Ph.D. student Thinh Pham (@thinhphp_vt) @VT_CS@SanghaniCtrVT presented his collaborative work, "SealQA: Raising the Bar for Reasoning in Search-Augmented Language Models," during a poster session at #ICLR2026 in Rio de Janeiro.
🔗to paper: https://t.co/42SmDlBLFs
Come checkout our posters at #ICLR2026 🇧🇷!
April 23, 10:30 AM - 1:00 PM
📍Pavilion 3 P3-#1424
SealQA: Raising the Bar for Reasoning in Search-Augmented Language Models (https://t.co/3YkR5SzpRg)
I'm also looking for opportunities this summer and would love to connect and chat!
🚨 Excited to announce MERRIN: a human-annotated, expert-vetted benchmark for Multimodal Evidence Retrieval and Reasoning in Noisy Web Environments! 🌐🔍
The web is noisy, conflicting, and multimodal. Even strong search agents fail when questions require reasoning across text, images, video & audio — MERRIN is built to diagnose exactly where they break down, via multi-hop reasoning on open-web search without explicit references to specific modality sources.
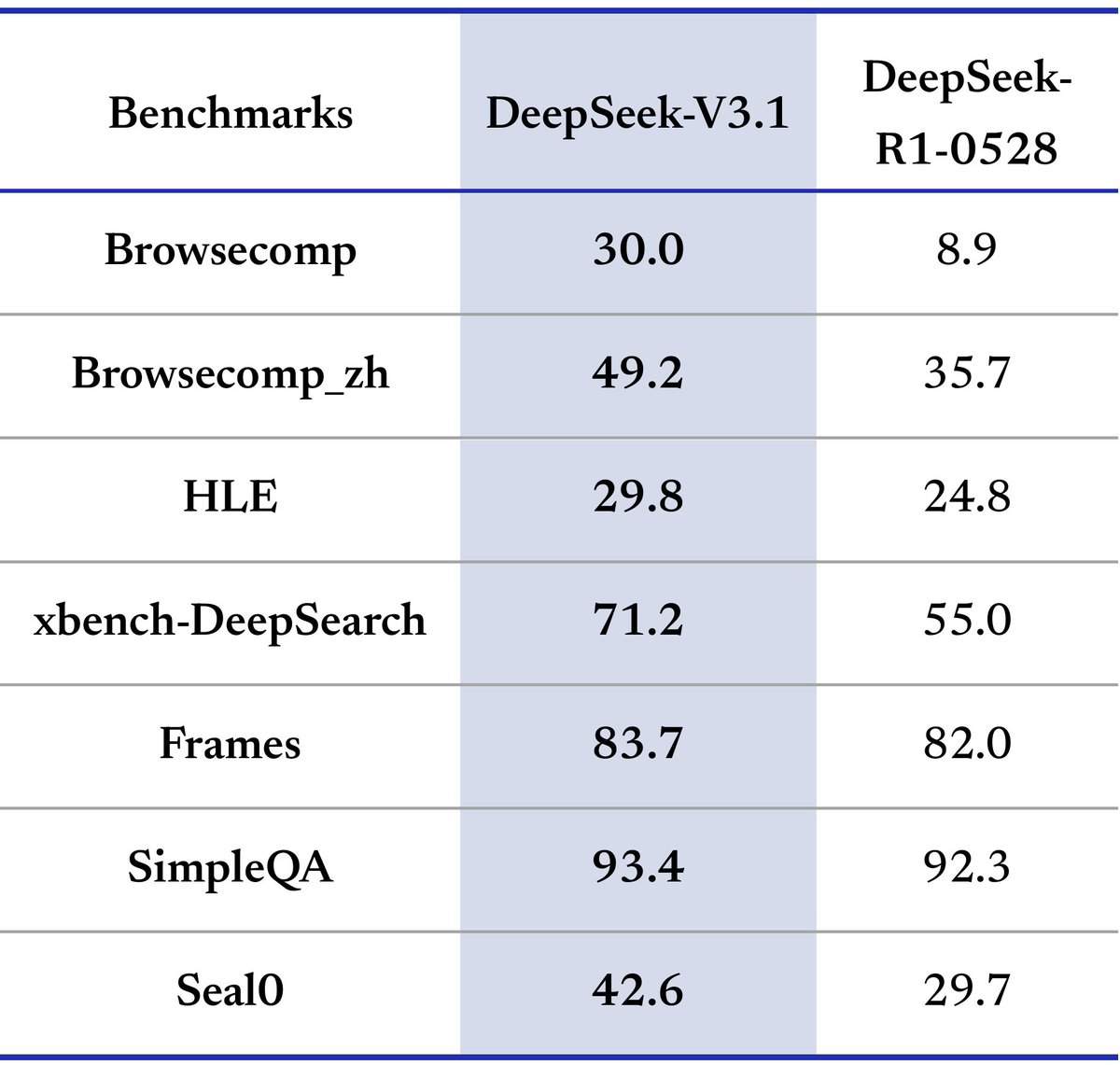
Very impressive results from Chroma Context-1, which push the Pareto frontier of agentic search on our SealQA (Seal-0) & LongSealQA benchmarks. Check out their techical report below 👇
https://t.co/eYtJZDHIwP
🔥Our paper "SealQA: Raising the Bar for Reasoning in Search-Augmented Language Models" has been accepted to #ICLR 2026!! 🎉🎉🎉
Huge thanks to my supervisor @tuvllms and the other co-authors for all your hard work! See you in Brazil ✈️
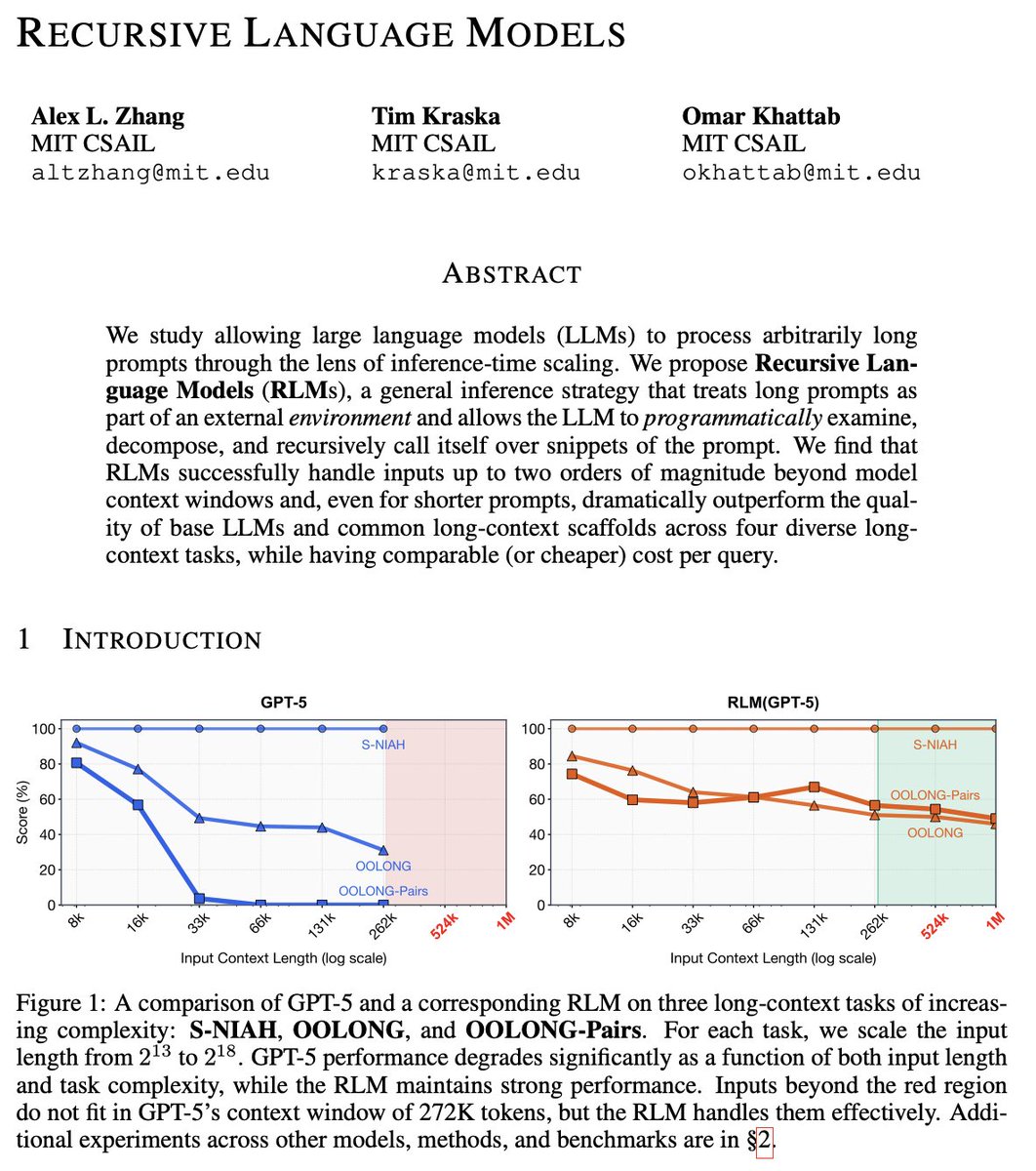
Much like the switch in 2025 from language models to reasoning models, we think 2026 will be all about the switch to Recursive Language Models (RLMs).
It turns out that models can be far more powerful if you allow them to treat *their own prompts* as an object in an external environment, which they understand and manipulate by writing code that invokes LLMs!
Our full paper on RLMs is now available—with much more expansive experiments compared to our initial blogpost from October 2025!
https://t.co/x47pIfIkTb
🚀 Hello, Kimi K2 Thinking!
The Open-Source Thinking Agent Model is here.
🔹 SOTA on HLE (44.9%) and BrowseComp (60.2%)
🔹 Executes up to 200 – 300 sequential tool calls without human interference
🔹 Excels in reasoning, agentic search, and coding
🔹 256K context window
Built as a thinking agent, K2 Thinking marks our latest efforts in test-time scaling — scaling both thinking tokens and tool-calling turns.
K2 Thinking is now live on https://t.co/YutVbwktG0 in chat mode, with full agentic mode coming soon. It is also accessible via API.
🔌 API is live: https://t.co/EOZkbOwCN4
🔗 Tech blog: https://t.co/n7xxaszqzF
🔗 Weights & code: https://t.co/4ukcXB0iP6
Announcing ROMA (Recursive Open Meta Agent): our new multi-agent framework that sets SOTA in reasoning + search.
Seal-0: 45.6%
FRAMES: 81.7%
SimpleQA: 93.9%
🧵 Read more about how recursive coordination lets agents tackle complex queries.
OpenAI realesed new paper.
"Why language models hallucinate"
Simple ans - LLMs hallucinate because training and evaluation reward guessing instead of admitting uncertainty.
The paper puts this on a statistical footing with simple, test-like incentives that reward confident wrong answers over honest “I don’t know” responses.
The fix is to grade differently, give credit for appropriate uncertainty and penalize confident errors more than abstentions, so models stop being optimized for blind guessing.
OpenAI is showing that 52% abstention gives substantially fewer wrong answers than 1% abstention, proving that letting a model admit uncertainty reduces hallucinations even if accuracy looks lower.
Abstention means the model refuses to answer when it is unsure and simply says something like “I don’t know” instead of making up a guess.
Hallucinations drop because most wrong answers come from bad guesses. If the model abstains instead of guessing, it produces fewer false answers.
🧵 Read on 👇
New paper! We explore a radical paradigm for AI evals: assessing LLMs on *unsolved* questions.
Instead of contrived exams where progress ≠ value, we eval LLMs on organic, unsolved problems via reference-free LLM validation & community verification. LLMs solved ~10/500 so far:
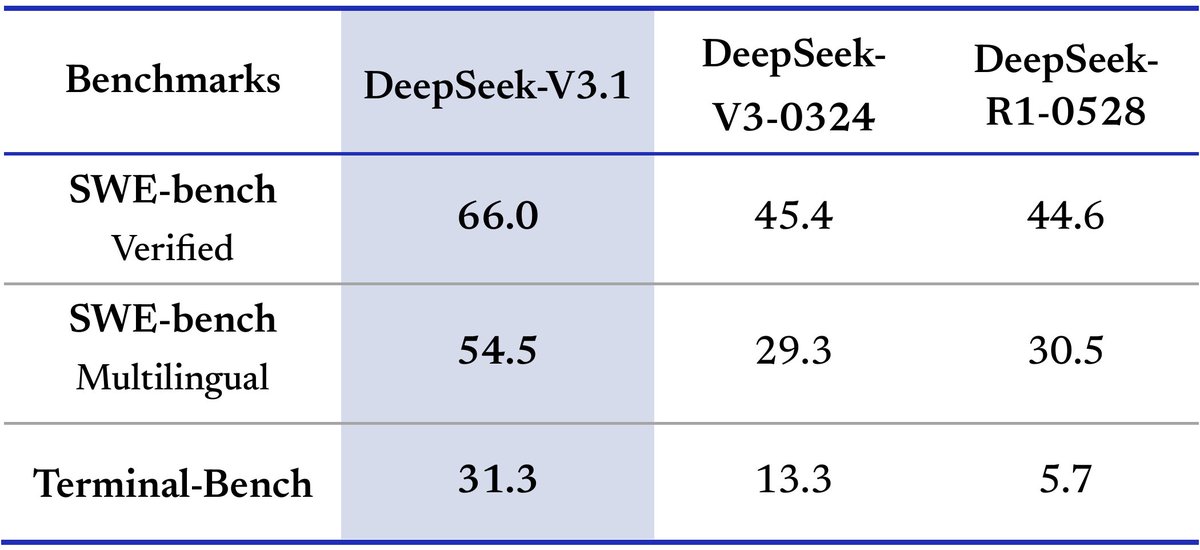
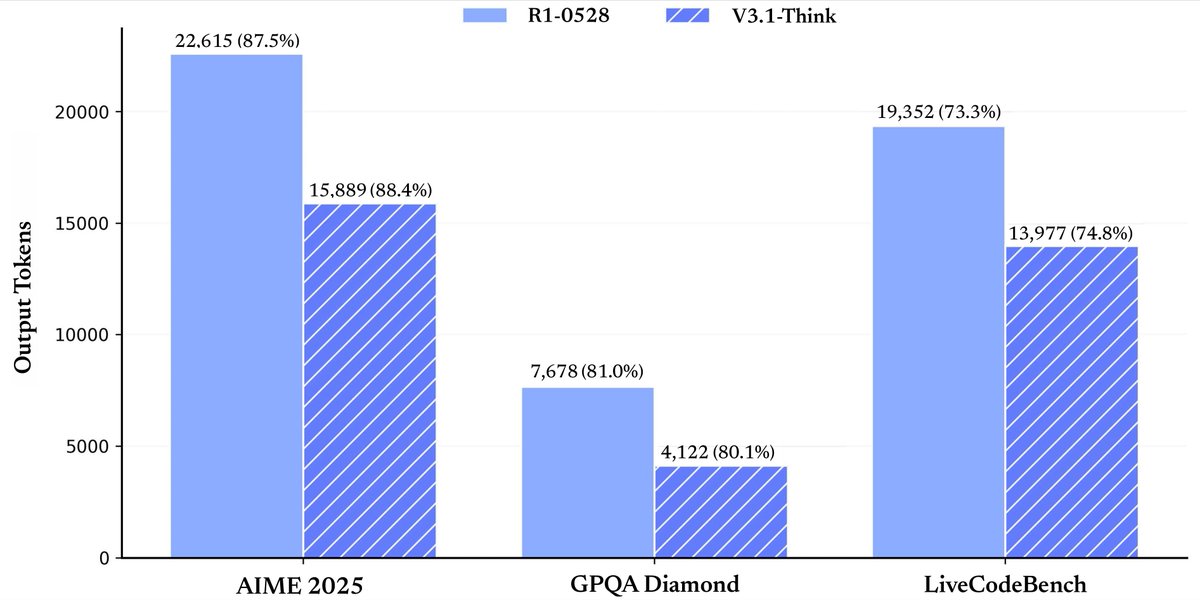
Tools & Agents Upgrades 🧰
📈 Better results on SWE / Terminal-Bench
🔍 Stronger multi-step reasoning for complex search tasks
⚡️ Big gains in thinking efficiency
3/5
Excited to share that our paper on efficient model development has been accepted to #EMNLP2025 Main conference @emnlpmeeting. Congratulations to my students @linusdd44804 and @Sub_RBala on their first PhD paper! 🎉
A few weeks ago, I started a new job at @OpenAI. I wrote a document about my interview process and recommendations for anyone on the job market for AI research positions. I hope it's helpful!
https://t.co/0I6f6UrAqD
1/n I’m thrilled to share that our @OpenAI reasoning system scored high enough to achieve gold 🥇🥇 in one of the world’s top programming competitions - the 2025 International Olympiad in Informatics (IOI) - placing first among AI participants! 👨💻👨💻
Most search models need the cloud.
II-Search-4B doesn’t.
4B model tuned for reasoning with search tools, built for local use.
Performance of models 10x its size.
Search that is small, smart, and open.
🥳Congrats @ii_posts for an impressive result on SEAL-0, a challenging benchmark for search-augmented LLMs.
🤩Looking forward to the evaluation standards it shapes in this field.
📚Read more: https://t.co/3YkR5SzpRg
. @EMostaque came back on the show to chat about:
--how we can't compete against AI agents
--his solution for a POSITIVE AI world
--Why UBI won't work but UBAI might..
--we need to be focused on incentivizing the right outcomes
-- Nations need sovereign AI stacks or they'll be left behind by the mega-models
We just released the evaluation of LLMs on the 2025 IMO on MathArena! Gemini scores best, but is still unlikely to achieve the bronze medal with its 31% score (13/42). 🧵(1/4)