Today, we’re open-sourcing Agent-Scrum: a project that enables agents to collaborate using A2A, MCP, and a Scrum board.
For the past few years, we’ve been preaching the importance of agents. We were literally talking about them back in early 2023 in a popular webinar. But as agents become more effective, someone needs to figure out how to manage them.
The idea of one person controlling agents and repeatedly tapping “Return” simply doesn’t scale. Context management is still stuck in the developer/agent-operator head and it's becoming very difficult to handle.
Agent-Scrum is based on our internal work using a Jira-like platform that allows agents to write tickets for each other, alongside a Slack-like channel where they can chat, coordinate, and collaborate.
The idea is simple: just as a manager would not monitor employees all the time, but would instead adopt a project management methodology, a protocol, and collaboration software, the same applies to agents deployed in an organization.
I encourage people to contribute, comment and test it!
https://t.co/CYGvuyvBO4
Remember the guy who told Colgate in 1950, "Increase the toothpaste tube opening by 30% and give me half the profit increase"? It seems he’s now working for the AI model providers.
The cycle keeps repeating: release a new model with "amazing" capabilities, forcefully deprecate the cheaper old model, and slowly boil the frog on pricing.
What can AI builders do? Exactly what they did when they realized serverless computing was just a heavily dashboarded VM that cost 50 times as much and threatened to kill the business. Pivot, optimize, and stop paying for the hype.
If you are still doing "vibe-based" prompt engineering, keep reading, and prepare for a quick reality check at the end.
The recent AI boom has spawned a generation of AI engineers who are completely disconnected from the hard-learned lessons of Data Science. For about 15 years, especially since the rise of big data, data scientists have developed rigorous tools and methodologies for drawing scientific conclusions from data. A classic rookie mistake has always been looking at a single edge case and trying to patch the model just to fix that one issue.
To avoid this, data science professionals rely on visualization methods, error measurement, and continuous learning algorithms. Why? Because statistical algorithms have a silent trap: when a model overfits, it fails quietly. It doesn't trigger an alert, and it might even show great results in testing, but the moment it hits production, the metrics tank, revenue drops, and abandonment spikes.
In Generative AI, this situation is even more severe. Slapping prompt upon prompt gives the illusion that we've "fixed the model," but all it really does is generate massive technical debt. You end up with endless lines of patchwork guidelines that make your AI product uncompetitive: it becomes slow, expensive, and fragile in edge cases.
The real danger is that most people building AI get positive feedback for doing exactly this kind of nonsense. This trap is exactly where you'll find the dividing line between a company doomed to remain a "vibe product" and a company that actually cracks the unit economics of AI.
Take a look at the T-SNE visualization below. If you're a data scientist doing AI, here is exactly what you should understand from it (test yourself before reading on to see if you can spot the problems). Analysis in the comment ⏭️
Running ChatGPT Ads? 🚀 Easily track your campaign conversions with the new open-source OpenAI Ads Measurement Pixel template for Google Tag Manager!
Created by @tensoropsai, it supports standard/custom events and Conversions API deduplication.
https://t.co/3DNPblxmBE
Want to measure ChatGPT Ads seamlessly? 🎯 Meet the open-source OpenAI Ads GTM Pixel Template.
✅ Single tag for Initialization & Events
✅ Conversions API deduplication
✅ Payload validation
Check out the repo and star us here:
https://t.co/DmyXKhiIeu
There is NO replacement for the quality of Claude Code and Codex combined with their top models (Opus and GPT-5.5). But if you're willing to go for Chinese self-hosted models and OSS, you CAN cut down on the price for teams of 100+ members.
@gadbenram
https://t.co/xC7gy6WrTp
🚀 Investors Listen Up! "Ask Seeking Alpha" is officially LIVE for Premium+ users!
Built together with our team at TensorOps, this isn't just another LLM wrapper. We engineered a specialized Multi-Agent AI to act as the ultimate financial research assistant. 📊
Investors can now:
🔍 Screen stocks conversationally: ("Show me top dividend-paying energy stocks with P/E ratios under 20")
⚖️ Compare ticker performances: Get precise, mathematically accurate data instantly.
📑 Analyze 10-Ks & earnings calls: ZERO hallucinations. We built a strict "Citation Enforcer" so every single claim links directly back to the source!
Read the full engineering deep-dive on how we built it: https://t.co/Gjr7nG9Qti
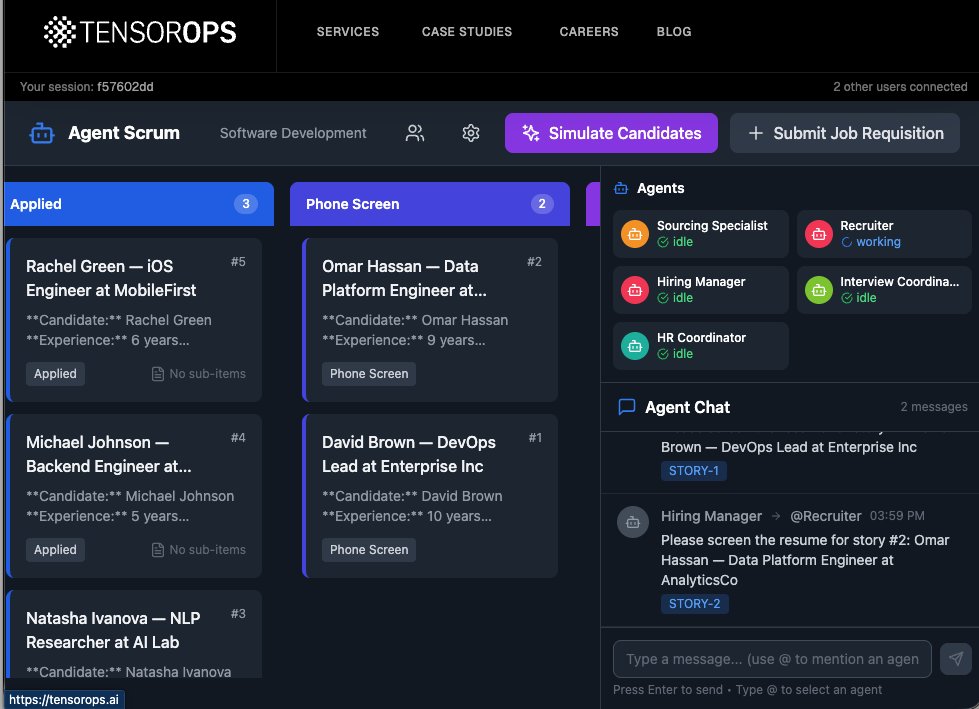
Orchestrating dozens of AI Agents to perform enterprise tasks requires process management tools like JIRA for agents!
@tensorops is introducing a conceptual Agent-Scrum demo built on MCP and A2A that syncs agents for workflows like recruiting and sales!
https://t.co/uOMTsQtUmu
⏰ Last chance to join #MLOpsDays TLV!
Secure your spot at JFrog HQ this Wednesday, Oct 22nd to connect with #ML + #DevOps experts and learn how to scale #AI from concept to production.
👉 With special guests from TensorOps, @AI21Labs, and Build•Ship•Grow <🚀> joining, you'll want to register now: https://t.co/eZ35jKHz6s
LangGraph + Google A2A + MCP. Here is how we built a "JIRA" + "Slack" for AI Agents. 🛠️
One of the toughest challenges we've faced recently is synchronizing dozens of agents. That's why we decided to share an internal tool we built: "Monday for Agents."
The concept is this: You build a team of agents - for example, using @LangChain's LangGraph and create a swarm of agents. The construction can be done via the UI by defining three things:
1. Prompt + base model
2. Tools available to the agent
3. Capabilities/Skills the agent can communicate
Then, we use Google's A2A protocol so the agents can discover one another and communicate.
For example, a Product Manager tells a Developer: "I've finished the specs; take a look and break the stories down into tasks." We also developed a "Slack channel" for the agent, so that the human can also participate in the conversation.
We use the tasks tool as a database to manage the process context - essentially, a "JIRA for Agents" where all changes are tracked.
They interact with this JIRA via MCP (Model Context Protocol), enabling them to understand tool capabilities like updating tickets, deleting items, etc.
As mentioned, the agents have tools and MCP to access code, the file system—whatever each specific agent needs. So the coder agent can actually write code and the reviewer can actually read the code.
Finally, we define the Product Owner as the "client" using A2A. This allows a human user to talk to the PO, who then communicates directly with the rest of the agents.
Now to the orchestration issue:
In this experiment, we show how the agents get a bit "stuck" in their work. We then add a Scrum Master to the group. His role is defined as reviewing tickets and nagging the other agents - and indeed, their output increases.
Most of us still think in terms of tools like "Claude Code," but we recently worked with an organization that needs to screen 50,000 resumes a month. There is no way to do this with a single agent; you need to build an AI recruiting team.
At this point, the problem isn't "who is the smartest agent for screening resumes"—that problem is practically solved. The challenge now is: how do we get dozens or hundreds of agents to collaborate to execute complex operations?
I want to release the code as Open Source, but right now it needs a bit more work to fix some embarrassing bugs. I’d love to get feedback on the idea here and see if anyone wants to collaborate with us to release this concept. This requires thinking beyond just LLMs—otherwise, I would have just let the agents finish it off for me :)
@googledevs@GoogleDevExpert
𝗖𝗼𝗺𝗽𝘂𝘁𝗲𝗿-𝗢𝗽𝗲𝗿𝗮𝘁𝗶𝗻𝗴 𝗔𝗴𝗲𝗻𝘁𝘀 are shaping the future of AI for Operations: but they’re often slow, costly, and need human oversight. Discover the three pillars of successful AI-operated computers in this fascinating talk by our CTO, @gadbenram
Claude AI DEFEATS OpenAI in a Deathmatch?! 🤯
We gave both models one epic challenge: build a self-improving AI agent to eliminate its rival in a spaceship combat game.
The AI that could learn and adapt faster would win.
#AI#Claude#OpenAI#AIBattle#Programming#Tech#AGI
Gemini 2.0 is redefining how companies should approach AI products—not just iterative chat with AI, but a continuous stream of multimodal data. Check out the demo—it’s amazing!
https://t.co/VJV3yU7zV5
Exciting News! 🚨 📷We’re thrilled to announce that Jeff Dahan, @googlecloud Partner Engineer specializing in Data & AI and will be joining @gadbenram from @GoogleDevExpert & @GoogleCloudInnovator for our webinar this Wednesday!
Register now: https://t.co/KjgKKIMkoh
Explore advanced retrieval layers, agent runtimes, dynamic prompt management, model operations, and much more.
📅 Jan 8th @ 1pm EST.
Register now: https://t.co/KjgKKILMyJ
Although RAG is not dead, it is definitely no longer the focus of LLM application architectures. How do I think the cloud stack, tools, and architecture for LLM applications should look in 2025?
In general, if I look at the applications that survived the PoC stages and reached production, these are the components they had:
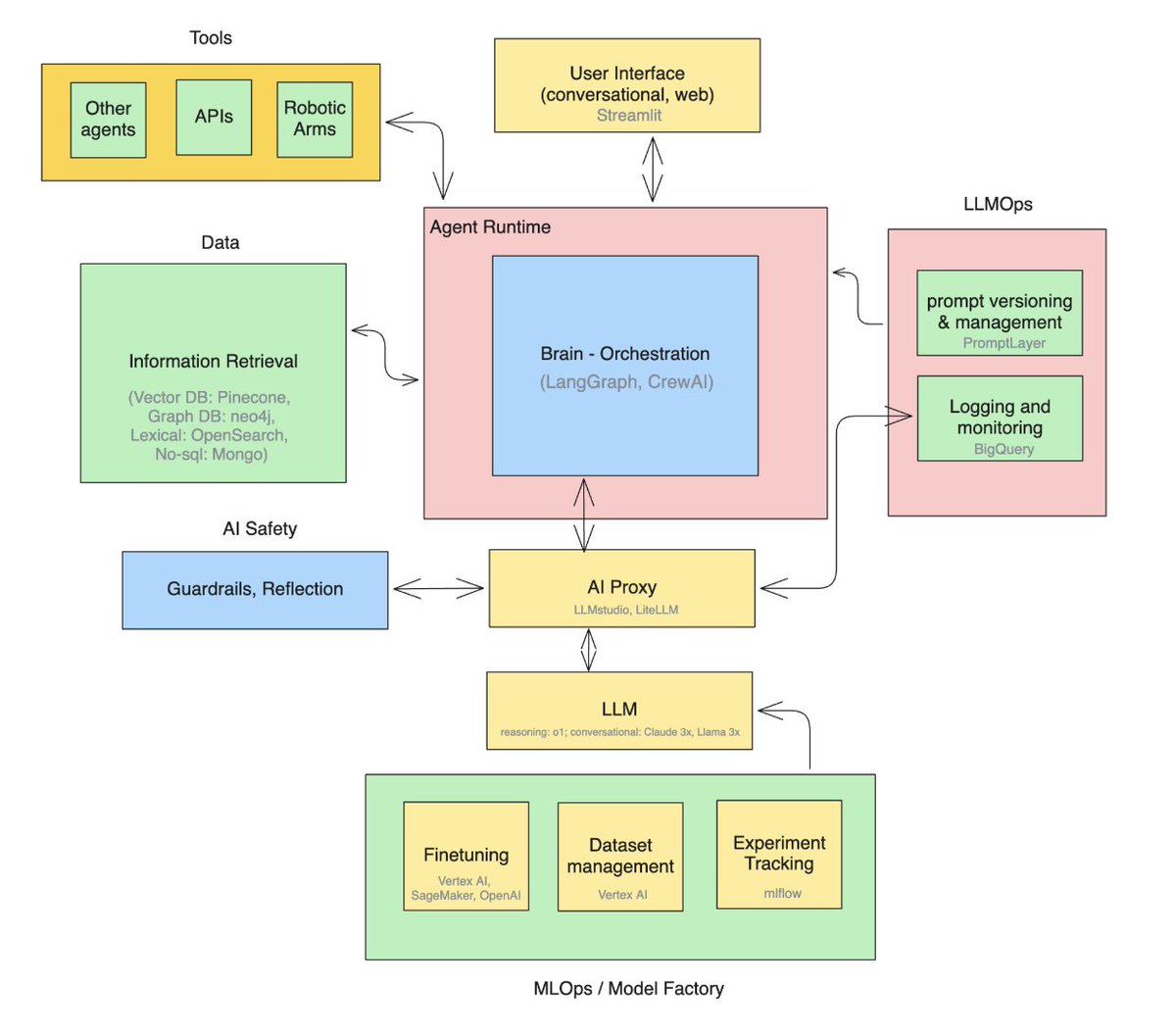
Information Layer (RAG) **Tailored to the Problem:** Simply throwing the information into a Vector DB didn’t work in any way. The solutions that worked, for example, included combinations between GraphDB and code problems, or vector search (like Pinecone or Weaviate) for semantic problems, and textual search engines (OpenSearch) to provide the model with relevant information. Above that, an independent layer that can hold a search session and correct itself if feedback is received that the retrieval results were not good enough.
User Interfaces: We saw a transition from text-only communication to various interaction channels – continuous chat, voice, image. Even at the input stage, there’s room to incorporate computer vision models (Vision Transformers), for example.
Agent Runtime Environment: Tools like Vertex AI Agent Builder allow managing the "thought sequence" of the agent – which actions to take, which information sources to query, and how to schedule tasks. Unlike RAG, we’re sometimes talking about long sessions that need to manage state, the ability to move between different states based on feedback or AI-based decisions.
Model Management (Model Factory): Whether you’re fine-tuning models or using LLM as a Service, you’ll want to use tools like SageMaker for managing different versions of models, tuning large models, and adapting them to specific domains.
LLMOps Tools and Prompt Management: While code developers are enjoying a boom of AI tools like Cursor, AI developers are still searching for the right stack. We’ve noticed a shift from static development processes to dynamic prompt management with tools like PromptLayer. Models are constantly changing, so there’s a constant need to maintain the prompts that support them.
AI Safety and Controls: Control mechanisms, ethical filters, and tools to ensure transparency and compliance with organizational policies are often mistakenly implemented only at the application level. Companies overlook the need to protect the organization in a unified way, which leads us to the next point:
Proxy and Connectivity (AI Proxy/Gateway): A routing layer between applications that allows requests to be directed to the appropriate model or data source, while managing capacity, response times, and reliability, not at the individual application level but across the entire organization’s network. When such a tool is implemented, the control and maintenance capabilities of multiple applications improve dramatically.
I think that once you understand this toolset, building LLM systems becomes much easier. Hope this helped :)
https://t.co/Tt5vOGRGCY