In 2016 I worked on a 1 million container challenge while working on Nomad at Hashicorp. We spun up a million containers in 5-7 minutes and keep them running for an ~hour and show our users Nomad can run large clusters at steady state.
10 years later doing this at a smaller scale with @computesdk - 100k but the constraints are different - spin up 100k sandboxes in a minute, running 100k commands on them and shut them down.
This test stresses every aspect of our VM infrastructure platform - the scheduler has to bin pack 100k sandboxes, the authentication proxy and Cloud NLBs have to handle a burst of 100k connections.
Interestingly more than anything the networking has proven to be more of a bottleneck than our scheduler or data-plane infrastructure. NLBs have to be primed to handle such a burst, and then HTTP2 connection pools between services to not kill the machines with a barrage of requests.
We will need to find a better word than "Sandboxes" to describe Tensorlake's platform. We are building VM infrastructure on steroids for agents, serverless functions, CI, running apps and soon going to support GPUs.
Running unstressed code with controlled network access is one of the many applications of the platform.
A few architectural choices we made for Tensorlake sandboxes are helping us move quickly now -
1. Runtime environment driver architecture on the dataplane. This lets us run CloudHypervisor, Firecracker, and gVisor transparently for different use cases using the same control plane.
2. Dataplane and Control Plane separation via outbound mTLS connections. We can bring up a BYOC deployment in private clusters in under 15 minutes.
3. Durable sandboxes with a focus on optimizing snapshot restore speed. This has been a game changer for resuming coding agent sessions, automatic build caches for CI use cases, and for debugging RL environments.
4. A workflow for working with Docker images and building VM images from Dockerfiles.
5. A dynamic cluster scheduler optimized for high-throughput server-less functions and sandboxes. A single scheduler can support dedicated machines for customers and shared machines for general cloud usage.
At the time of building all this, it felt we were just plumbing but it's paying off now as we scale.
A lot has changed in @tensorlake Sandboxes over the past few weeks.
From benchmark-leading startup times to stateful remote dev environments, Harbor integration upgrades, OCI image support, and native SSH access — here's a roundup of the latest updates.
https://t.co/BS4gItuPCL
made overview of sandbox providers, but only from official sources (docs, web)
https://t.co/maRjv0aaVo
There is a lot of slop and 100% false claims circulating about sandboxes today. I dont like slop.
this took me 5 mins and three comments to my Droid, and is open to PRs if you have more accurate info. goal is truth.
Exciting to see the community building real agent workflows on Tensorlake Sandboxes.
This one covers persistence, browser automation, latency measurements, and practical lessons from long-running agent execution. 🚀
#AIAgents#Sandboxes#ComputerUse
@diptanu and team know what they're doing, we're quite careful in testing providers before we support them in mistle.
here's a @tensorlake sandbox booting up in ~1-2s from a snapshot that contains 21GB of stuff (nix, node, rust, crates, node modules, docker images, etc.)
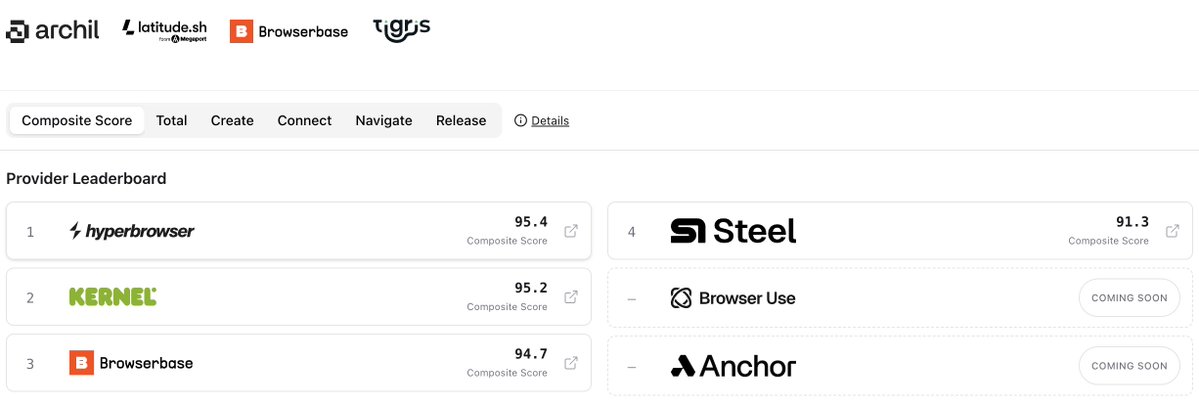
Tensorlake is leading the @computesdk benchmarks. We have been focused on building a best-in-class sandbox infrastructure platform for agents, pairing high performance with the flexibility to support everything from agent harnesses and RL environment simulation to stateful VMs for coding agents.
We built a cluster scheduler optimized for stateful sandboxes that can make thousands of placement decisions in under 5 milliseconds. It achieves this performance using copy-on-write indexes and replicated state machines.
The remaining ~200–250 milliseconds are spent issuing a command to the data plane, creating a disk, and bootstrapping the rest of the VM infrastructure.
Tensorlake is also exceptionally fast at resuming suspended sandboxes, waking from sleep in 1–2 seconds. This enables coding agents to install dependencies, do their work, suspend to release compute resources, and resume quickly to start new tasks without reinstalling dependencies or re-downloading artifacts.
Tensorlake also includes a high-performance sandbox file system, which speeds up compilation for CI and coding workflows, and improves simulation performance for environments that run databases and similar services inside the sandbox.
Using sandboxes as remote dev environments feels increasingly natural now, quick startup, native SSH, persistent state, and no more piling up local worktrees and dependencies.
. @tensorlake sandboxes now support native SSH. You can point VSCode or Cursor at a sandbox to edit and compile code using a remote SSH session.
Sandboxes retain memory and the file system when paused, so you can come back later and pick up where you left off.
Spin up a remote dev environment under 2 seconds, for every feature, instead of keeping many work-trees locally.
These sandboxes can be created with arbitrary amount of CPU, RAM and Disk so they can be sized based on the code base!
Docs below 🧵
Use a sandbox as your dev environment.
SSH in from any machine, work normally, then walk away.
The sandbox auto-suspends when idle and resumes later with your shell history, installed packages, git branches, and VS Code setup intact.
Portable. Disposable. Recoverable.
https://t.co/fEbc8JfIpx
As we continue to double down on sandboxes and serverless orchestration at @tensorlake, we’ve decided to open source Document AI in the coming weeks. This is a product we’ve been selling to customers for the last year, and it’s parsing 1000s of documents every day in production at energy, mobility, health care, and insurance companies.
This builds on Tensorlake’s serverless orchestration runtime, which runs on sandboxes and uses S3 for queues, RPC, and durable execution. Applications built on this runtime automatically scale up and down as requests hit the endpoints.
Functions run in sandboxes by default, so you can safely embed agentic harnesses for agentic ingestion workflows. The alternative is wiring up Lambda, SQS, and a custom control plane to observe workflow state.
If you’re building agentic ingestion APIs or doing document parsing at scale, we can give you early access to the repository for testing! This will save you operational headaches of managing and scaling infrastructure, and also we have solved way too many edge cases around parsing in the last year.
@droid is one of the more interesting coding-agent harnesses we’ve seen recently.
Not only because it has one of the coolest startup animations in the terminal. 👀
Contextual instruction injection, per-model tool schemas, planning/execution splits — all contributing to 77.3% on Terminal-Bench.
Now you can try it out on Tensorlake at https://t.co/pJVdagRlt8
And we broke down the scaffold design decisions here ↓
https://t.co/OqTgez9zg2
🙌
@tensorlake is showing top-tier performance across all ComputeSDK benchmark categories — with strong, consistent results across workloads.
This is exactly what we’ve been optimizing for: fast, stateful infrastructure for AI agents.
More to come on what’s driving the performance.
🚨🚨🚨
Benchmark Friday is back!
A huge shoutout to @tensorlake our latest provider added to the sandbox benchmark!
You can tell they've been working hard!
Native async APIs are now supported in the Tensorlake Python SDK ⚡
Useful for concurrent sandboxes, agent workflows, async web servers, and streaming execution.
Docs: ⬇️
https://t.co/MlYqNilQgM
We just added a dedicated Harbor page to the Tensorlake docs 🚀
If you’re running Harbor / Terminal-Bench style agent evaluations and want to use Tensorlake sandboxes behind the scenes, this should make setup much easier.
https://t.co/l6mUAheURu
Curious to hear how folks are using Harbor + sandboxes in practice.