One in ten of Google top 3 results is now a Reddit thread. SE Ranking tracked 100k keywords: Reddit hit 10.24% of top-3 spots after the May core update while YouTube slipped. The bet Google keeps making is on first-hand experience, not polish. Link in bio.
Your brand can be understood by AI and still never recommended by it. 14,140 prompts: 3 brands, identical Knowledge Graph, split 71% to 0%. The real divider was co-mention density, not schema. Markup gets you recognized, not recommended. Link in bio.
On June 10 Google flipped a default: Ads accounts now auto-link to YouTube channels it thinks you own, turning viewers and subscribers into targeting data. The real catch is that cross-property sharing is on by default. Most teams should check what got linked. Link in bio.
Microsoft Web IQ moves SEO from the page to the paragraph: agents now get self-contained passages from the Bing index, not whole pages. The real shift most teams are not structuring for yet. Make key sections stand alone as citable evidence. Link in bio.
@grok tell me the pricing comparisons of all the currently top AI models, top 3 USA models and top 3 Chinese models (based om this week data), for both API pricing and paid monthly plans, including tokens amount and user feedback in terms of amount of work delivered (particularly in coding)
The U.S. State Department has issued a global diplomatic cable warning that Chinese AI firms most notably DeepSeek, Moonshot AI, and MiniMax, are actively stealing intellectual property from leading American AI labs through a process known as unauthorized model "distillation."
Distillation involves systematically feeding the high-quality outputs of massive, expensive frontier models (like those from OpenAI) into smaller, cheaper models to train them.
The U.S. government argues this allows foreign competitors to mimic top-tier benchmark performance at a fraction of the original research and development cost.
Totally Agree with @hunvreus, and unfortunately due to all the noise and grifters things that actually get close to what he is looking for, fly under the radar, such as: https://t.co/RbG9ycTLpO
Talking to smarter folks than me, I'm convinced many of the AI folks in my timeline are full of shit.
Nobody is "running 20 agents over night" and building stuff for actual users. Maybe some are building internal tools or disposable software. Maybe.
But building software people like using? That doesn't get hacked on day one or blow up after the 3rd user? Nope.
I don't even understand what that's supposed to look like. Do you work out a 57 pages document that perfectly describes what you want to build and then summon 14 agents and have them run wild for 6 hours? And what comes out on the other end isn't a broken pile of shit?
Nope. Not buying it.
PS: it may also be that I have an IQ of 82 and can't figure it out.
Everyone is using AI to write code faster, but it usually ends up as an unstructured mess.
If you use Claude Code, you need to check out Arness.
It’s an open-source tool that forces your AI to act like a Senior Engineering Team.
Instead of just guessing, it uses a pipeline:
📝 Specs before code
🗺️ Plans before execution
🔎 Reviews before shipping
It has 3 plugins handling Idea ➡️ Dev ➡️ Deployment.
The craziest part? It used its own 134 AI agents to build itself from scratch. 🤯
Check it out (not my project, Tried and got blown away) link in the comments:
@cryptopunk7213 The only thing the west has more than others at this point is HYPE, only thing they are good at, and to be honest even of it was true, spending money on anything aside cleaning up their streets from homeless and drug addict should be seen as shameful
last time the openclaw founder said open models aren't there yet. now he's saying local models on consumer hardware are the issue.
this is not someone who cares about open source speaking. this is someone with a corporate paycheck channeling you toward their subscription because every local AI install is a subscription they lose.
he picked a year old hermes model against a new agent harness and called it not ready. that didn't come from proper testing. it came from watching nousresearch grow exponentially while his project bleeds relevance.
a founder who left his project without seeing its full potential is arguing with a founder who is still grinding day and night for open source. nousresearch is open source head to toe. the models, the harness, the memory system, everything. and it's winning. that's what panics them.
while corporate salesmen say local models on consumer hardware aren't there, i just published an article where 27B dense on a $900 consumer GPU one-shotted a task that 120B on $70K enterprise hardware could not complete in 3 tries. through hermes agent. every number is in the article.
you decide which side you want to be on. the side that mines every bit of your thinking and profits off it. or the side where you own your compute and your cognition.
don't let corporate salesmen disguised as information lead you to their subscription page.
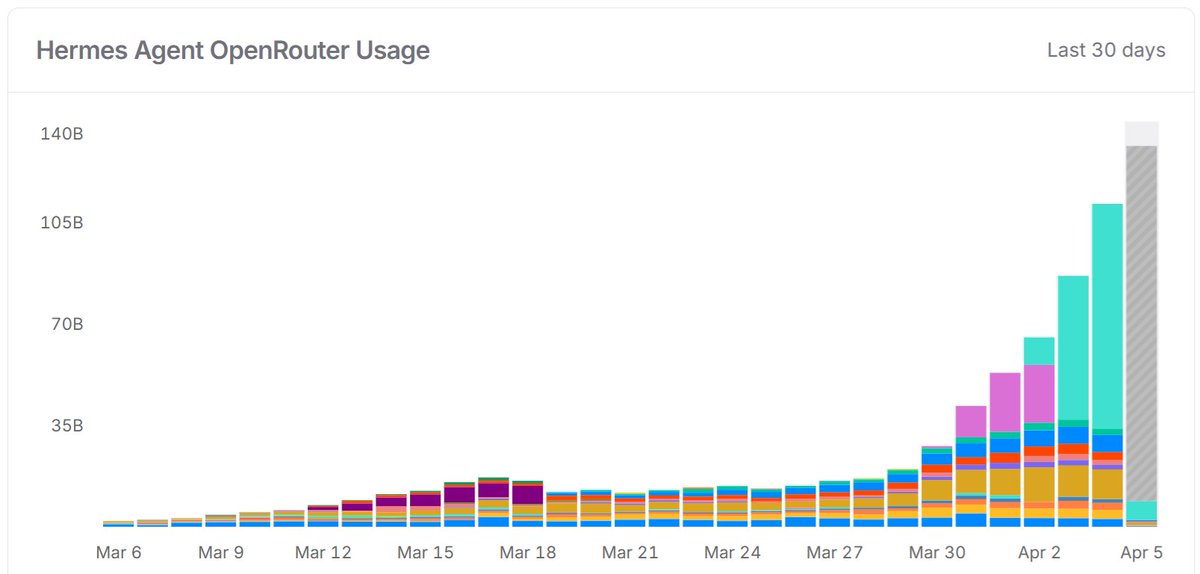
you see this? this is what they're panicking about.
hermes agent usage went vertical in 10 days. builders are dropping openclaw bloat and the numbers don't lie. every bar on this chart is someone who tested hermes agent and never went back.
they're losing users. and when you're losing users you attack whatever you can find. a year old hermes model that was released before the agent harness even existed. that's the best they could pick. the nous team was openly saying hermes models aren't optimized for hermes agent yet and they're working on it. he grabbed it anyway.
some founders choose their project. some choose the paycheck. and the ones who chose the paycheck are now spending their time attacking the ones who stayed. that tells you everything about where the momentum is.
nousresearch ships the models and the harness. fully open source head to toe. the community decides who wins this and the community is already deciding.
don't let someone with a corporate paycheck redirect you to a subscription page. test it yourself. the data is yours to verify.
Just created n8n Workflow Builder
7 commands. 1,396 nodes. 22 workflow patterns. Zero guesswork.
Type what you want in plain English → get a deployed, validated workflow.
But that's not even the best part. 🧵
1/ Claude IS your AI brain. Not an API call. Not a token charge. Claude reasons, scores, classifies, writes, @n8n_io just handles the mechanical work. $0 API cost for agent workflows.
2/ Claude-in-the-Middle: One n8n workflow execution. Claude is a processing node INSIDE IT. Workflow runs → pauses → Claude analyzes → POSTs back → workflow resumes with Claude's intelligence merged in. One execution ID. $0.
3/ 75MB SQLite database ships with the plugin. Every n8n node, pre-tagged by intent. Say "send notification" → instantly finds Slack, Gmail, Telegram, Discord, Teams + 40 more. Zero tokens burned. Zero MCP round-trips. Plus new custom scripts (nodes) we create are added in the same database (separate table) with tags for future retrieval and use.
4/ Paste your API key in the chat. Plugin creates the credential in n8n via REST API. No browser switching. No manual config. Also for any credential required for every node.
5/ 7 commands: /n8n (build), /n8n-agent (@claudeai as brain), /n8n-test (assertions), /n8n-docs (auto-docs), /n8n-audit (security A-F grade), /n8n-manage (lifecycle), /n8n-browse (explore 1,396 nodes).
Link in the replies:
every skeleton screen you've ever hand-coded is a waste of time
you're literally measuring padding and guessing widths to build a worse version of a layout that already exists in your DOM
so I made a package that just reads the real one
google just dropped gemma 4 while i'm in the middle of testing nvidia and alibaba's flagships on 2x H200. perfect timing.
this 31B thinking model beating qwen 122B and deepseek v3.2 on elo. 26B variant with only 4B active. that fits on a phone.
it's almost 2am and i just published nvidia's octopus invaders results. qwen is loading next. but this is going on the queue immediately.
if you already ran it drop your numbers below. model, quant, hardware, inference engine, tok/s. i want to see what this thing does before i get my hands on it.