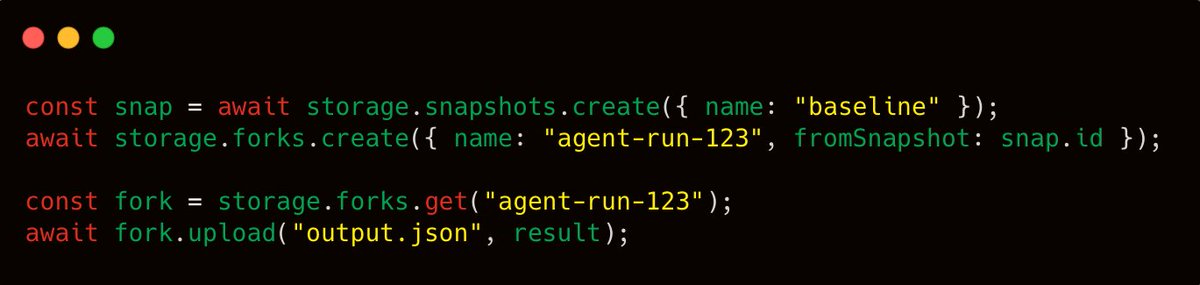
A fork is a metadata operation and not a data migration.
You can fork your data for an agent run, let it mutate files safely, replay later from the same baseline.
Git branching, but for storage: https://t.co/Ro2CQKUFm0
We partnered with @computesdk to build storagesdk - the other half of computesdk.
Buckets should branch like Git, and have forks and snapshots as first-class primitives.
Most adapters fake that by copying every object into a sibling bucket. The Tigris adapter does it natively.
I am really excited for the storagesdk launch. storagesdk provides a unified storage API across all the major storage providers with first class support for snapshots and forks. A lot of care and thought has been put into thinking about the DX!
We partnered with @computesdk to build storagesdk, the other half of computesdk-- same shape, same goal, but for storage instead of compute.
Buckets need the same primitives already used in Git. Forks and snapshots are first class primitives. Storage becomes a versioned workspace.
With storagesdk, fork into a new branch of your data for an agent run, let the agent upload and mutate files safely, and then replay the run later from that same baseline.
Git branching, but for storage.
Today i'm excited to announce storagesdk, built in partnership with @TigrisData
A TypeScript SDK for object storage with snapshots and forks as first-class primitives
branch a bucket per agent run. mutate safely. replay from the same baseline. Across many providers.
There's even a live demo over SSH! No authentication required because there's nothing to protect. Every session is its own little world.
Check it out on the blog: https://t.co/O8JR8yPjo2
"What if our expense-submission agent yeets all the receipts out of the bucket?"
Nobody wants that on a threat model. But how do you safely give an AI agent a shell?
So Xe built that in Go based on work done in just-bash and agent-shell. Sandbox every agent in their own bucket fork so they can't hurt anything and delete that fork when it's done.
Agents need safe ways to try, fail, fork, and iterate.
On June 9, we’re co-hosting Fork it, Branch it, Bop it with @PlanetScale in SF — a demo night on forkable infra for agent builders.
Featuring demos from @archildata, @agentuity, @daytonaio, and @mesa_dot_dev.
https://t.co/EjFX5orkQE
Working off of forks protects your storage from bad entries. If the bucket fork checks out, then it eventually gets promoted into production.
We advise this new method of agentic storage via our agent-kit SDK, which is built natively for agent use.
Read More: https://t.co/RZSB4Y9nmn
When agents use object storage, they should work off of forked buckets, not the original production bucket.
This way, any bad write can be quarantined.
You can now stack up to 10 rules per bucket, target folders with prefix filters, and mix transitions and expirations however you want.
Full breakdown here: https://t.co/KgJlUrGYwp
We just shipped multiple lifecycle rules per bucket for Tigris: https://t.co/KgJlUrGYwp
You can route heavy ML datasets to Glacier while auto-deleting stale logs on autopilot.
No more global policies or janky deletion scripts.
I am bullish on the decentralization of compute. We are going to need 100x more capacity at least if not 1000x and it’s not going to be the big 3 serving all that demand.
If AI agents are going to scale into the millions, we need tools that are tiny, isolated, durable, and safe to leave unattended. That's the niche agent-shell fills.
Read more on the blog: https://t.co/c8n7HqWcpf
This is also great for agents as they are really good at using bash, so it's win/win/win: good for us as a demo, good for you as a user, and good for your endless swarms of agents as you make your life's dreams come true in the form of B2B SaaS apps.