I'm presenting a poster at @NeurIPSConf DiffCoALG workshop today throughout the day in Upper Level Room 25ABC. I will present our initial theoretical findings on how choosing the right learning architectures can help with model distillation, under a linear rep hypothesis!
It's been wild to see our work on Muon and the anthology start to get scaled up by the big labs.
After @Kimi_Moonshot released Moonlight, people have asked whether Muon is compatible with muP. I wanted to write up an explainer, as there is something deeper going on here!
(1/8)
Are you canonicalizing your data? Depending on the group, you might be unavoidably introducing discontinuity...but there's a fix!
Come to our ICML poster, #511, on Wednesday 1:30 - 3:00 PM to hear more! Joint work with Nadav Dym and Jonathan Siegel
https://t.co/FWe4JaBjd7
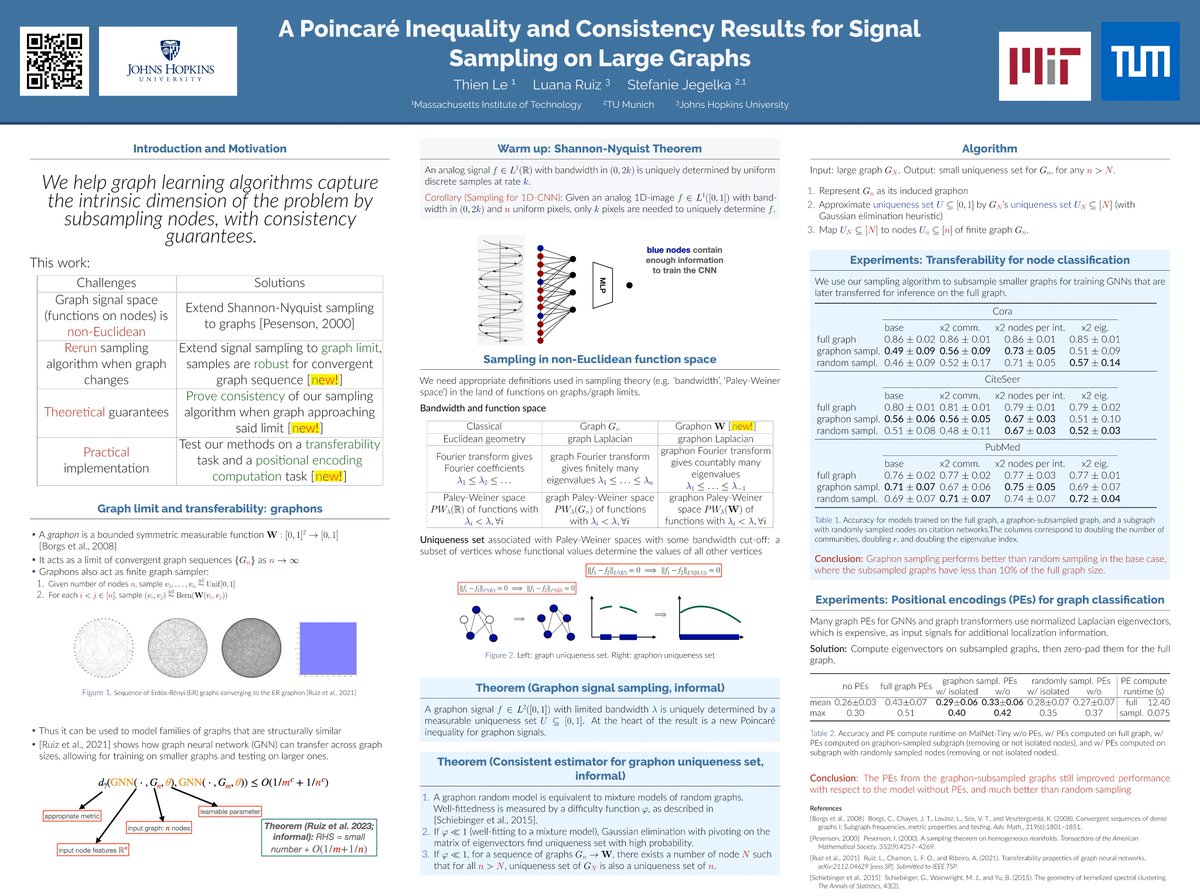
Finally, we derive a heuristic to our algorithm and test it on citation networks for both node classification transferability experiments (train on small graphs, test on large graphs) and positional encoding computations (compute PE on subsampled graphs, then zero pad).(4/4)
How do you robustly subsample vertices of large graphs that are changing in size? By marrying the theory of spectral clustering and graph limit! Check out our poster #36 in Halle B on Friday, 10:45-12:45, presented by the amazing Luana Ruiz!
🔗:https://t.co/cLblYA4att
🧵(1/4)
Interestingly, by using connections to spectral clustering geometry, we show that if the graphon is well-fitted to a mixture model (e.g., stochastic-block), then the necessary number of vertices to sample can be as small as the (finite!) number of components in the mixture.(3/4)
We also derive an exponential lower bound for group averaging shallow real MLPs and a superpolynomial lower bound for frame-averaging them. Along the way, we also introduce techniques that may help bridge traditional learning theory and its equivariance counterpart. (5/5)
Can group equivariance counteract the computational (SQ/CSQ) hardness of learning neural nets? Swing by our poster #202, presented by the wonderful Bobak Kiani and @HLawrenceCS, on Thursday, 10:45 - 12:45 to find out! #ICLR2024
🔗: https://t.co/7uxtgwIHh7
🧵(1/5)
In contrast, for real-valued functions, we demonstrate a large family of shallow GNNs that are almost orthogonal in Gaussian space, thus requiring exponentially many correlational SQ queries (subsuming noisy gradient descent computations) to distinguish. (4/5)
https://t.co/8RKMcUDqLf
I’m delighted to showcase and celebrate a selection of recent papers by the talented combinatorialists at MIT, especially those by students and postdocs. These papers reflect the culmination of their hard work, dedication, and innovative problem solving.
I'll be presenting our work on optimal approximation algorithms for combinatorial problems with graph neural nets at the Mathematics of Modern Machine Learning (M3L) workshop. Saturday 4pm, room 242!
Arxiv: https://t.co/Pydy57ETqA
Excited to present this work on Wednesday! Also, if you’re at NeurIPS and want to chat about equivariant learning, AI for science, or anything else, don’t hesitate to reach out 😄
In our paper, we leverage a new tool from the theory of graph limit, called graphop and action convergence (Backhausz and Szegedy, 2022) to give structural conditions under which parameters of GNNs on a sequence of graphs discretized from the same limit object can transfer. 4/4
Excited to present a joint work with Stefanie Jegelka at NeurIPS 2023 Thursday morning poster session. Our paper (https://t.co/ntborvYjOn) studies size transferability of graph neural networks with special attention to sparse (even bounded-degree) graph sequences. 1/4
This observation has been formalized for dense graphs via different random graph models and graph limit notions (e.g. graphons). On the other hand, little is known about size-transferability of sparse graph sequences - whose limit spectrum may exhibit pathological behaviors. 3/4