A lot of the emails I get from founders are now written in a hard-hitting journalistic style. I know they're written by AI, because no founder ever wrote this way before. And once you realize something is written by AI, it's hard not to ignore it.
这篇文章的讨论很有意思,也就是大部分 AI 用户可能都思考过一个问题:长期依赖 coding agent 工具,会不会让人“降智”,甚至丧失社会价值?
文章中的实验数据:
1. Anthropic 2026 年初的随机对照试验:
让工程师学习全新的 Python 库,一半有 AI 辅助,一半没有。两组完成任务速度相同,但在随后的理解力测试中,AI 组惨败(50% vs 67%)。最有趣的分化在 AI 组内部:利用 AI 提问概念性问题的得分 65%+;而直接复制粘贴生成代码的得分不到 40%。
2. MIT 的研究《玩转 ChatGPT 的大脑》(Your Brain on ChatGPT):
脑电图(EEG)测量显示,外部支持每多一层,大脑的连接度就下降一阶。写完文章后,83% 的大模型使用者甚至无法背诵出自己刚刚写下的哪怕一句话。 研究人员称之为认知债(cognitive debt):今天省下的脑力,明天要在批判性思维上加倍偿还。
这些实验证实了 AI 确实在悄悄侵蚀我们的思考。但硬币的另一面,则是那个同样现实的拷问:“既然 AI 都能做了,为什么我还需要理解它?”
这个反向逻辑也完全成立:AI 已经可以高效解决这些问题,且未来的 AI 只会更强大。在这种情况下,即使增加人脑的彻底理解,对任务最终的交付以及社会生产力的提升,似乎并无实质帮助。
所以,在 AI 时代人类究竟是否还需要学习?如果需要,又该学习什么?文章有一些结论,但是感觉这依然是一个长期留给所有人去探索的开放命题。
¿Alguna vez has visto cómo un agente de IA se queda corto de contexto… no porque le falte inteligencia, sino porque desperdicia miles de tokens solo para leer código?
Usa cat o grep un par de veces en un archivo mediano y, de repente, la ventana de contexto ya está medio llena de información que ni siquiera necesitaba. Hazlo en la siguiente pregunta y el problema se multiplica.
En codebases reales, esto se convierte en el cuello de botella silencioso que limita lo que los agentes pueden lograr.
[pluck] llega para cambiar esa ecuación.
Es un motor de recuperación de código escrito en Rust, nativo de MCP (Model Context Protocol), diseñado específicamente para que los agentes de IA lean y naveguen código de forma inteligente.
El resultado medido: entre un 84 % y un 88 % menos tokens en lecturas típicas de código, manteniendo (o incluso mejorando) la capacidad de entender lo que realmente importa.
En vez de servir archivos completos o fragmentos arbitrarios, pluck hace chunking a nivel AST con Tree-sitter. Entiende funciones, clases, bloques lógicos y firmas. Luego combina dos mundos:
- Búsqueda por palabras clave avanzada (BM25F con campos)
- Ranking semántico con embeddings estáticos (sin inferencia en tiempo de ejecución)
El sistema usa una cascada de dos etapas + fusión RRF para que las consultas en lenguaje natural y las búsquedas simbólicas funcionen igual de bien. Todo indexado localmente en un daemon persistente que responde en 0,07 ms (p50 en caliente).
Y hay una capa extra muy potente: deduplicación por sesión. Si ya mostraste un chunk en una interacción anterior, lo reemplaza por un placeholder ligero. Eso añade otro 23 % de ahorro en conversaciones multi-turno.
pluck no se limita a "buscar".
Ofrece un conjunto rico de operaciones pensadas para agentes:
- read → devuelve un outline inteligente (firmas + cuerpos de helpers inline). Ahorro típico del 85-88 % en archivos grandes.
- symbol, peek, impact y deps → navegas grafos de llamadas, imports y dependencias sin tener que reconstruirlos tú.
- digest → comprime logs de CI y tests manteniendo los errores clave (71 % menos tokens).
- plan → sugiere los siguientes 3-5 pasos de exploración que el agente debería dar.
Y lo más importante: siempre existe el modo --raw que devuelve exactamente lo mismo que cat o grep byte por byte. Nunca pierdes la capacidad original. Es un reemplazo inteligente, no una limitación.
pluck no es "otra herramienta de búsqueda".
Es infraestructura pensada para la era de los agentes de coding.
Mientras más eficientes sean recuperando contexto relevante, más lejos podrán llegar antes de chocar contra los límites de tokens.
REPOOO👇
Anthropic is pushing HTML artifacts as the future of AI workflows.
What they're not telling you: a markdown report costs ~800 tokens. The same content in styled HTML costs 2,500-4,000.
That's 3-5x more tokens burned on divs and CSS instead of reasoning and depth.
More tokens spent per task means more API calls. More API calls means more revenue. The incentive is right there.
I steelmanned every major argument for HTML-first workflows and pressure-tested what holds up.
One out of five survived.
Most agentic CLIs are built in TypeScript.
Here’s why that’s a mistake (and you should use Go instead):
We'll use Michael @maximilien as an example…
He built his Weave CLI with Go.
He's also the former CTO at IBM and former Chairperson of the NodeJS Foundation.
So this is not a “TypeScript is bad” take...
He knows the ecosystem deeply.
But when he started building Weave CLI, an open-source tool for production RAG across 11 vector databases, the constraints were different.
He needed something that could run anywhere.
And this is where Go shines.
It has no:
• npm install
• Python virtual envs
• uv issues
• JVM setup
• Broken package registries
• On-prem network restrictions
Just download the binary, make it executable, and run it.
Weave CLI has to:
• Spin up vector databases
• Ingest documents
• Run RAG agents
• Compare embeddings
• Benchmark configurations
• Monitor traces & experiments with Opik by @Cometml
For this kind of infrastructure tooling, installation friction is product friction.
If users can’t run it easily, they won’t use it.
But there's a deeper lesson in this:
Don’t pick your stack based on the herd.
Pick it based on what the system needs.
For frontend-heavy agent apps, TypeScript may be the right choice.
For infra-heavy CLIs and TUIs that need to run anywhere, Go is hard to beat.
Full Weave CLI case study in Decoding AI Magazine: https://t.co/MpJ3bYuH8g
Thinky's secret plan:
1: Increase Human<->AI bandwidth
2: Raise ceiling of human+AI intelligence
3: Help humans continue as main-characters in the new world
We are at Step 1.
Interaction Models are great real-time collaborative tools for humans.
Here's a preview:
Yesterday @coinbase experienced a multi-hour service disruption affecting trading, exchange access, and balance updates. Here's our initial read from Coinbase engineering on what happened, how we recovered, and what we're addressing.
At approximately 23:50 UTC on 2026-05-07, our monitoring detected cascading quote failures from internal services that triggered multiple Sev1 incidents that engineering immediately began investigating. Customer-facing impacts included spot trading, Prime, International and derivative exchanges.
Root cause: a thermal event (cooling system failure) inside a subset of racks within a single building in AWS us-east-1. We run a primary replica of our exchange infrastructure in a single zone, consistent with industry standards to reduce latency. To prepare for failures like this, we maintain a distributed standby, but during this incident, failures in the primary zone that were designed to be isolated were not, extending the duration of our outage.
The failure cascaded down two paths:
1. Multiple hardware components beneath our exchange’s matching engine failed, requiring recovery and failover
2. Distributed Kafka clusters that manage messaging across Coinbase systems failed to remain available, also requiring partition failovers to new hardware brokers with many TiBs of data
After isolating the incident: automated tooling drained ~10 Kubernetes clusters worth of related workloads out of the affected zone to stabilize internal services. Most services were back to normal within ~30 minutes of diagnosis. The two things we couldn't automatically drain: the exchange (dedicated hardware and storage) and Kafka (managed service that was designed to be resilient to this, with unique problems).
The exchange matching engine is the core system responsible for processing orders and maintaining order books. It is a distributed cluster and requires quorum to safely elect a leader and continue processing trading activity. During the incident, infrastructure-level constraints in the affected datacenter left only a subset of nodes healthy, preventing the cluster from reaching quorum. As a result, trading across Retail, Advanced, and Institutional exchanges were blocked.
Recovery required our oncall and engineering teams to execute our disaster recovery plan, restore quorum safely, and validate system health under constrained infrastructure conditions. The team built, tested, deployed, and validated the fix while continuing to manage the broader incident.
Kafka recovery was a much larger scale operation. Our primary managed Kafka partitions process many terabytes of data daily and are designed with resiliency guarantees for uninterrupted operation during a datacenter failure just like this. In this case, those guarantees failed and required manual recovery.
We again relied on disaster recovery procedures to recover stuck partitions onto new hardware (brokers) that enabled us to safely bring x-service messaging back online across Coinbase. During the lag, customers saw delayed balance streams which resolved automatically once replication caught up. No data lost.
Once the engine came back up as part of our standard runbooks, we re-opened markets carefully: all products to cancel-only mode first, audited product states, then moved all markets to auction mode, before restoring trading on Coinbase Exchange.
What went right: the team. Incident response across the company came together within minutes, followed well-rehearsed playbooks and used secure automation tooling to recover all services. We have a strong, senior team at Coinbase that worked through rare failure modes to recover all services.
To our customers: losing access to your account, even temporarily, is unacceptable. We know that. We're sorry, and we’ll publish a full root cause analysis in the coming weeks 🙏
Why did xAI hand over a 220,000-GPU cluster to Anthropic?
The technical backdrop to xAI's decision to hand Colossus 1 over to Anthropic in its entirety is more interesting than it appears. xAI deployed more than 220,000 NVIDIA GPUs at its Colossus 1 data center in Memphis. Of these, roughly 150,000 are estimated to be H100s, 50,000 H200s, and 20,000 GB200s. In other words, three different generations of silicon are mixed together inside a single cluster — a "heterogeneous architecture."
For distributed training, however, this configuration is close to a disaster, according to engineers familiar with the setup. In distributed training, 100,000 GPUs must finish a single step simultaneously before the cluster can advance to the next one. Even if the GB200s finish their computation first, the remaining 99,999 chips have to wait for the slower H100s — or for any GPU that has hit a stack-related snag — to catch up. This is known as the straggler effect. The 11% GPU utilization rate (MFU: the share of theoretical FLOPs actually realized) at xAI recently reported by The Information can be read as the numerical fallout of this problem. It stands in stark contrast to the 40%-plus MFU figures achieved by Meta and Google.
The problem runs deeper still. As discussed earlier, NVIDIA's NCCL has traditionally been optimized for a ring topology. It works beautifully at the 1,000–10,000 GPU scale, but once you push into the 100,000-unit range, the latency of data traversing the ring once around becomes punishingly long. GPUs need to churn through computations rapidly to keep MFU high, but while they sit waiting endlessly for data to arrive over the network fabric, more than half of the silicon falls into idle. Google sidestepped this bottleneck with its own custom topology (Google's OCS: Apollo/Palomar), but xAI, by my read, has not yet reached that stage.
Layer Blackwell's (GB200) "power smoothing" issue on top, and the picture comes into focus. According to Zeeshan Patel, formerly in charge of multimodal pre-training at xAI, Blackwell GPUs draw power so aggressively that the chip itself includes a hardware feature for smoothing power delivery. xAI's existing software stack, however, was optimized for Hopper and does not understand the characteristics of the new hardware; when it imposes irregular loads on the chip, the silicon physically destructs — literally melts. That means the modeling stack must be rewritten from scratch, which in turn means scaling is far harder than most of us imagine.
Pulling all of this together points to a single conclusion. xAI judged that training frontier models on Colossus 1 simply was not efficient enough to be worthwhile. It therefore moved its own training workloads wholesale onto Colossus 2, built as a 100% Blackwell homogeneous cluster. Colossus 1, on the other hand — whose mixed architecture is far less crippling for inference, which parallelizes more forgivingly — was leased in its entirety to an Anthropic that desperately needed inference capacity.
Many observers point to what looks like a contradiction: Elon Musk poured enormous capital into building Colossus, only to hand the core asset over to a direct competitor in Anthropic. Others read it as xAI capitulating because it is a "middling frontier lab." But these are surface-level reads.
Look at the numbers and a different picture emerges. xAI today holds roughly 550,000+ GPUs in total (on an H100-equivalent performance basis), and Colossus 1 (220,000 units) accounts for only about 40% of the total available capacity. Colossus 2 — built entirely on Blackwell — is already operational and continuing to expand. Elon kept the all-Blackwell homogeneous cluster (Colossus 2) for himself and leased out the older, mixed-generation Colossus 1. In other words, he handed the pain of rewriting the stack — the MFU-11% debacle — to Anthropic, while keeping his own focus on training the next generation of models.
The real point, then, is this. Elon's objective appears to be positioning ahead of the SpaceXAI IPO at a $1.75 trillion valuation, currently floated for as early as June. The narrative SpaceXAI now needs is that xAI — long the "sore finger" — is not merely a research lab burning cash, but a business with a "neo-cloud" model in the mold of AWS, capable of leasing surplus assets at high yields.
From a cost-of-capital perspective, an "AGI cash incinerator" is far less attractive to investors than a "data-center landlord generating cash."
As noted above, the most important detail of the Colossus 1 lease is that it is for inference, not training. Unlike training, inference requires far less tightly synchronized inter-GPU communication. Even when the chips are heterogeneous, the workload parcels out cleanly across them in parallel. The straggler effect — the chief weakness of a mixed cluster — is essentially neutralized for inference workloads.
Furthermore, with Anthropic occupying all 220,000 GPUs as a single tenant, the network-switch jitter (unanticipated latency) that arises under multi-tenancy disappears. The two sides' technical weaknesses end up complementing each other almost exactly.
One insight follows. As a training cluster mixing H100/H200/GB200, Colossus 1 was an asset that could only deliver an MFU of 11%. The moment it was handed over to a single inference customer, however, that asset transformed into a cash-flow asset rented out at roughly $2.60 per GPU-hour (a weighted average of the lease rates across GPU types). For xAI, what was a "cluster from hell" for training has become a "golden goose" minting $5–6 billion in annual revenue when redeployed for inference. Elon's genius, I would argue, lies not in the model but in this asset-rotation structure.
The weight of that $6 billion becomes clearer when set against xAI's income statement. Annualizing xAI's 1Q26 net loss yields roughly $6 billion in losses per year. The $5–6 billion in annual revenue generated by leasing Colossus 1 to Anthropic, in other words, almost perfectly hedges xAI's loss figure. This single deal effectively pulls xAI to break-even.
Heading into the SpaceXAI IPO, this functions as a core line of financial defense. From a cost-of-capital standpoint, if the image shifts from "research lab burning cash" to "infrastructure tollgate stably printing $6 billion a year," the entire tone of the offering can change.
(May 8, 2026, Mirae Asset Securities)
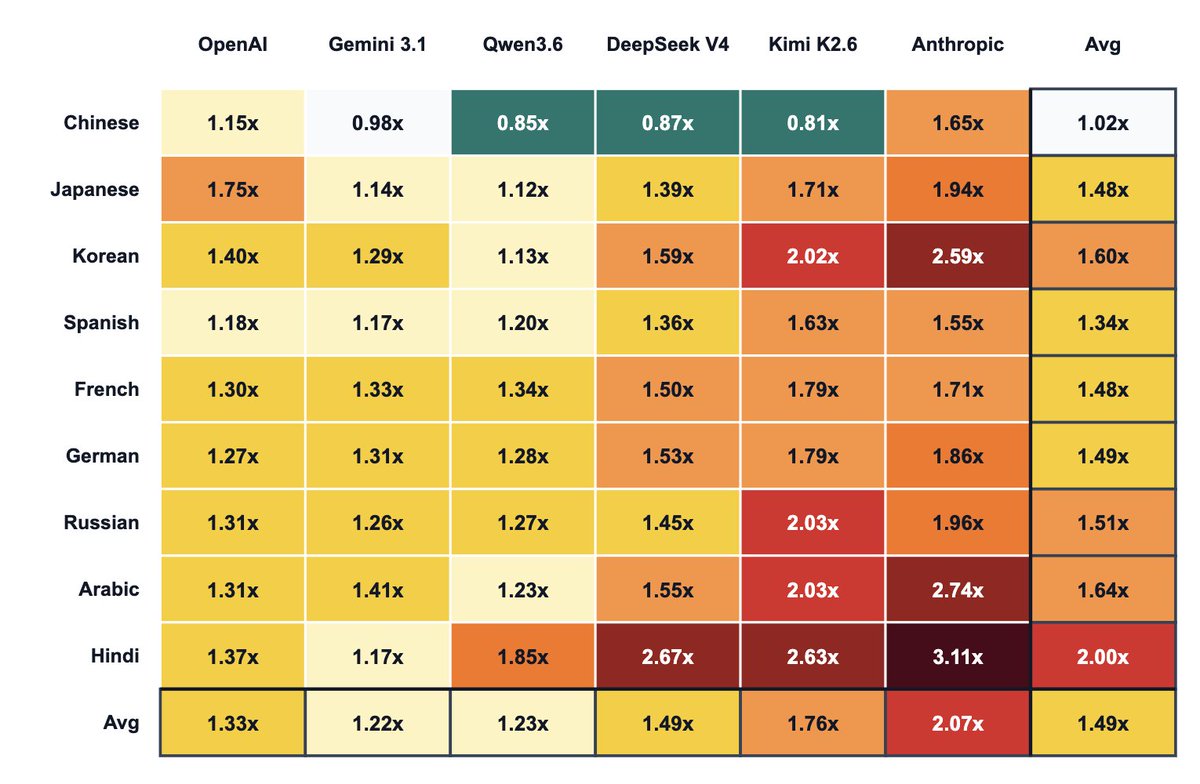
Follow-up on non-English token-inefficiency with more model-language pairs:
- Chinese is cheaper than English on major Chinese models
- Gemini and Qwen provide least non-English tax
- Anthropic has the highest tax by far; Kimi is next
- Hindi is the worst-covered language here, despite its massive speaker base
The highest-value human work in the AI era will be in domains with sparse reward signals. Internalize this, or watch your value erode over the next decade.
Math, programming, rote memorization, data science, all fucked. The classic “smart nerd” jobs are exactly where AI is strongest, because the feedback loops are dense. You can check the answer. You can run the test. That means AI can improve quickly, and humans will rapidly fall behind.
Your advantage as a human is in messy domains.
Taste. Judgment. Negotiation. Risk-taking. Politics. Sales. Science at the frontier. Anything you can only really learn by doing. Cross-disciplinary stuff.
The valuable domains will be the ones guarded by secrets, tacit knowledge, weak labels, long feedback cycles, and ambiguous outcomes. Places where the training data is scarce, the ground truth is disputed, and it's impossible to explain why something is good.
AI will still enter these domains. But we will be slower to trust it unsupervised there, because it will be harder to tell when it is right, harder to prove when it is wrong, and difficult to construct secure sandboxes. The stakes will be too high to YOLO it.
I find myself saying this over and over again to young people today: the future does not belong to people who are able to get good grades on tests. It belongs to people who can operate under uncertainty, in domains where correctness is hard to define.
Those domains will become the thin waist of the economy: as productivity everywhere else accelerates, the humans who excel there will become our economic Strait of Hormuz. The best humans in these domains will demand an enormous cut of the growing economic pie.
Your imperative going forward is to make sure you're one of these people.
(Or become an electrician. That probably works too.)
Polymarket prices are highly accurate in predicting future events. The source of that accuracy is less obvious.
In a new working paper, we find it is not the “wisdom of crowds,” but a small minority of informed traders.
Fewer than 3% of accounts appear to drive price discovery; most perform no better than chance.
The majority generates most of the volume but little of the information, effectively funding the informed minority.
Check the paper here: https://t.co/z5VsKzb1CE
I'm amazed by this line from @deepseek_ai 's official announcement
"Not lured by praise, not frightened by slander, follow the righteous path and discipline oneself with integrity"
DeepSeek's real edge isn't just the tech, it's the ethos behind the work. And that's what will carry them further than any benchmark ❤️


































![ErickSky's tweet photo. ¿Alguna vez has visto cómo un agente de IA se queda corto de contexto… no porque le falte inteligencia, sino porque desperdicia miles de tokens solo para leer código?
Usa cat o grep un par de veces en un archivo mediano y, de repente, la ventana de contexto ya está medio llena de información que ni siquiera necesitaba. Hazlo en la siguiente pregunta y el problema se multiplica.
En codebases reales, esto se convierte en el cuello de botella silencioso que limita lo que los agentes pueden lograr.
[pluck] llega para cambiar esa ecuación.
Es un motor de recuperación de código escrito en Rust, nativo de MCP (Model Context Protocol), diseñado específicamente para que los agentes de IA lean y naveguen código de forma inteligente.
El resultado medido: entre un 84 % y un 88 % menos tokens en lecturas típicas de código, manteniendo (o incluso mejorando) la capacidad de entender lo que realmente importa.
En vez de servir archivos completos o fragmentos arbitrarios, pluck hace chunking a nivel AST con Tree-sitter. Entiende funciones, clases, bloques lógicos y firmas. Luego combina dos mundos:
- Búsqueda por palabras clave avanzada (BM25F con campos)
- Ranking semántico con embeddings estáticos (sin inferencia en tiempo de ejecución)
El sistema usa una cascada de dos etapas + fusión RRF para que las consultas en lenguaje natural y las búsquedas simbólicas funcionen igual de bien. Todo indexado localmente en un daemon persistente que responde en 0,07 ms (p50 en caliente).
Y hay una capa extra muy potente: deduplicación por sesión. Si ya mostraste un chunk en una interacción anterior, lo reemplaza por un placeholder ligero. Eso añade otro 23 % de ahorro en conversaciones multi-turno.
pluck no se limita a "buscar".
Ofrece un conjunto rico de operaciones pensadas para agentes:
- read → devuelve un outline inteligente (firmas + cuerpos de helpers inline). Ahorro típico del 85-88 % en archivos grandes.
- symbol, peek, impact y deps → navegas grafos de llamadas, imports y dependencias sin tener que reconstruirlos tú.
- digest → comprime logs de CI y tests manteniendo los errores clave (71 % menos tokens).
- plan → sugiere los siguientes 3-5 pasos de exploración que el agente debería dar.
Y lo más importante: siempre existe el modo --raw que devuelve exactamente lo mismo que cat o grep byte por byte. Nunca pierdes la capacidad original. Es un reemplazo inteligente, no una limitación.
pluck no es "otra herramienta de búsqueda".
Es infraestructura pensada para la era de los agentes de coding.
Mientras más eficientes sean recuperando contexto relevante, más lejos podrán llegar antes de chocar contra los límites de tokens.
REPOOO👇](https://pbs.twimg.com/media/HIecvMWXkAAtsLP.jpg)