Also glad to share: We made it work for instruction following models!
NH2-Mixtral-8x7B ➕ NH2-Solar-10.7B ➕and OpenChat-3.5-7B ➡️ new sota for 7B model in MT-BENCH
Check it out:
https://t.co/VvnEYTZZVe
Knowledge Fusion of LLMs
Is it possible to merge existing models into a more potent model?
We have already seen a few ways that show the potential to effectively do this using approaches like weight merging and ensembling of models.
This work proposes FuseLLM with the core idea of externalizing knowledge from multiple LLMs and transferring their capabilities to a target LLM.
It leverages the generative distributions of source LLMs to externalize both their collective knowledge and individual strengths and transfer them to the target LLM through continual training.
To put it simply, the idea is to benefit from the strengths of all the LLMs and combine them into one integrated model.
Finds that the FuseLLM can improve the performance of the target model across a range of capabilities such as reasoning, common sense, and code generation.
By the way, you can also perform the fusion among fine-tuned LLMs that specialize in specific tasks.
This continues to be an interesting research area so hoping to document more on any new ideas and findings I come across.
The End of Manual Decoding: Meet AutoDeco
Researchers unveil AutoDeco, a groundbreaking framework that teaches LLMs to control their own decoding strategy. It dynamically predicts temperature & top-p for each token, eliminating manual tuning & enabling natural language control.
Introducing Search Self-play (SSP, https://t.co/fF0GyrgMAs)! We let deep search agents act simultaneously as a task proposer and a problem solver. Through competition and cooperation, their agent capabilities co-evolve and uniformly surpass SOTA performance without supervision!
🚀 Excited to announce our 🍁Marco‑MT🍁 achieved outstanding results at #WMT2025 General Translation! 🏆 Notably, in English→Chinese it outperformed closed‑source leaders like GPT‑4.1 and Gemini 2.5 Pro.
Among 13 language pairs we competed in, Maroc-MT-Algharb achieves (final human evaluation):
🏅6 First Places
🥈4 Second Places
🥉2 Third Places
🎯We did this with key innovations:
• Novel M2PO translation paradigm
• Two-stage SFT + CPO+MPO reinforcement learning
• Hybrid decoding with word alignment & MBR
Learn more:
- Demo: https://t.co/XxNUm8g578
- Technical Report: https://t.co/6nCk1Q29xK
- Hugging Face: https://t.co/3KMnCmcR4o
🌺GPT-4o’s image generation is stunning — but how well does it handle complex scenarios? 🤔
We introduce 🚀CIGEVAL🚀, a novel method to evaluate models' capabilities in Conditional Image Generation 🖼️➕🖼️🟰🖼️. Find out how top models perform when conditions get truly challenging! 🔥
#ImageGeneration #AutoEvaluation #Multimodal #GPT4O
These findings resonate with my impressions. AFAIC, structured prompting outperforms CoT & ICL by steering LLMs through workflows.
Great to see this ‘rebuttal’ backed by such rigorous analysis — reminds me of the insights in LLMs Cannot Self-Correct. We need more like this!
Does Structured Outputs hurt LLM performance? 🤔 The paper "Let Me Speak Freely" paper claimed that it does, but new experiments by @dottxtai (team behind outlines) show it doesn’t if you do it correctly! 👀
TL;DR;
📈 The "Let Me Speak Freely" poor results came from weak prompts and wrong use of structured prompting
📊 Structured outputs outperform unstructured on the test GSM8K: 0.78 vs 0.77, Last Letter: 0.77 vs 0.73, Shuffle Object: 0.44 vs 0.41
🛠️ Key success criteria is to align your prompt, parser, and generator - it's not just about using JSON mode
📌 JSON generation requires careful prompt design, including specifying the desired schema.
📝 Good prompts should contain enough information for a human to understand the task and expected response format
🎯 JSON generation reached 77% accuracy vs the paper's reported <10%
🔮 Examples in prompts should match the exact format expected in the actual tasks
🧰 Structured generation works best when implemented as "running our response parser as a generator"
RAG matters so much in real-world LLM applications, and so glad to see this new work bring Soooo much efficiency boost!
#RAG#BlockAttention#Innovation
A quick walk-through of this amazing work 👇
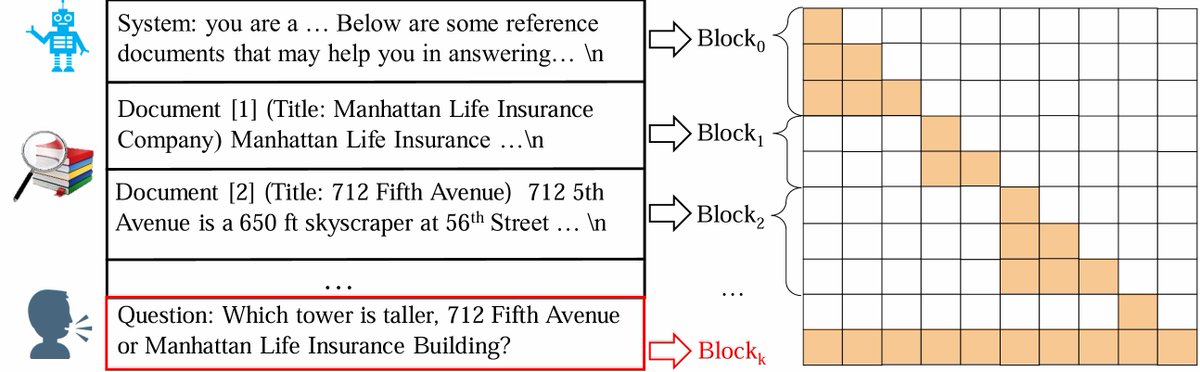
The Block-Attention Mechanism, by independently encoding passages, allows us to reuse the KV states of previously seen passages. From now on, no matter how many passages are retrieved, the latency and computational cost are brought down to nearly the same level as non-RAG LLMs.
🔥Our LLM-powered MT (Marco-MT) has achieved massive commercial use, leading the industry in both efficiency and cost-effectiveness. 🌏 Revolutionizing translation in e-commerce and beyond! 🚀
🌍 For more details: https://t.co/UIo3pj2m0l
✨ Try it now: https://t.co/3hruAnSlUF
To Code, or Not To Code?
Exploring Impact of Code in Pre-training
discuss: https://t.co/igjUwMtv3p
Including code in the pre-training data mixture, even for models not specifically designed for code, has become a common practice in LLMs pre-training. While there has been anecdotal consensus among practitioners that code data plays a vital role in general LLMs' performance, there is only limited work analyzing the precise impact of code on non-code tasks. In this work, we systematically investigate the impact of code data on general performance. We ask "what is the impact of code data used in pre-training on a large variety of downstream tasks beyond code generation". We conduct extensive ablations and evaluate across a broad range of natural language reasoning tasks, world knowledge tasks, code benchmarks, and LLM-as-a-judge win-rates for models with sizes ranging from 470M to 2.8B parameters. Across settings, we find a consistent results that code is a critical building block for generalization far beyond coding tasks and improvements to code quality have an outsized impact across all tasks. In particular, compared to text-only pre-training, the addition of code results in up to relative increase of 8.2% in natural language (NL) reasoning, 4.2% in world knowledge, 6.6% improvement in generative win-rates, and a 12x boost in code performance respectively. Our work suggests investments in code quality and preserving code during pre-training have positive impacts.
🚀 A game-changer benchmark: LLM-Uncertainty-Bench 🌟
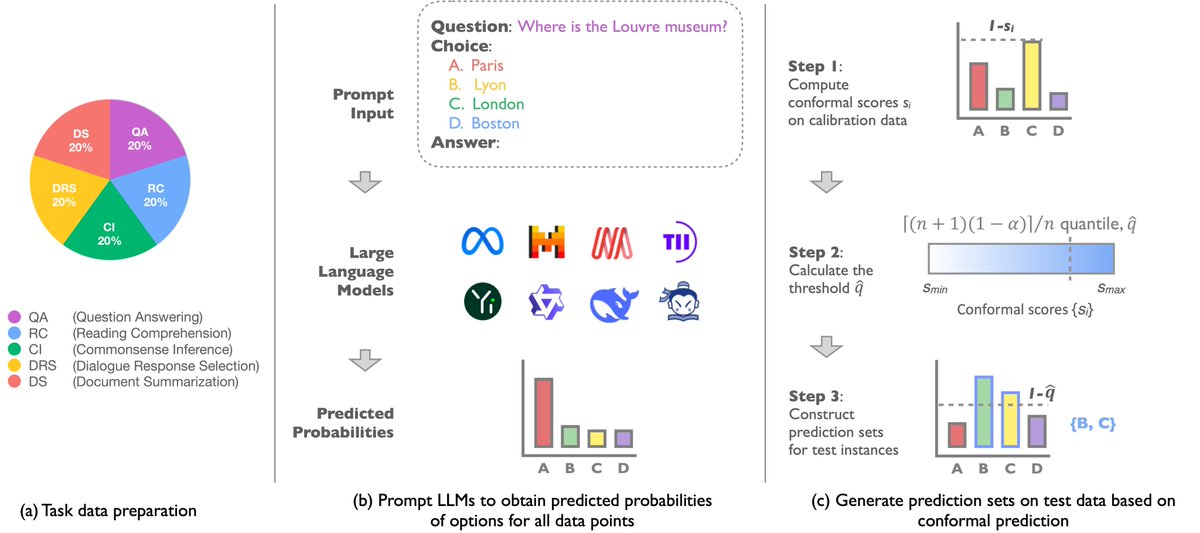
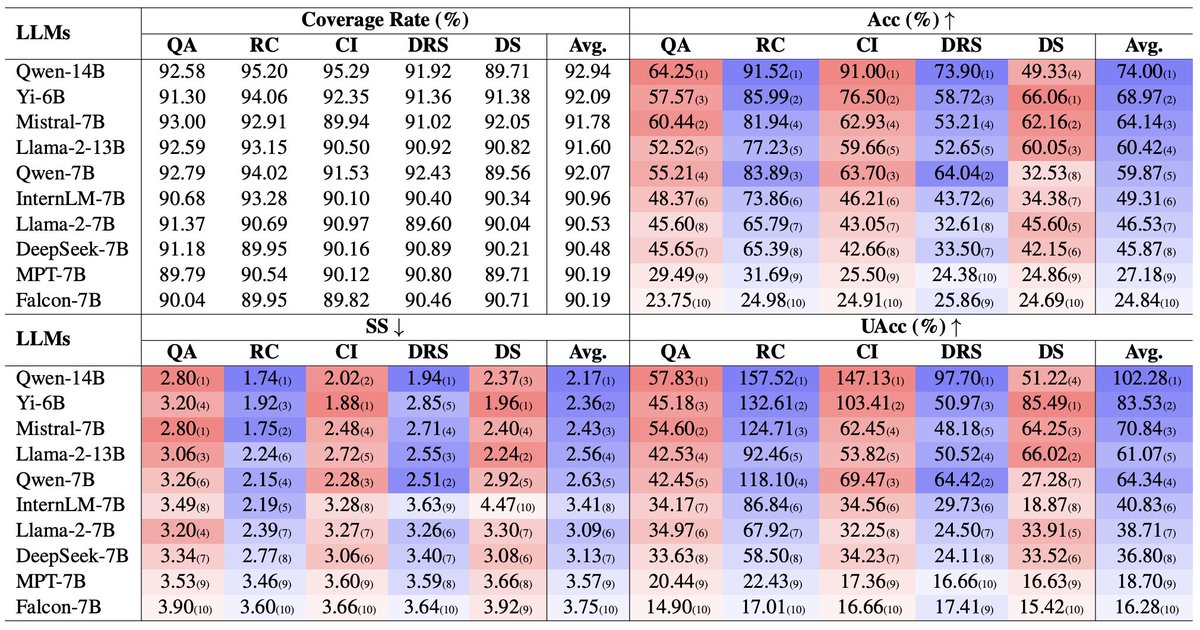
📚 We introduce "Benchmarking LLMs via Uncertainty Quantification", which challenges the status quo in LLM evaluation.
💡 Uncertainty matters too: we propose a novel uncertainty-aware metric, which tests 8 LLMs across 5 leaderboards.
🧐 Accuracy is not everything: (1) High Accuracy, Lower Certainty; (2) Size vs. Uncertainty; (3) Finetuning Effect.
Check out the paper, code, data, and leaderboard:
🎯Arxiv: https://t.co/sHtan56wgg
📈Github: https://t.co/k9xe6TnyQs
FuseChat
Knowledge Fusion of Chat Models
While training large language models (LLMs) from scratch can indeed lead to models with distinct capabilities and strengths, this approach incurs substantial costs and may lead to potential redundancy in competencies. An alternative strategy is to combine existing LLMs into a more robust LLM, thereby diminishing the necessity for expensive pre-training. However, due to the diverse architectures of LLMs, direct parameter blending proves to be unfeasible. Recently, FuseLLM introduced the concept of knowledge fusion to transfer the collective knowledge of multiple structurally varied LLMs into a target LLM through lightweight continual training. In this report, we extend the scalability and flexibility of the FuseLLM framework to realize the fusion of chat LLMs, resulting in FuseChat. FuseChat comprises two main stages. Firstly, we undertake knowledge fusion for structurally and scale-varied source LLMs to derive multiple target LLMs of identical structure and size via lightweight fine-tuning. Then, these target LLMs are merged within the parameter space, wherein we propose a novel method for determining the merging weights based on the variation ratio of parameter matrices before and after fine-tuning. We validate our approach using three prominent chat LLMs with diverse architectures and scales, namely NH2-Mixtral-8x7B, NH2-Solar-10.7B, and OpenChat-3.5-7B. Experimental results spanning various chat domains demonstrate the superiority of \textsc{FuseChat-7B} across a broad spectrum of chat LLMs at 7B and 34B scales, even surpassing GPT-3.5 (March) and approaching Mixtral-8x7B-Instruct.