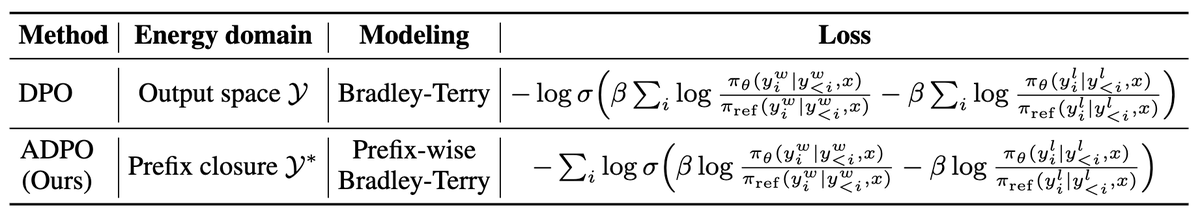We are pleased to announce that, based on the rigorous review process used for ICDAR, your submission listed below has been accepted for presentation:
"JaWildText: A Benchmark for Vision-Language Models on Japanese Scene Text Understanding"
See you in Vienna!! 🇦🇹
#ICDAR2026
@wei_chen_ai Thanks!
It indeed seems quite related.
In ADPO, density ratios are computed prefix-wise and summed after log-sigma. So even if some local ratios become very large (i.e., density chasm problem, I assume?), they may not dominate the objective globally or cause severe instability.
We propose Autoregressive Direct Preference Optimization (ADPO), a new formulation of DPO that explicitly incorporates autoregressive modeling.
ADPO revisits the foundations of DPO and leads to a more principled objective.
📚️https://t.co/Y9fBhZ2LCC
This is the first time preference learning actually respects how LLMs generate — step by step.
ADPO isn’t just a tweak to DPO, it’s a shift from outcome supervision to process-level alignment.
We propose HATCH🐣, a human-inspired training framework for multi-image spatial reasoning in VLMs 🐤
HATCH improves multi-image spatial reasoning ability while preserving single-image reasoning capabilities 🐓
📚️https://t.co/02Ry5iGmn3
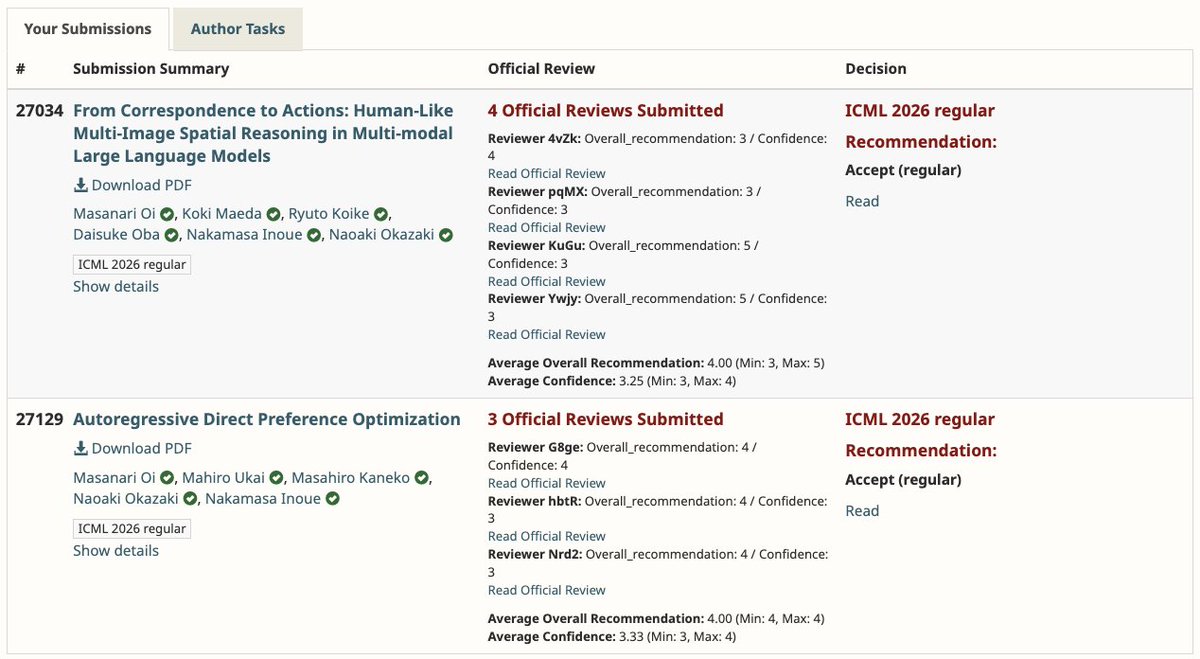
Our paper accepted to #ICML2026 🇰🇷(first author)!
This paper is on budget-aligned test-time scaling of LLMs.
It is my first ML conference paper!
Huge thanks to my co-authors ! @dai0NLP@chokkanorg
Preprint: https://t.co/qPvJFHjxMC
More details soon!
Rewriting Pre-Training Data Boosts LLM Performance in Math and Code #ICLR2026
Sat, Apr 25, 10:30 AM – 1:00 PM
See you in Rio. I’d be glad to talk in person about open LLM development, training libraries, and distributed training.
https://t.co/89gL7OAand
https://t.co/UWFQNIfAov