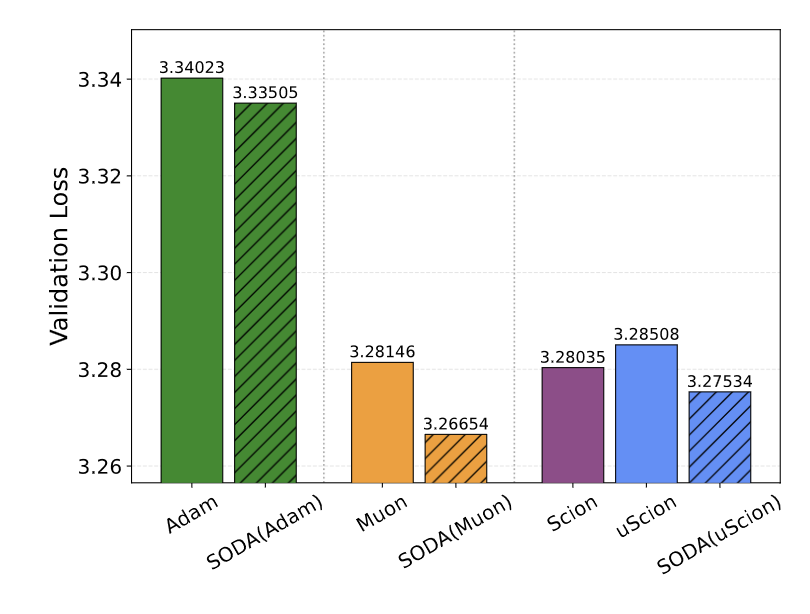
1/ We introduce SODA: a simple optimizer wrapper that improves a base optimizer, adds no hyperparameters, and removes the need to tune weight decay.
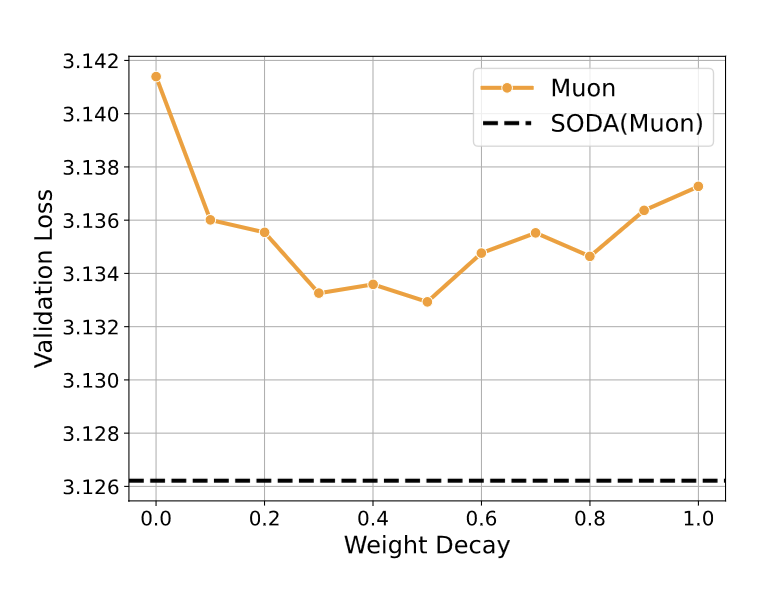
The wrapper provides consistent improvement. Most notably, SODA(Muon) beats Muon even when Muon gets a tuned weight decay sweep.
SODA-AMUSE+Gram+PMuon is the recipe that wins consistently on 4/4 codex GPU instances.
PMuon is a new idea: https://t.co/Zh6QCYFwGo
AMUSE is Muon + ScheduleFree: https://t.co/ZBEFoRWdkA
SODA is a wrapper that's more popular: https://t.co/OWuWxNFYl0
Gram is a lesser known Gram-Newton-Schultz optimization: https://t.co/qin6o8SexN
@jlylekim Looks interesting! We’re using schedule-free to get rid of weight decay tuning in https://t.co/f25xr2KEMX - I’m curious if you can somehow combine to get rid of both
1/ We introduce SODA: a simple optimizer wrapper that improves a base optimizer, adds no hyperparameters, and removes the need to tune weight decay.
The wrapper provides consistent improvement. Most notably, SODA(Muon) beats Muon even when Muon gets a tuned weight decay sweep.
7/ Thanks to @CevherLIONS for supporting it and getting Roman Macháček on board, and @WanyunXie for scaling up the experiments and debugging runs together – it’s always a joy
1/ We introduce SODA: a simple optimizer wrapper that improves a base optimizer, adds no hyperparameters, and removes the need to tune weight decay.
The wrapper provides consistent improvement. Most notably, SODA(Muon) beats Muon even when Muon gets a tuned weight decay sweep.
6/ There are a lot of interesting questions one can ask from this perspective — please check out the paper!
Paper: https://t.co/f25xr2KEMX
Code: https://t.co/lqZiHiqD0t
@EIFY@tonysilveti One reason I find z0 appearing interesting is for finetuning where weight decay is otherwise typically not used (I added a comment on this in the conclusion) - but that’s a story in itself
@EIFY@tonysilveti We haven’t ablated this beyond 1 x chinchilla with a 124M model (the main setting where I tested things before we extrapolated across horizon and model size)
@CV_novel_plume Yes, this is exactly the SODA wrapper! I wanted to extract something concrete from the perspective and I was at the time trying to understand weight decay - surprisingly the first thing I tried (just using params from theory) worked without any retuning of lr etc of the base opt
@_arohan_ Yes, non-constant is interesting to explore. The GPA paper by @aaron_defazio has a very nice perspective on diloco also through schedule-free, which makes the delta/diff from SODA easier to understand (I've compared in the related work section)
@wen_kaiyue@tonysilveti Your comment about optimism is interesting. I mainly focused on extracting a schedule for weight decay in this work, but there is an interesting question on how to schedule optimism and weight decay in tandem to better exploit smoothness
@wen_kaiyue@tonysilveti Its actually not quite batch size independent - if you squint the convergence theorem suggests a constant then 1/√k (the changepoint will depend on noise), but we didn't investigate this much empirically yet
@tonysilveti Yeah, except even for MLP blocks RMSNorm(W2σ(W1)) its ok for both matrices as long as the activation function is positively homogeneous (e.g., true for ReLU and ReLU^2)