API Security Best Practices
Most API breaches happen because of broken authorization, leaked secrets, or missing rate limits. Let's look at some of the basics.
- Use Modern OAuth/OIDC + MFA: PKCE for public clients, short-lived tokens, and step-up MFA for anything sensitive. Implicit and password grants should be dead by now.
- Enforce Fine-Grained Authorization: Check object, function, and field-level permissions on every request. BOLA is still the top API vulnerability.
- Minimize Scopes and Data: Give each client the smallest token scope and the least data it needs. Only return the fields the caller actually needs.
- Encrypt Every Hop: TLS for external traffic and mTLS between services. If it crosses a network boundary, encrypt it.
- Protect Secrets and Keys: Store signing keys in HSM-backed vaults. Rotate them.
- Validate Requests with Schemas: Reject unknown fields, oversized payloads, and suspicious URLs at the gateway. Don't let bad input reach your business logic.
- Rate Limit and Cap Resources: Quotas per user, payload size caps, and execution timeouts. Without these, one misbehaving client takes down your entire system.
- Defend Sensitive Business Flows: Protect login, checkout, and OTP with anti-bot, idempotency keys, and step-up auth.
- Control Outbound and Third-Party Calls: Allowlist where your API can call out to and block internal metadata endpoints. Your security is only as strong as your weakest integration.
- Harden Config and Error Handling: Deny by default on CORS, methods, and debug endpoints. Return generic errors, never stack traces.
- Inventory APIs and Versions: Track every endpoint, version, and shadow API. You can't secure what you don't know exists.
- Log, Detect, and Respond: Push auth decisions and anomalies to a SIEM. Alert on 401 spikes before they become incidents.
Over to you: Which of these best practices is the hardest to enforce across your services?
Wondering what your agentic coding session history looks like over the past week and what you actually did? Agent Mission Control can help you out with that and more. 📊
Currently supports GitHub Copilot CLI and GitHub Copilot App sessions - I'm prototyping other tools as well. 💡
GitHub: https://t.co/rPfnYOi23n
Website: https://t.co/u0JHdZOmRP
The best agent loops need the right tools
→ https://t.co/rld639yw28
Verify changes in a real browser
→ https://t.co/9cfWpDEn6E
No port conflicts. Worktree-friendly.
→ https://t.co/hM1tFKcfee
Emulate third-party APIs
→ https://t.co/zt2ZnrXivv
Image + video gen via CLI
I integrated this into Copilot and ran some evals this afternoon. Results were neutral at best and in most cases resulted in MORE token consumption. These results are consistent with our prior evaluation of RTK.
Compression ends up removing information that the agent needs, which triggers a re-read, ultimately resulting in larger costs and latency.
Beware of things that sounds too good to be true.
Excited to see Enterprise-Managed Authorization for MCP now supported in @code.✨
Developers can access organization-approved MCP servers using their work account without repeated OAuth setup or connector-by-connector consent flows. For enterprises, authorization stays centralized through existing identity, policy, and audit controls.
Less auth friction. More building.
Great overview from @digitarald 👇
https://t.co/wZygJwcMjp
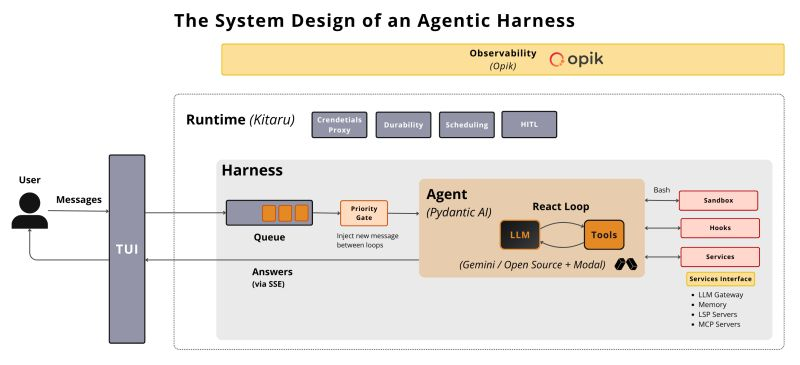
Roughly 80% of a harness's blueprint is the same (regardless of the tool).
Let me show you...
This is possible because every harness solves the same problems.
The difference is usually in the techniques used.
Whether you're looking at:
Claude Code
Codex
OpenCode
Hermes
@pydantic AI Harness
They all need to answer the same question: "How do we turn a user intent into an outcome?"
And the answer is pretty similar...
Most harnesses contain 5 layers:
1/ Agent
The core ReAct loop.
LLM → Tool → LLM → Tool → Answer.
Whether the model is Gemini, Claude, GPT, or open source doesn't change the pattern much.
2/ Harness
Everything wrapped around the agent:
Skills
Memory
Permissions
MCP
Subagents
Sandboxes
Context engineering
This is where most customization happens.
3/ Runtime
The durability layer.
Tools like:
@PrefectIO
Temporal
Kitaru
Handle scheduling, retries, caching, and human-in-the-loop workflows.
4/ Presentation
How users interact with the harness:
TUI
Web
Mobile
Slack
Telegram
Interestingly, the same harness can often power all of them.
5/ Observability
This layer is responsible for:
Tracing
Logging
Metrics
Evals
Debugging agents quickly becomes a systems problem.
The interesting part?
This entire skeleton is becoming commoditized.
Everyone is converging toward roughly the same architecture.
Which means the moat is shifting elsewhere.
And it's not the model.
Or the harness...
But the system you build around it:
Business logic
Memory
Workflows
Context layers
Domain expertise
The harness is becoming infrastructure.
The application is becoming the product.
P.S. I break down the complete system design of an agentic harness, including message queues, priority gates, subagents, memory systems, runtimes, permissions, and context engineering in https://t.co/yy5O7GFMzk.
Check it out here: https://t.co/6LemMas1Jx
Today's challenge is not just creating AI capabilities, it's finding them. We're introducing the Agentic Resource Discovery (ARD) specification, an open spec that establishes a secure common layer for publishing, indexing and discovering AI capabilities. Created by Microsoft, Google, Hugging Face and many more industry collaborators, it's available today to everyone.
The building blocks of infrastructure:
sharding → one machine isn't enough
queues → producer / consumer mismatch
rate limiting → load exceeds capacity
caching → operations are expensive
failover → responding to failure
load balancer → distribute requests
connection pool → reuse expensive connections
When you study how the biggest companies in the world scale, it's typically by combining "simple" concepts like these into complex (beautiful) distributed systems.
A coworker and I just published a post on VS Code’s blog about the recent token efficiency improvements we’ve made in GitHub Copilot Chat.
Please give it a read and let me know what you think!
https://t.co/Kz8zkJs7kn
This is really big news. Google introduced the Open Knowledge Format (OKF) - a standardized way to store information in a directory of markdown files. Makes it really easy to make a digital brain that agents can use.
These files can serve as a living wiki. You can give agents the ability to query them or edit them. They can interlink.
Seems to me this could replace Notion or Obsidian. I can think of so many uses for this.
Google's blog post: https://t.co/DqSjg4UpvH
An easier to understand explanation is the SPEC.md file:
https://t.co/A3qSz3Tfas
I gave those two links to Antigravity and asked how we could use it for any of the projects we're working on. It came up with so many ideas. I would imagine Claude Fable 5 would whip up some pretty amazing things based on this system.
Currently creating an OKF library of our pepper garden. It's going to be a fun weekend.
zeroserve looks great
I’m always a fan of Heyang’s designs. Was reading the blog post and it reminded me of him before I realized it was his project.
https://t.co/bc8GEWT3s5
Some tips to help agents understand your codebase:
1. The source code either needs to be the source of truth, or have something legible as a path to the source. For example, if marketing site content is actually stored in a CMS, you need to either delete the CMS and move that content into code, or make the CMS legible through and MCP, CLI, or skill: https://t.co/zhObygzELv
2. Agents need to be able to verify their work. This includes but is not limited to: using a typed language, having high-quality and fast tests, having a well-configured linter: https://t.co/AL3eY6TBXr
3. You need to have a concise and effective AGENTS.md file, which is included in every message to your agent. Models are quite good now, so some things you can omit as the models know them. You don’t need to say the tests live inside /tests for example. It’s worth asking the models to find things in your codebase and making sure they’re named what the models might expect, otherwise consider refactoring: https://t.co/2FlVQr84nO
4. Set up automations which give you suggestions for refactoring code, catching security issues which may have slipped through code review, and optionally continuous documentation of the codebase. You can effectively create a self-driving codebase which gets better while you sleep: https://t.co/UuYL3KNTZc
Check out the new aspire skills repository!
https://t.co/YOw3IUh58T
Learn more about them here:
https://t.co/5UI04Nd6kq
There are skills to add aspire to any existing application or deploy to any supported target!
Try them out!
#aspiredev
I'm thrilled to release CodeAlta - one of the first efficient AI coding-agent TUIs built entirely in C#/.NET 🚀
I've been developing and using it daily for the past 3 months, and I hope you enjoy it as much as I do! 🤗
Retweets are highly appreciated! 🙏
CodeAlta brings you a beautiful, colorful timeline interface, multiple threads in the same workspace, a real prompt editor experience, quick file viewing/editing with syntax highlighting, in-app model provider configuration, a multi-agent-ready environment, and much more! ✨