RL/ML papers love equations before intuition. This post attempts to flip it: each idea appears only when the previous approach breaks, and every concept shows up exactly when it’s needed to fix what just broke. Reinforcement Learning for LLMs ("made easy") https://t.co/VMONTwPeXE
Introducing Claude Fable 5: a Mythos-class model that we’ve made safe for general use.
Its capabilities exceed those of any model we’ve ever made generally available.
We’re bringing new capabilities to GPT-Rosalind, a model series purpose-built for life sciences research at enterprise scale.
It brings GPT-5.5’s agentic coding and tool use together with stronger intelligence for drug discovery, analysis, design, and experimental workflows.
https://t.co/SrAJ3Mt7ka
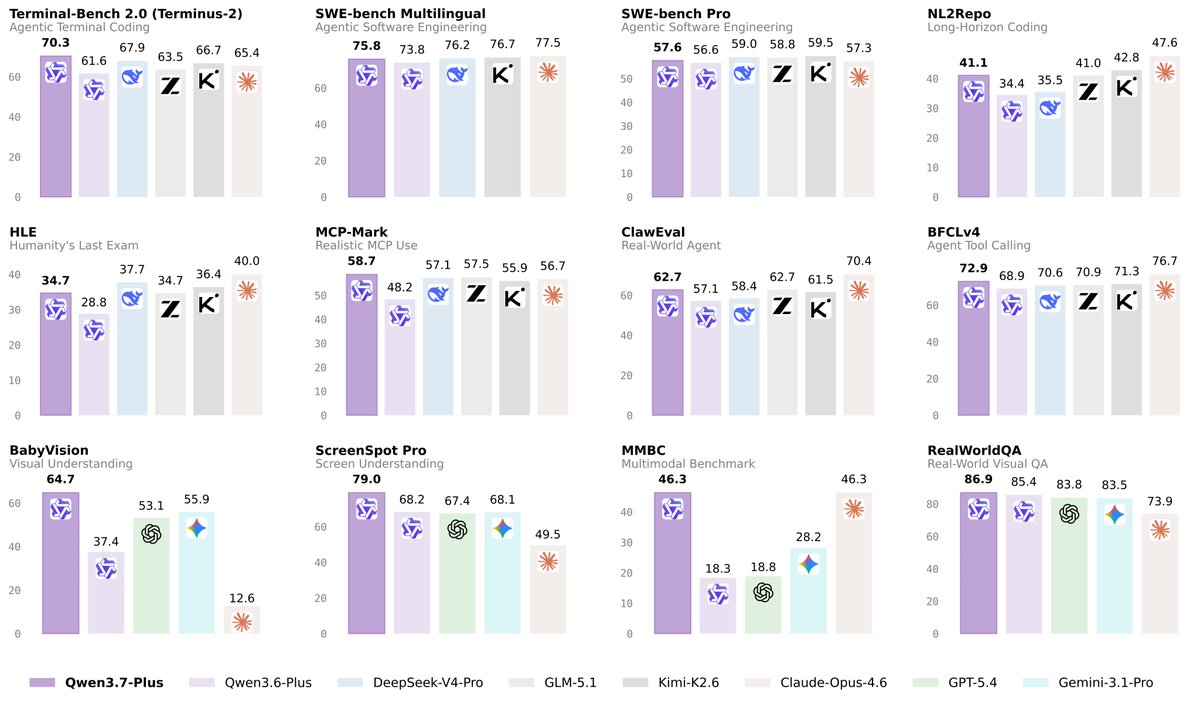
👏👏 Introducing Qwen3.7-Plus — a multimodal agent model that unifies vision and language into one versatile agent foundation.
✅ Multimodal interactive hybrid agent: unified GUI & CLI operation across visual and text tasks
✅ Versatile coding agent & productivity assistant with full-modality input
✅ Visual Agent: perception, reasoning, grounding, and search-augmented QA
✅ Cross-harness generalization across diverse agent frameworks
One model. Sees, thinks, codes, acts.🙌🙌
Now available via API on Alibaba Cloud Model Studio. Try it — let us know what you build.😎
🔗🔗⬇️⬇️
Blog:https://t.co/pVYf0h3NNa
Qwen Studio:https://t.co/HUYgFW4cYf
API:https://t.co/viL0cXrMzW
🚀 Self-speculation brings 6.75x real speedup for LLM generation with SGLang inference!
Same model drafts future tokens in Diffusion mode → then verifies them in AR (causal) mode. One model and one KV cache. Just different attention masks.
Thanks to perfect alignment, we get 2× longer acceptance lengths than MTP techniques (Eagle-3, MTP, dFlash).
We run 2 forward passes… but the 2× higher acceptance means we break even - and with zero overhead from extra drafter, KV cache, or LM head that comes with MTP - those are not free.
Last week we released Nemotron-Labs-Diffusion + Tri-mode LLMs! We did continued pre-training on Ministral-3 models by switching attention patterns (block causal <> bidirectional). Result: one model that runs AR mode, Diffusion mode, and Self-Speculation.
Diffusion mode already shows high benchmark accuracy - excited to see what happens when someone beats left-to-right acceptance! 🔥
Github: https://t.co/Zqbw3KcAyF
Paper: https://t.co/rp86A7D0xJ
SGLang inference: https://t.co/uTgZPALEJl
Try the models on HF: https://t.co/1zStcCCWPi
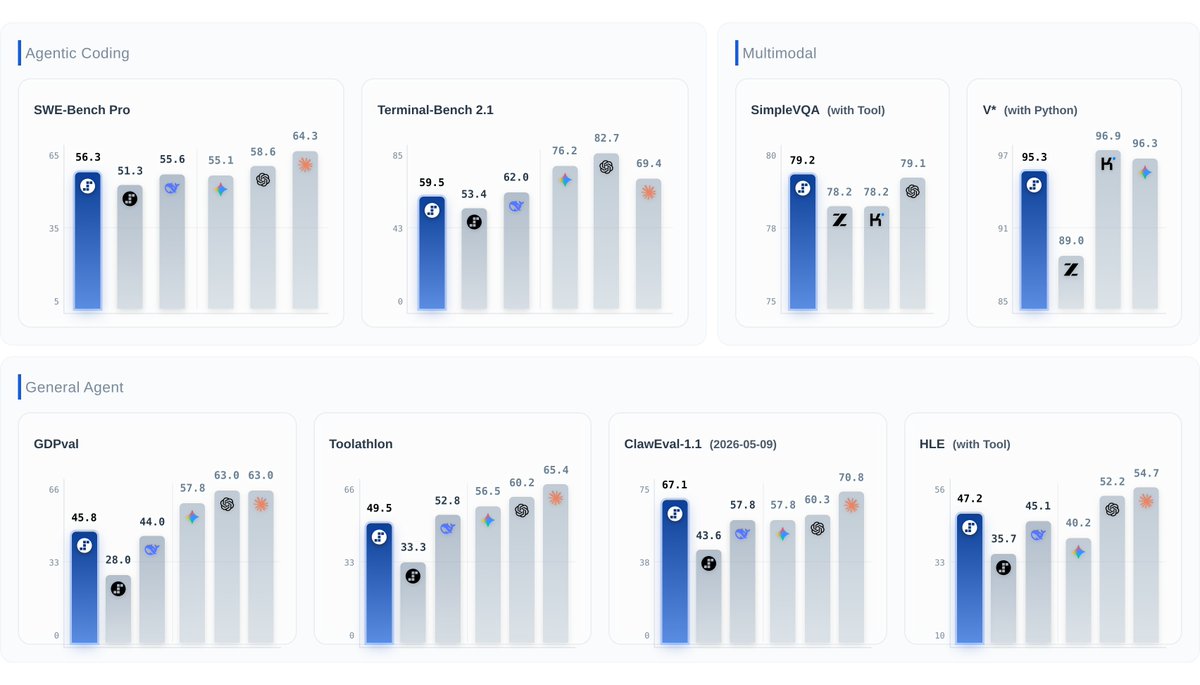
⚡️ Step 3.7 Flash is here: The new frontier is agent efficiency.
#1 ClawEval-1.1 (67.1), #1 SimpleVQA Search (79.2), #2 SWE-PRO (56.3), 95.3 on V* Python. Open weights under Apache 2.0.
Built for agentic, coding, search, and multimodal workflows — balancing speed, cost, and reliable execution.
- 400 TPS. 198B sparse MoE, ~11B active. 256K context, 3 reasoning levels.
- Understands UIs, charts, docs, images — then writes code or calls tools to act on what it sees.
- Web + visual search reaches further: more sources, deeper follow-up.
- Reliable tool use — less drift, fewer broken toolcalls. 98%+ on τ²-bench across all difficulty levels.
- Works with Claude Code, KiloCode, Hermes Agent, OpenClaw, and protocols like MCP.
- Runs locally on Mac Studio M4 Max, DGX Spark, AMD AI Max+ 395.
GitHub: https://t.co/kqlZkVIRHv
HuggingFace: https://t.co/qqceCrgPiw
GGUF: https://t.co/rR6XrnymWG
ModelScope: https://t.co/wney6Tzvqy
API: https://t.co/RvHWzRG7Fu
Blog: https://t.co/BxDiajiQ5G
100% agree. AlphaGo raised the ceiling for Go; LLMs are lowering the floor for learning (math/engineering/science etc..). Curiosity is the new bottleneck along with, of course, the cost of tokens.
Introducing Claude Opus 4.8: it builds on Opus 4.7 with sharper judgment, more honesty about its own progress, and the ability to work independently for longer than its predecessors.
Available today at the same price.
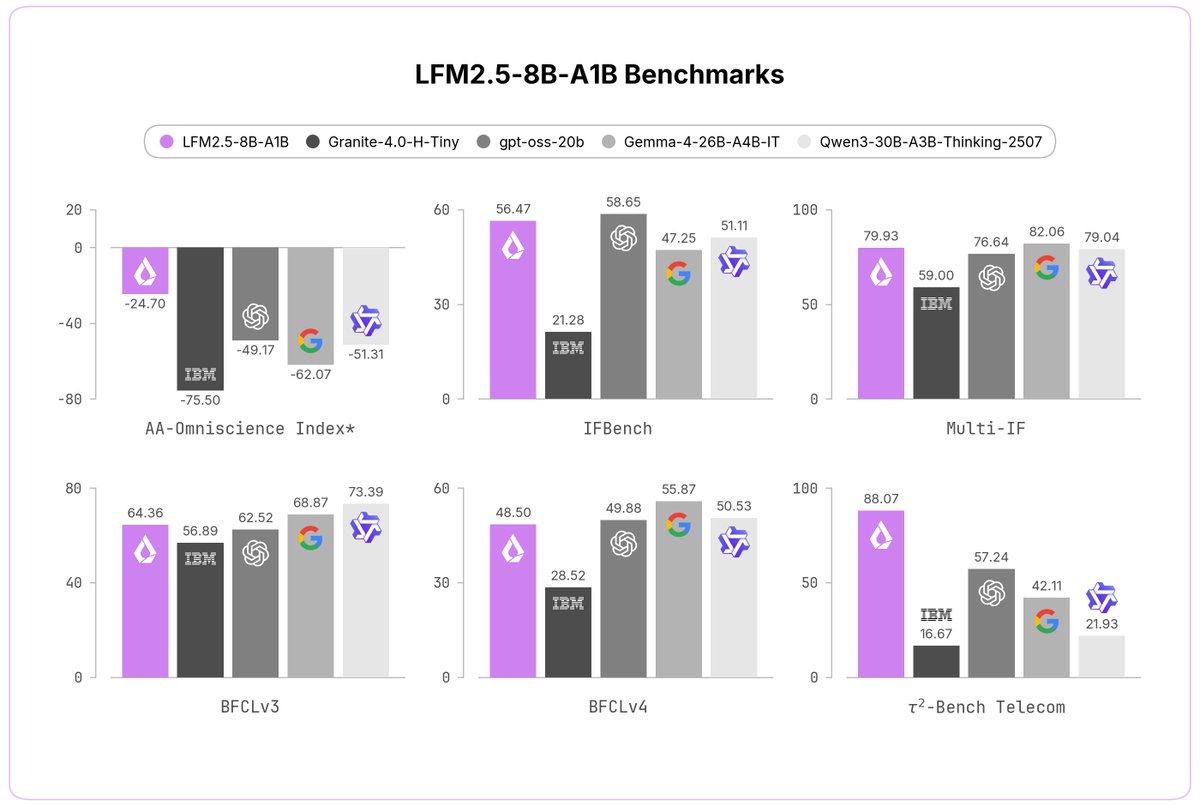
Today, we're releasing LFM2.5-8B-A1B, a device-optimized model designed to power real-life applications on phones, laptops, PCs, robots, and fast & lightweight server-side use-cases.
> 8B MoE, 1.5B active
> Expanded 128K context
> LFM2.5 flagship hybrid MoE architecture
> Trained on 38T tokens + large-scale RL
> fast, reliable tool calling, punching above its weight, comparable to models with up to 4x its size
> customizable on a single GPU for any specialized task
> LFM2 open-weight license
🧵
8/ The bigger lesson for me:
The value of recommendation foundation models is not just “bigger model = better recommender.”
It is that heterogeneous signals — watches, searches, sessions, surfaces, containers, time — can live in one shared sequence model and reinforce each other.
How Tubi is using foundation models to power recommendations at scale: https://t.co/X6fdNjbc96.
This is one of the projects that got me fully LLM-pilled. @MikeTamir
7/ The search result is especially interesting.
Search queries are often short, partial, ambiguous, or title-seeking. By combining query tokens with the viewer’s prior journey, TubiFM can use behavioral context when lexical evidence is sparse. That is where foundation-model-style recommenders start to feel very natural.