"100x data efficiency" is not at all fair assessment, it's max 2.5%.
Training on a specific subset of the nemotron data, evaluated only on tasks that are related to that subset, can't be compared with Qwen etc that were trained on much broader data distributions.
The nanoGPT speedrun baseline is apples-to-apples and is nowhere near 100x. It's 1-2.5%.
Introducing Aurora, a new optimizer for training frontier-scale models.
We train Aurora-1.1B, which achieves 100x data efficiency on open-source internet data. Despite having 25% fewer parameters, 2 orders of magnitude fewer training tokens, and using fully open-source internet-only data, Aurora matches Qwen3-1.7B on several benchmarks.
Aurora was developed after identifying a major failure mode that can occur under Muon, an increasingly popular optimizer that has shown strong gains over Adam(W). We find that Muon can cause a huge percentage of neurons to effectively die early in training, reducing effective network capacity so that many parameters no longer meaningfully contribute to network outputs.
By redistributing update energy more uniformly across neurons while preserving Muon’s stability properties, Aurora prevents neuron death and recovers substantial model capacity.
What makes this work especially exciting is that it points toward a broader direction for ML research: better optimizers may not come purely from elegant mathematical abstractions, but from understanding and addressing the concrete dynamics and pathologies that emerge inside real training systems.
Dylan on why memory prices will double again:
"Memory can only grow capacity low double digit percentages a year. 20-30% a year, even less for NAND, a little bit higher for DRAM, but whatever.
Even though the demand signal was very strong at the end of 2025, the memory companies immediately started reacting.
None of that incremental capacity really gets here until 2028, even if they wanted to build as fast as possible.
So the result is memory prices have gone through the roof.
They're going to double and triple again. DRAM, especially.
People are like, "oh, the memory story is overplayed." No, you don't get it. DRAM will double or triple from here still, because that's how much capacity is required.
And they have to steal capacity from somewhere else. And the only way to steal capacity from somewhere else in a capitalist economy is demand destruction via higher pricing."
Actually, AI already saves lives.
In several countries, mammograms are examined by AI and radiologists. Reliability is improved.
In the EU, every car sold must be equipped with Automatic Emergency Braking Systems. That's AI. They reduce frontal collisions by 40%.
Modern MRI machines are equipped with AI technology that reduces the time of imaging by 4x or more. You can now get a full-body MRI in 40 minutes for about $1000. Reduced time -> reduced cost -> more/earlier detection.
And that's not counting the progress in medicine enabled by modern AI, including Nobel Prize-winning protein structure prediction.
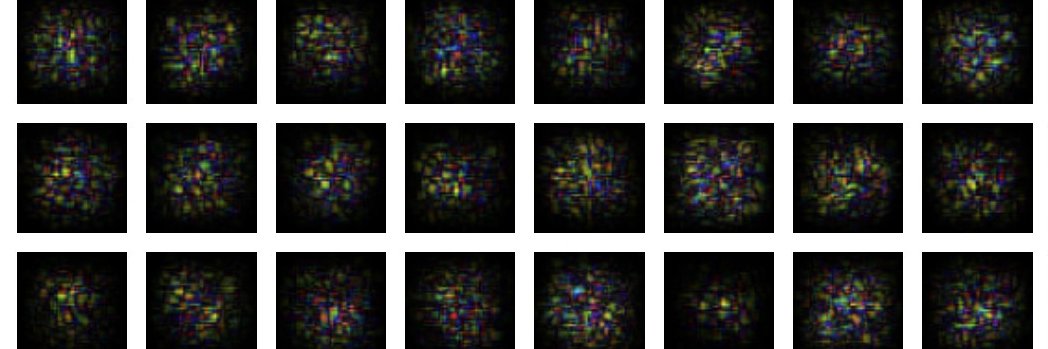
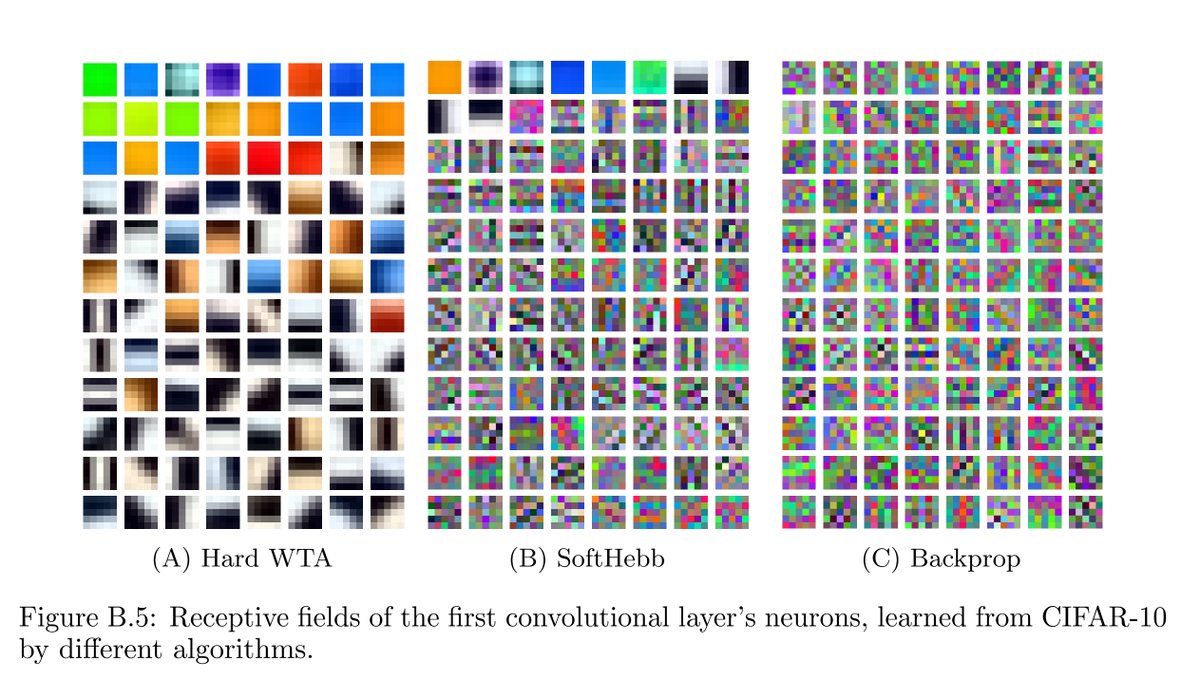
True for most intents and purposes, but learning in ConvNets without backprop, with local learning rules instead, converges to quite different features.
Figure from our ICLR 2023 "Hebbian Deep Learning Without Feedback" (appendix B), where we showed you can pretrain multilayer nets even on ImageNet, with fully local learning, no backprop. That was previously thought impossible. At @noemon_ai we are now scaling local learning rules much further.
I miss ConvNets
Much simpler and more intuitive than transformers
Early layers would always converge to the same features, regardless of the training paradigm
Check out @mervenoyann talking about the evolution of modern computer vision
@PaulGavrikov Makes a lot of sense!
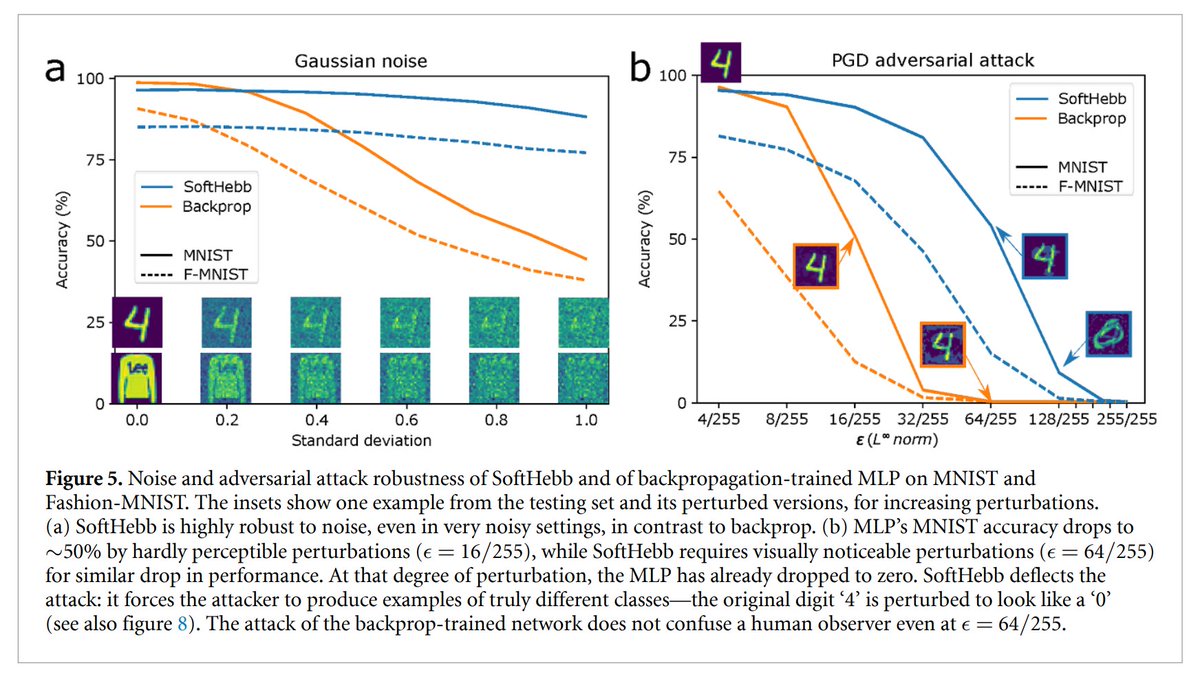
Also, you may find interesting that Hebbian learning can lead to adversarial robustness without any explicit defense.
https://t.co/jOcIbf5d33
Models trained with certain biologically-inspired local learning rules rather than backpropagation can be MUCH more robust to adversarial attacks, as we have shown in the past.
Our view at @noemon_ai is that the locality of Hebbian plasticity in certain architectures leads to more compositional features, which in turn helps address the binding problem and adversarial robustness.
In this new framework of "Perceptual Manifold" (PM) by @AleSalvatore00, @stanislavfort and @SuryaGanguli, our models would have measurably smaller PM than the backprop-trained ones.
- Developed by Sony here in Zurich 🇨🇭
- Uses the event-based vision sensor (aka silicon retina) that spinned off from ETH Zurich and University of Zurich (Institute of Neuroinformatics, my alma matter)
- Direct descendant of the 17-year-old Robo Goalie by Prof. Tobi Delbruck also from INI, which used Tobi's group's DVS sensor. There is a video of it on youtube.
Incredible work by Sony published in @Nature today! 🏓
They’ve built “Ace”, an autonomous ping-pong robot that uses RL and Sony’s vision sensors to achieve expert-level play in ping pong. A huge leap forward for adaptive robotics.
https://t.co/hJqnZzXV17