DiffusionGemma is an open, experimental model that brings our text diffusion research to Gemma 4. It’s a racehorse 🏇achieving up to 4x faster inference by generating entire blocks of text simultaneously vs predicting token-by-token (word-by-word) output!
7/ Takeaway: drifting can refine discrete diffusion LMs when feature-space drift is connected to categorical logits through a soft-token interface.
Paper: https://t.co/3lKdvrsVMd
w/ @frt03_@chokkanorg
1/ New preprint: Drifting Objectives for Refining Discrete Diffusion Language Models
Can drifting be used beyond continuous generators?
We study this in the setting of refining pretrained discrete diffusion language models (DDLMs). Our method, TokenDrift, provides a differentiable soft-token interface that lets feature-space drifting signals update categorical token logits.
Main observation: Gen.-PPL improves throughout drifting training at fixed denoising budgets.
6/ The soft-token part matters.
A straight-through hard-token variant still has a surrogate gradient path, but performs much worse and suffers severe entropy collapse.
So differentiability alone is not enough: the feature encoder needs to see the model's uncertainty through probability-weighted embeddings (pE).
We propose HATCH🐣, a human-inspired training framework for multi-image spatial reasoning in VLMs 🐤
HATCH improves multi-image spatial reasoning ability while preserving single-image reasoning capabilities 🐓
📚️https://t.co/02Ry5iGmn3
Our paper accepted to #ICML2026 🇰🇷(first author)!
This paper is on budget-aligned test-time scaling of LLMs.
It is my first ML conference paper!
Huge thanks to my co-authors ! @dai0NLP@chokkanorg
Preprint: https://t.co/qPvJFHjxMC
More details soon!
Also at #ICLR2026 🇧🇷: Presenting Best-of-∞ on behalf of lead author @jkomiyama_ — principled Bayesian stopping that approximates the N→∞ majority-voting limit, plus optimal LLM-ensemble weights via MILP!
🕓25th April, 10:30 AM
📍Pavilion 4, #4710
w/ @jkomiyama_@stillpedant
Excited to present SureLock at #ICLR2026 🇧🇷 — a principled decoding method that locks converged tokens in Masked Diffusion Language Models, cutting 30–50% FLOPs at same quality!
w/ @Bollegala@MasahiroKaneko_@chokkanorg
🕙 Friday, 24th April, 10:30 AM
📍Pavilion 3 (#826)
🇧🇷 Excited to present our paper "Stopping Computation for Converged Tokens in Masked Diffusion-LM Decoding" at #ICLR2026 in Rio de Janeiro in just two days! 🏖️
https://t.co/eXQb1DWTBU (Friday 24th 10:30-13:00 poster session)
Masked Diffusion LMs generate sequences via iterative sampling, but they waste significant compute by repeatedly re-evaluating tokens that have already converged.
To fix this, we introduce SureLock 🔒: a method that permanently locks stable tokens during decoding. By caching their attention keys/values and skipping their query projection and feed-forward sublayers, we drastically cut down on redundant computation.
🚀 The result? We achieve a 30–50% reduction in algorithmic FLOPs on LLaDA-8B with virtually no loss in generation quality!
If you are attending ICLR, come stop by our presentation! w/ @dai0NLP@MasahiroKaneko_@chokkanorg@LivUni@AmazonScience
code/paper: https://t.co/u5lcUCfI5R
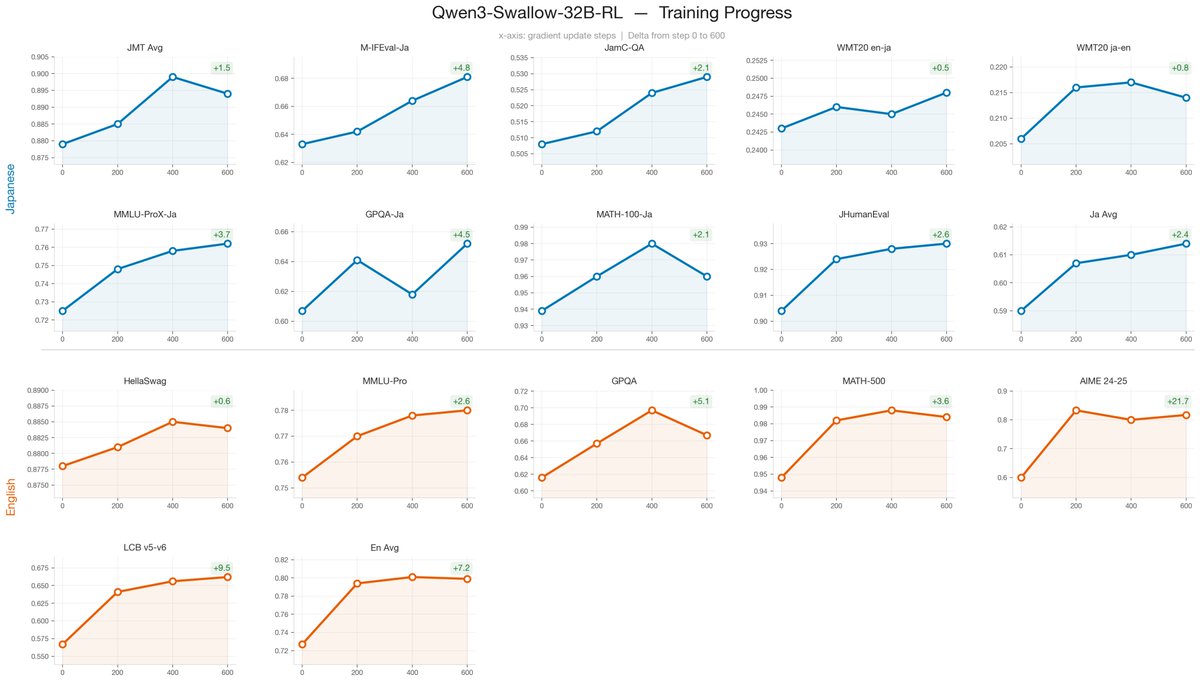
We are thrilled to announce the release of GPT-OSS Swallow and Qwen3 Swallow 🎉
I was involved in evaluation, framework development, and mentoring as a student leader.
Leaderboard: https://t.co/CxhlRA2EIO
Swallow-Evaluation-Instruct: https://t.co/OI75Q40ro8
Two papers accepted to @ICLR 2026 🎉Congrats and kudos to my amazing collaborators.
@dai0NLP@MasahiroKaneko_@chokkanorg
T.Yamamoto R. Kumon
@verypluming
One paper on How to make Diffusion Models efficient and the other on proving the existence of culture-specific neurones.