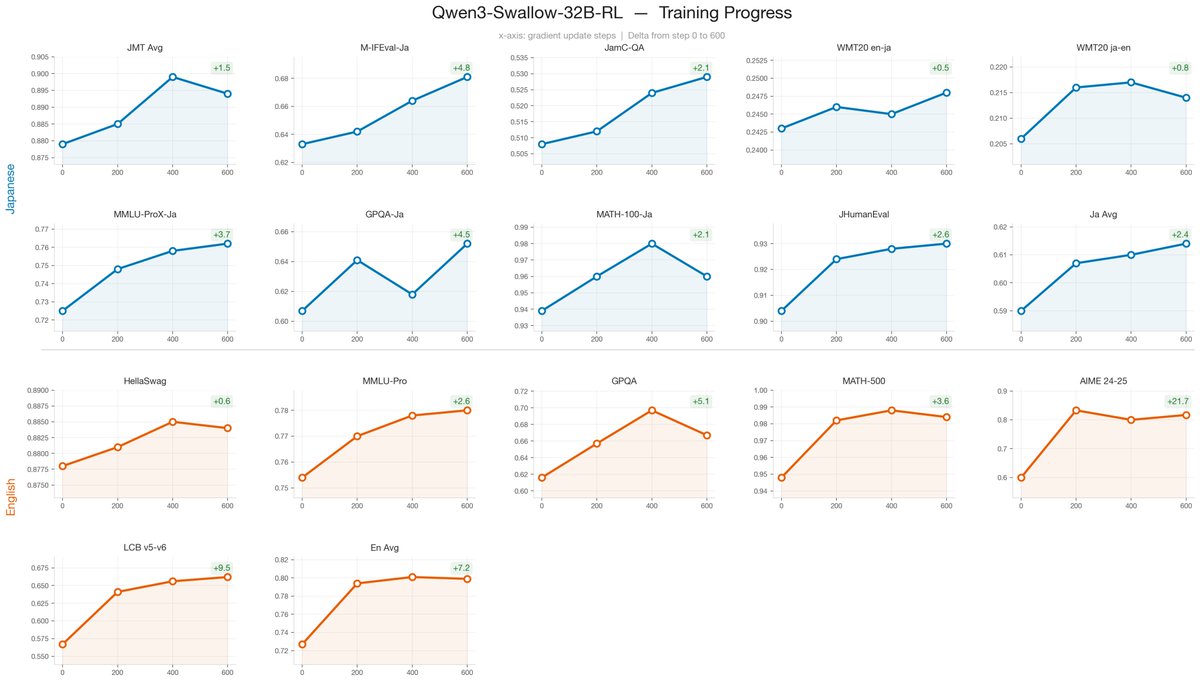
We've officially released Qwen3-Swallow and GPT-OSS-Swallow! 🚀 It’s quite an emotional moment for me, as we’ve been working hard on these models since the summer of 2025.
For this release, I was responsible for the continual pre-training (CPT), SFT, and training data refinement across all models. We successfully enhanced the Japanese language capabilities while fully preserving the strong math and coding performance of the base models.
I'll also be giving a talk about this at NVIDIA GTC 2026 in San Jose, CA! See you there!
#SwallowLLM #GTC2026
We are thrilled to announce the release of GPT-OSS Swallow and Qwen3 Swallow 🎉
I was involved in evaluation, framework development, and mentoring as a student leader.
Leaderboard: https://t.co/CxhlRA2EIO
Swallow-Evaluation-Instruct: https://t.co/OI75Q40ro8
New arXiv preprint! "On the Optimal Reasoning Length for RL-Trained Language Models"
Two failure modes in RL-trained reasoning: long outputs increase dispersion, short outputs cause under-thinking.
This tradeoff can be monotonic or non-monotonic depending on the model.
Finally!! Accepted to ICLR 2026! 🎉
Cited by Nemotron 3 Nano and OLMo 3, yet it was a long journey to get this through academic peer review. So glad to cross the finish line.
📄 Rewriting Pre-Training Data Boosts LLM Performance in Math and Code: https://t.co/tbGL1IPiQf