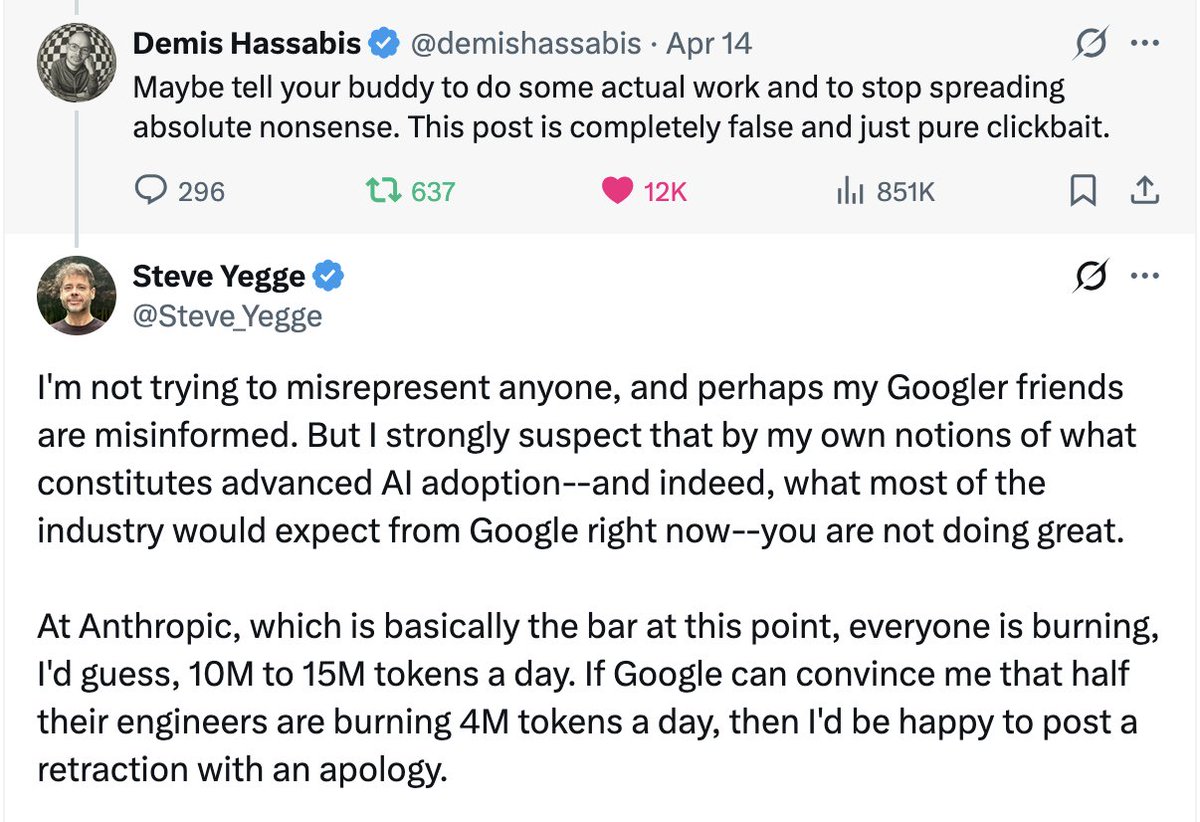
Just came across this old post between Steve Yegge and Demis Hassabis from a couple months back.
Yegge basically said real AI adoption means engineers are burning millions of tokens a day (like at Anthropic levels) and Google wasn’t there yet. Demis called it nonsense and
Ok now that tokenmaxxing is starting to get its fair share of criticism properly.... imagine reading this exchange all over again. 😅
"you are not a good engineering company unless you can convince me that your engineers are burning infinite tokens"
clickbait.
Fast forward to today companies are quietly killing their internal AI leaderboards because “tokenmaxxing” became a thing.
People gaming the system with pointless tasks just to rack up numbers, burning cash with zero real output. Amazon and others are pulling back.
Just saw this take from Theo and it actually got me thinking.
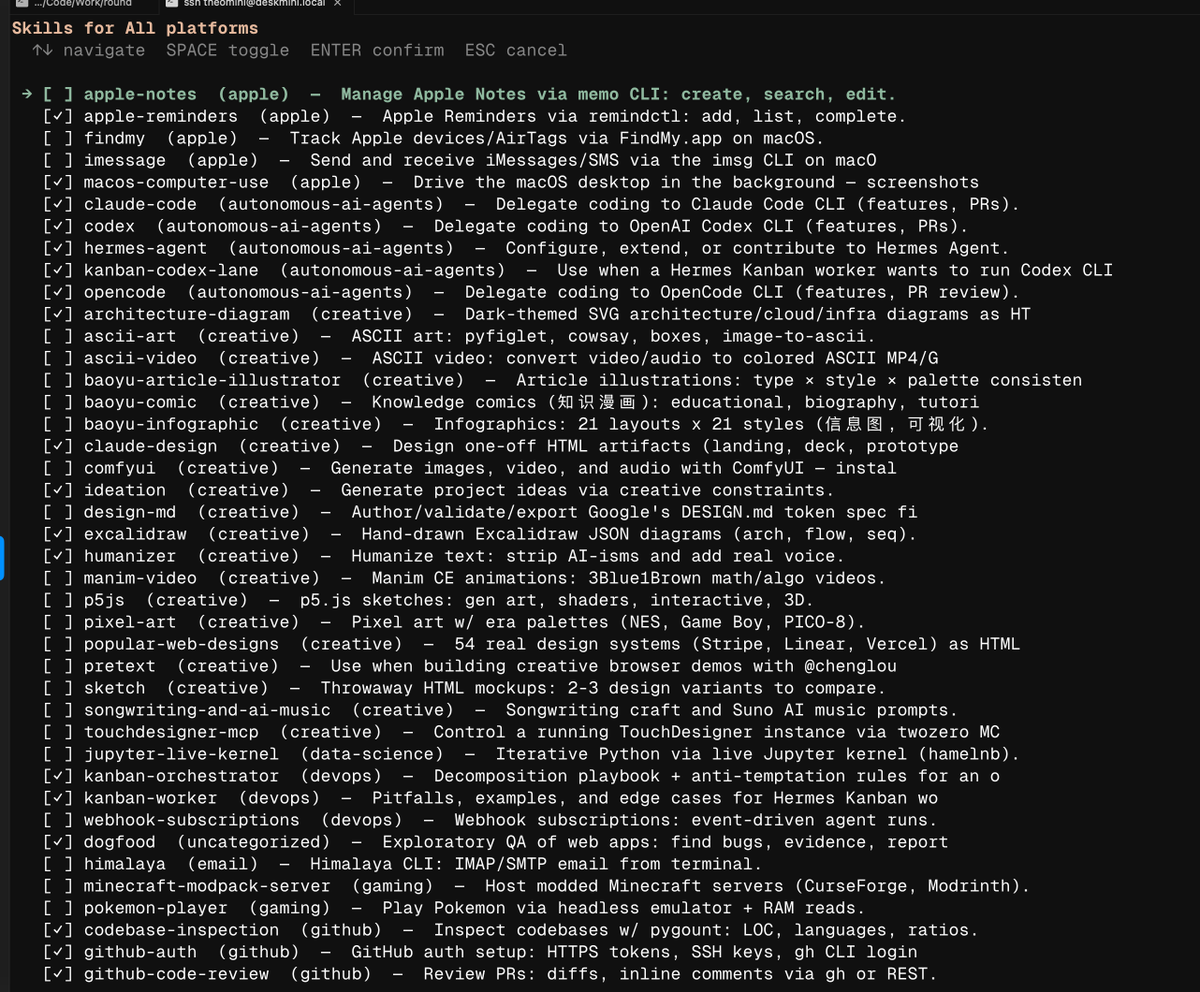
Hermes Agent comes with over 100 specialized skills turned on by default stuff like Polymarket betting, some Baoyu art tools, headless Pokemon gameplay, even Minecraft server management.
On paper it sounds impressive
Hermes Agent comes with a truly absurd number of skills pre-enabled. Over 100 of them. This is roughly half.
I get what they're going for - they want an agent that comes "ready out of the box".
I just don't get why every user has to have a polymarket skill, 3 baoyu art skills (? never heard of this), a headless Pokemon skill, and Minecraft modpack server skills, all available the first time they run it.
I guess Hermes Agent just isn't for me.
like a super ready to go AI. But honestly? It feels heavy.
All that extra stuff sitting in the context window, probably increasing the chance of random activations you didn’t ask for. I get why some people might want everything pre-loaded,
One thing that clicked for me while reading about harnesses:
For agentic tasks, the execution layer is not just infrastructure. It influences the behavior.
Same model. Different harness. Different trajectory.
One thing that clicked for me recently:
Feature engineering didn’t really go away.
Before, we engineered features.
Now, we engineer architectures that learn features.
CNNs, Transformers, GNNs…
Each comes with its own assumptions about the data.
Still learning this area, but it changed how I think about deep learning.
But he pointed out something pretty obvious once you hear it: you’re burning money on heavy models for stuff that doesn’t need it.
Like, use Haiku for quick simple tasks, Sonnet for normal everyday work and only pull out Opus when you actually need deep thinking.
Just watched a bit of Dario Amodei talking about Claude models and it honestly made me rethink how I’ve been using them.
Most of us (me included) just default to the strongest model every single time because why not, right?
Anthropic CEO Dario Amodei:
"The cheapest way to use Claude is also the smartest. Most devs do the exact opposite."
In 36 minutes, he breaks down the real economics behind every Claude model, and why running them all the same way is a mistake.
Watch the full interview, then save the config below 👇