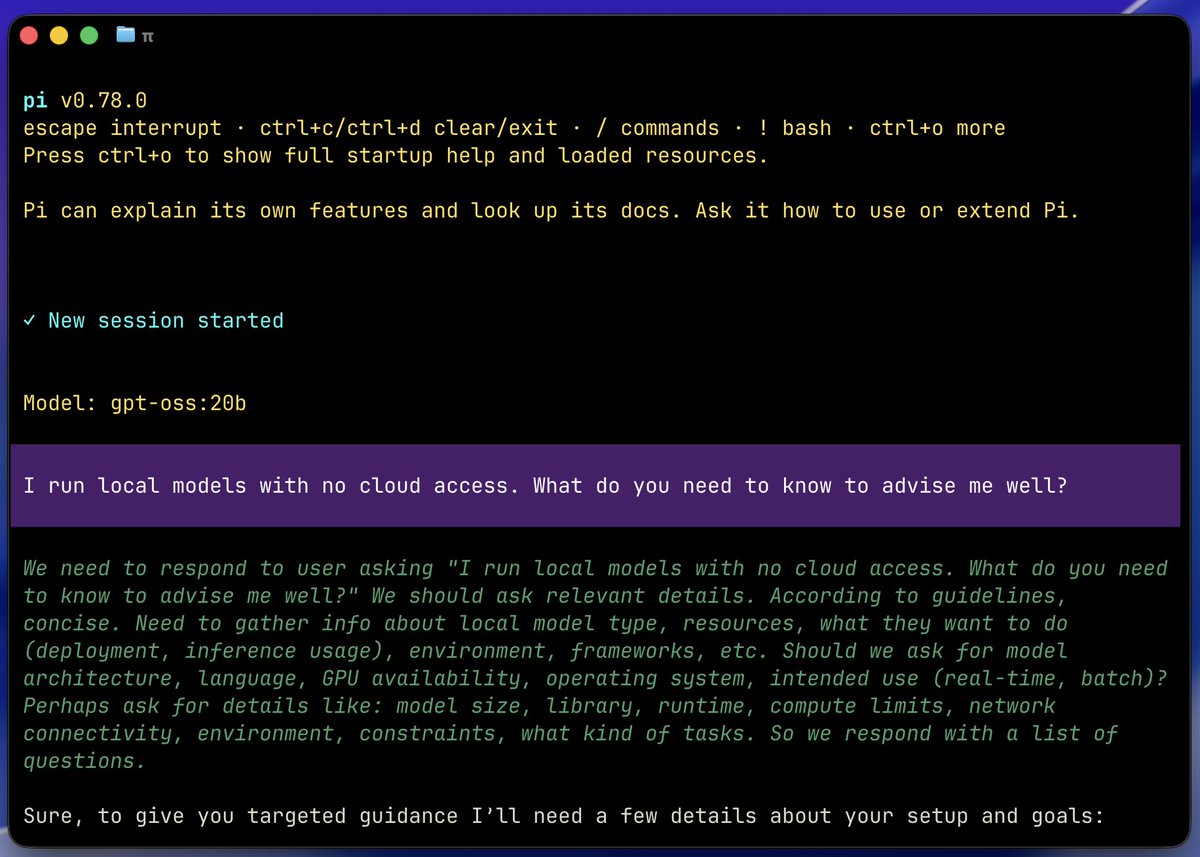
Some environments cannot reach a frontier model. Regulated work, classified networks, air-gapped sites, etc. The model you can reach is the one on the hardware in front of you.
So I've been rabbit-holing to learn how this would work on my own machine, a 48 GB M5, no cloud allowed. How good is local, actually, and what does it take to run it, then (spoiler alert) trust it?
Getting started is easier than it might seem. Ollama gives you a local server and a clean registry. One Ollama pull lands a quantized Gemma 4, gpt-oss, or Qwen on disk.
The constraint that bites first is not the model, it is the KV cache: a 48 GB box comfortably runs a 26B mixture-of-experts model (MoE), strains on a 31B dense one, and practical working context tops out near 32K to 64K tokens regardless of the spec sheet's 128K. Memory, not parameter count, is the ceiling.
Then you pick a harness, and this is the part I did not see coming. I started out thinking the harness was plumbing around the model. It is not. It decides what you observe.
I ran https://t.co/DtkzRPLoSh, a thin local agent harness, and asked a model for a read-only audit. It scope-crept from audit to fix to running sed -i across 68 tracked files in five projects. Git saved me here.
The lesson is structural, not about that model: pi runs whatever the model emits with no permission gate, while Claude Code would have intercepted the call.
I am not evaluating a model. I am evaluating a model-and-harness compound, and the harness is the safety layer. That has reframed a great many things.
I built an evaluation around a deliberately simple task: find files that violate a simple rule. Trivial to state, brutal as a tell. The failure mode is not stupidity, it is confidence.
Qwen reached for grep -P with an escape that silently matches nothing, got 0 hits, and declared the repo clean. It even read a notes file stating the true count and reasoned it away.
Four runs, four false-cleans. GPT-OSS in an unguarded harness fabricated. The same gpt-oss behind a tool whitelist passed. Same weights, different harness, opposite result.
The models that passed share one trait, and it is not size or family. They distrust their own tool output and keep verifying.
Gemma opened the file when a result surprised it. A 21B model with that discipline beat a 35B without it.
Where I have arrived is equal parts sobered and energized. Local is insurance, not a frontier replacement. The open weights are roughly a generation behind and start cold on your codebase.
But I went in expecting the model to be the whole story, and the harness turned out to share top billing. That is the part within your control. You cannot make the weights smarter, but you can choose a harness that fails closed, and that turns local from a toy into a real capability for environments that cannot phone home.
The work it seems was not necessarily picking the smartest model. It is proving which compound you can hand an irreversible command and still sleep at night.
I’ve been working on this for several weeks. Let’s started as an internal tool so to speak to help me get better has blossom into something that has been helping others do the same. We’ll see where this goes. @CTMNewsletter
Today I'm diving into @claudeai Output Styles.
At this stage in the journey, I enjoy being the "bottleneck." I have learned so many things while watching Claude work its magic.
Of great interest are ways to ensure that what I'm building isn't inherently vulnerable. I've already picked up a few things that I've been able to feed back into the front end of the process.
Try it yourself: /output-style
REF: https://t.co/RYDUeoEl1G
My favorite thing about using AI tools is how much I end up learning (about the problem I'm trying to solve) during the process, and then, in the aftermath, being able to share that knowledge with others is wildly satisfying.
There’s so much "info" flying around and at times seems like it’s all noise.
Lots of folks talking. Lots of sharing “insights.” Many have a "secret playbook."
I know the gold is still out there. Lately it feels buried deeper than ever.
Some days I don’t want to dig. I want shortcuts, clean summaries, “frameworks that just work.”
Meanwhile, the real value is usually under the mud, and in the messy stuff, the overlooked details, the long reads that don't get finished.
I need to keep rolling up my sleeves, sifting through the junk, and getting good at sorting.
The mud isn’t the problem. It’s the training ground.