PPO had a second wave in the LLM era for reasons unanticipated by the original paper
- the importance-ratio objective fixes biases from numeric error, async training, and forward pass noise
- the clipping objective affects entropy through a mechanism that we didn't know about at the time of publication (DAPO, https://t.co/sBo9DeFS5Y)
i'm having a really hard time understanding how this can be a good decision
> lying to the user by modifying the weights/prompt sets a very bad precedent and is extremely unaligned
> there is 0 public communication from anthropic about it except a section hidden in a 319 page system card
> it's impossible to know the scope of this safeguard. if you are doing a PR to pytorch does this count? if you are working on kernel development? data collection pipeline for a new eval? this will create a paranoia for every researcher in the field
> you actually don't know how your model is modified, if it's PEFT (modification at the weight level) or steering does this mean your other queries are also biased? is it at the user level or organization level?
there is also the more "moral" argument that the reason why anthropic is able to train this model is ai researchers who will not have access to the model's capabilities anymore. even if you consider that this is the right thing to do, doing it like that is just a lack of respect to the ai research community
in addition to all of that, it's not clear if the safeguard acts on "model autonomy" or "model capabilities" to do ai research. this is very different and my understanding is that it's the latter, and there is almost 0 RESULTS about this in the system card except a vague "2.3.6 Internal measures of AI R&D acceleration" section citing the previous RSI blog so let's look at it:
the only eval targeting research shows a ~5 point improvement between opus 4.8 -> mythos, but opus 4.7 -> opus 4.8 was a 4 point improvement. obviously not the same if the 5 point improvement led to solving significantly harder tasks, but then, let's be transparent about this evals and make it more details: difficulty filtering, example of what it could look like from public library?
the other AI R&D capabilities evals in the system card are actually not relevant anymore according to anthropic's own words:
"Claude Mythos 5, like Claude Mythos Preview and Claude Opus 4.7, exceeds top human performance thresholds on all but one of these tasks. The suite therefore no longer provides evidence that the model's capabilities are short of our risk thresholds"
only one that is not saturated is the "Novel Compiler" one, if you look at LLM training one (which they consider saturated) it's about how much the model can speedup the training of a small model on a CPU, i don't think anyone would say this is a good proxy for taking a decision to restrict capabilities of the model for ai researcher
idk honestly this feels wrong at so many levels
@eliebakouch Wonder if "frontier llm development" include any deep learning pipeline optimization or specifically for llms.
like is it nerfed for JEPA research, optimizers research, new archs, etc...
mythos will be bad ON PURPOSE on ai "frontier llm research" tasks, this is very very sad for the research community
also the fact that this is un purpose not visible to the user is crazy
Introducing Claude Fable 5: a Mythos-class model that we’ve made safe for general use.
Its capabilities exceed those of any model we’ve ever made generally available.
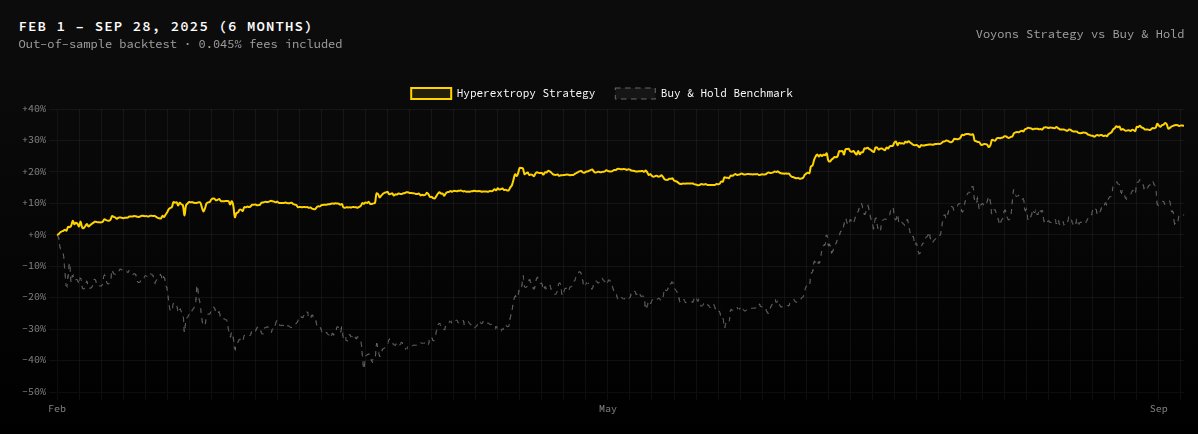
Excited to share that I've joined @DuonLabsHQ as a strategic advisor.
Here's what they're building:
A foundation model for markets, not language
models that train and retire their own models
every trade settled on-chain, verifiable in real time
The traction is real:
✅Signals live in @CoinStats (3M+ views),
✅Strategies running: @HyperliquidX+@megaeth_devs
✅200+ devs waiting on the API.
Frontier labs scale by hiring. Duon Labs scales by compute. That quietly changes the economics of running money.
Where I think it goes from here👇
> people anthropomorphize literally anything
OpenAI products heavily leverage anthropomorphisms to improve UX and retention
OpenAI introduced the very idea of talking to a model through a chat, the UI humans used for talking to each other
OpenAI also introduced "You" being the first word of the system prompt with "You are ChatGPT, a large language model developped by OpenAI"