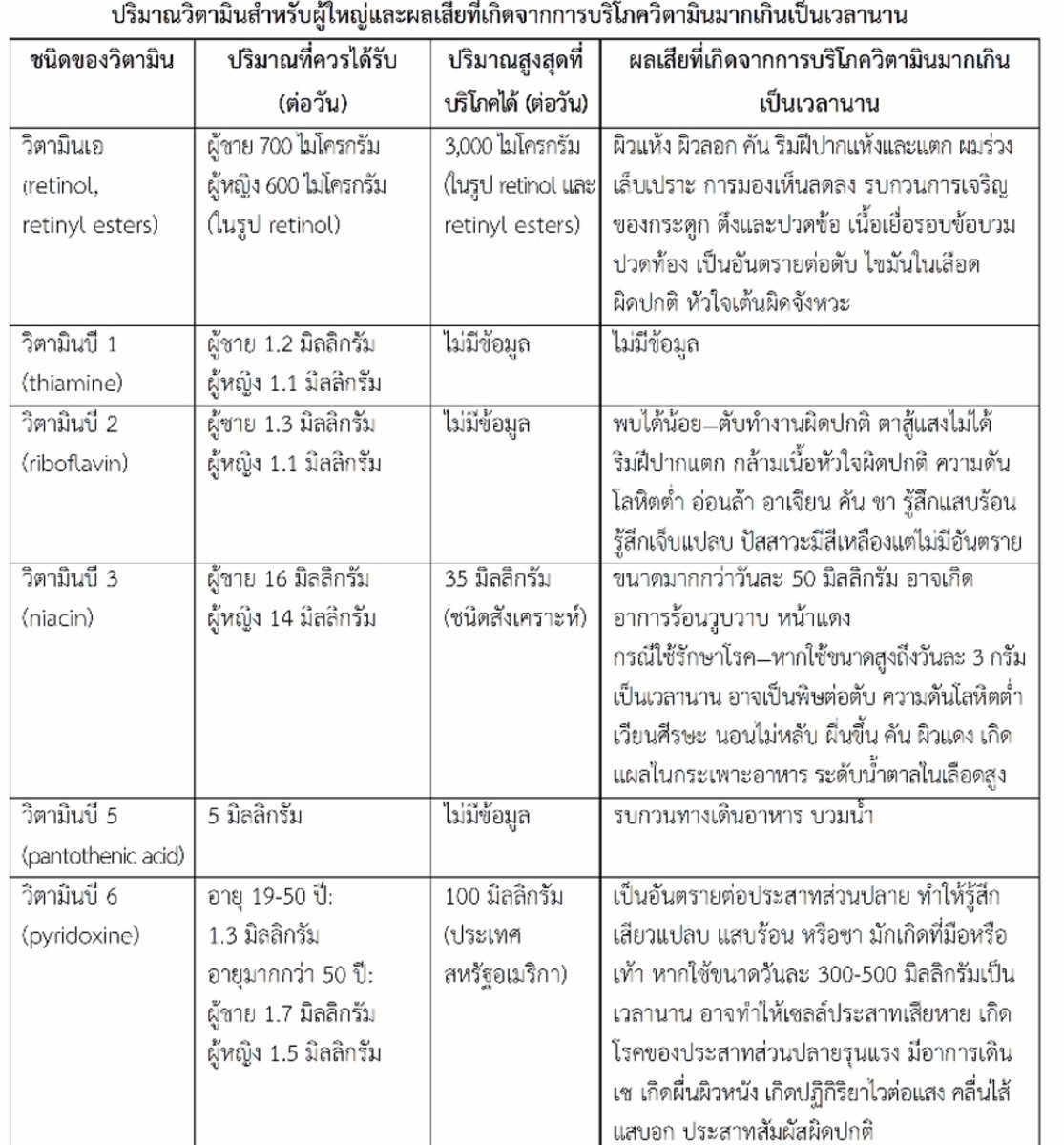
[Tip de R] · [Paquete 📦] · FakeDataR: Generá datasets sintéticos que cuidan la privacidad, espejando la estructura de tus datos reales.
¿Necesitás compartir un dataset para pedir ayuda, desarrollar un modelo o testear tu código, pero te preocupa la privacidad de los datos originales? ¡Olvidate de editar a mano y arriesgarte a exponer información sensible! El paquete FakeDataR te permite crear copias sintéticas de tus datasets que imitan la estructura, tipos de datos y niveles de factores, pero sin la información sensible. Es la solución perfecta para trabajar de forma segura y eficiente.
✔️ Generá datasets sintéticos que mantienen la estructura (esquema, tipos, niveles de factores, rangos y valores faltantes) de tus datos originales, ¡pero con contenido "falso"!
✔️ Prepará bundles de datos sintéticos con esquemas JSON y guías, listos para usar directamente con Large Language Models (LLMs), agilizando tus workflows de IA.
✔️ Construí datos falsos directamente desde tablas de bases de datos SQL sin necesidad de leer las filas reales, protegiendo la privacidad desde el origen.
✔️ Tené el control para enmascarar o eliminar campos sensibles, asegurándote de que solo compartís lo que es seguro.
💡 Tip
Usá FakeDataR para crear entornos de desarrollo y pruebas seguros. Podés compartir estos datasets sintéticos con colaboradores o LLMs sin riesgo, ya que todo el proceso ocurre en tu máquina, ¡sin subir tus datos reales a la nube!
🔗 https://t.co/o42kSUSh0G
✍️ Zobaer Khan
#RStats #RStatsES #Rtips #DataScience












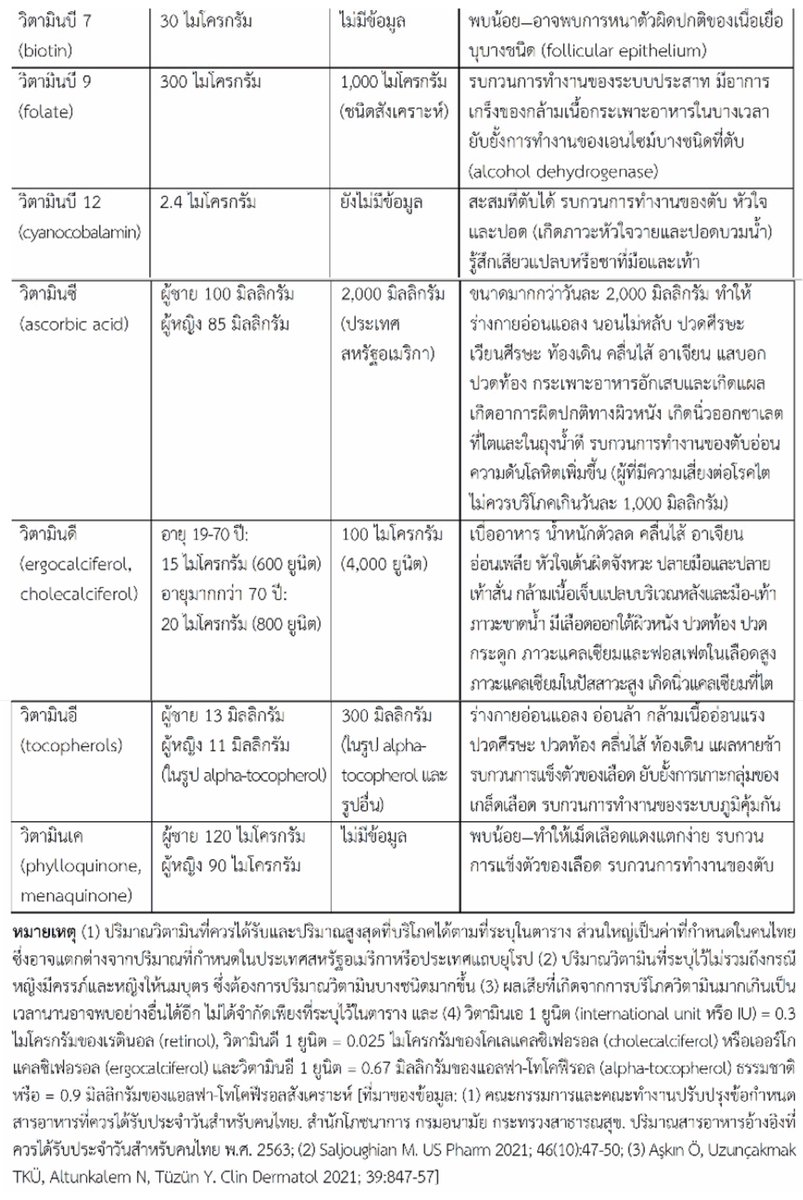




















![estacion_erre's tweet photo. [Tip de R] · [Paquete 📦] · FakeDataR: Generá datasets sintéticos que cuidan la privacidad, espejando la estructura de tus datos reales.
¿Necesitás compartir un dataset para pedir ayuda, desarrollar un modelo o testear tu código, pero te preocupa la privacidad de los datos originales? ¡Olvidate de editar a mano y arriesgarte a exponer información sensible! El paquete FakeDataR te permite crear copias sintéticas de tus datasets que imitan la estructura, tipos de datos y niveles de factores, pero sin la información sensible. Es la solución perfecta para trabajar de forma segura y eficiente.
✔️ Generá datasets sintéticos que mantienen la estructura (esquema, tipos, niveles de factores, rangos y valores faltantes) de tus datos originales, ¡pero con contenido "falso"!
✔️ Prepará bundles de datos sintéticos con esquemas JSON y guías, listos para usar directamente con Large Language Models (LLMs), agilizando tus workflows de IA.
✔️ Construí datos falsos directamente desde tablas de bases de datos SQL sin necesidad de leer las filas reales, protegiendo la privacidad desde el origen.
✔️ Tené el control para enmascarar o eliminar campos sensibles, asegurándote de que solo compartís lo que es seguro.
💡 Tip
Usá FakeDataR para crear entornos de desarrollo y pruebas seguros. Podés compartir estos datasets sintéticos con colaboradores o LLMs sin riesgo, ya que todo el proceso ocurre en tu máquina, ¡sin subir tus datos reales a la nube!
🔗 https://t.co/o42kSUSh0G
✍️ Zobaer Khan
#RStats #RStatsES #Rtips #DataScience](https://pbs.twimg.com/media/HIwulaVXAAAKK_i.jpg)