NEW POST
When we gradually replace a legacy system, the legacy and its replacement need to interact. Ian, Rob, and James explain how we can use Event Interception to integrate the replacement while minimizing difficult changes to the legacy.
https://t.co/vylvea08S7
One of the main complaints people seem to have about the Clean Code book is my advice to keep functions very small. In Java I prefer functions that are ~4-6 lines long. (Thats a preference, not a demand).
Why? Because this forces me to make each function about _one thing_ and give each a very descriptive name.
Over the years I have found this to be a very beneficial technique both for enhancing readability and for deriving good designs.
Writing tests doesn't reduce project velocity. Skipping tests gives a false impression that you may be making "progress."
However, without validating the business requirements, velocity is meaningless, as it doesn't measure the actual progress but the level of hope.
It can be quite annoying that #Java doesn't allow statements before the super(...) or this(...) call in a constructor. 😤
The latest Inside Java Newscast with @nipafx looks at how #Java22 is about to change that. 🤗 https://t.co/ccpTWEKpo2
Retry Pattern is a popular pattern to achieve Resilience in Distributed Systems.
But people use it wrong all the time.
Here are 4 things to keep in mind when using the Retry Pattern correctly.
The Retry Pattern is a design approach used to enhance the reliability and resilience of software systems by automatically reattempting a failed operation or request.
1. Set a Reasonable Retry Limit:
Determining the right number of retries is critical.
Too few retries might not allow temporary issues to be resolved, while too many retries could lead to excessive load or long delays in recognizing a persistent problem.
Consider your operation and the expected duration of transient failures to decide on an appropriate retry limit. I never go over 3 retries.
2. Implement Exponential Backoff:
Instead of retrying immediately, implement an exponential backoff strategy.
This means that after each failed attempt, you increase the time before the next retry. This prevents overwhelming the system and gives it time to recover.
Exponential backoff helps avoid a stampeding herd effect where all failed requests suddenly hit the system simultaneously after a short time.
3. Identify Retriable Errors:
Not all errors are worth retrying.
Focus on retrying only transient errors:
- 408 Request Timeout
- 5XX (Server did something bad)
Avoid responses like:
- 400 (Bad Request)
- 403 (Forbidden)
They are not recoverable, so retry logic shouldn’t retry them.
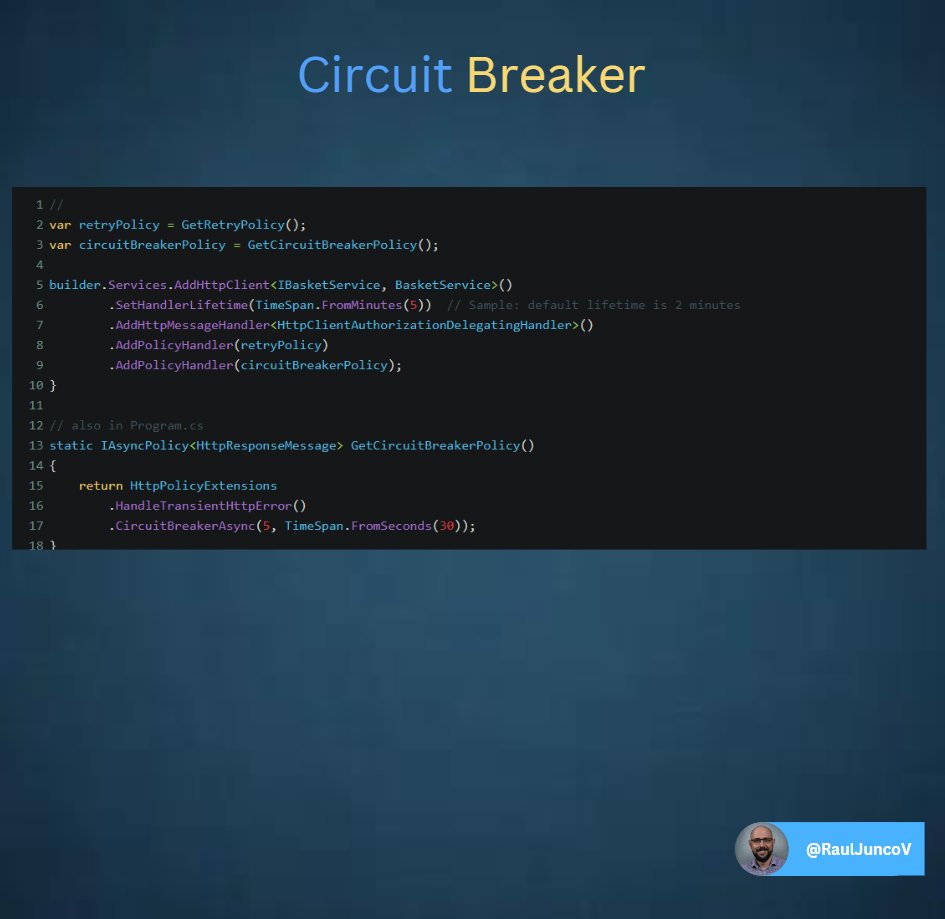
4. Combine with Circuit Breaker:
The Retry Pattern works well when combined with a circuit breaker mechanism.
A circuit breaker monitors the health of a service and prevents repeated calls to a failing service, which could worsen the situation.
If a certain threshold of failures is reached, the circuit breaker opens, temporarily preventing further requests. This gives the service time to recover before attempting retries again.
Remember that the goal is to gracefully handle transient failures and maintain the overall stability of your application.
Meet Marvin: a batteries-included library for building AI-powered software. Marvin's job is to integrate AI directly into your codebase by making it look and feel like any other function.
https://t.co/B9fC8krdNd
























![details_with_ai's tweet photo. SQL Interviews Questions & Answer You Should Know : 👇
[Bookmark For Future Reference] 🧵 https://t.co/wG409DRqEj](https://pbs.twimg.com/media/F7z_6htaMAAYIoC.jpg)