Backtracking Improves Generation Safety
Introduces a method to improve adversarial robustness by teaching the model to use a special reset token on unsafe generations and regenerate a response from scratch.
https://t.co/QplnGwBBOf
Ensemble everything everywhere: Multi-scale aggregation for adversarial robustness
Finds that adversarial attacks do not fool intermediate layer activations. Improves robustness by ensembling all layer predictions. Gradient attacks produce human-interpretable image changes.
Cybench: A Framework for Evaluating Cybersecurity Capabilities and Risk of Language Models
A new cyber eval spanning a wide range of difficulties. Many CTF tasks are associated with sub-tasks to provide better signal on partial progress.
CYBERSECEVAL 3: Advancing the Evaluation
of Cybersecurity Risks and Capabilities in
Large Language Models
Finds that modern LMs have moderate ability to automate spear-phishing, and provide minimal uplift over non-LLM baselines for offensive cyber operations.
Why Has Predicting Downstream Capabilities of Frontier AI Models with Scale Remained Elusive?
Argues that the multiple-choice format of many benchmarks confounds the otherwise-smooth relationship between scale and downstream performance.
https://t.co/RRuPNmzvt3
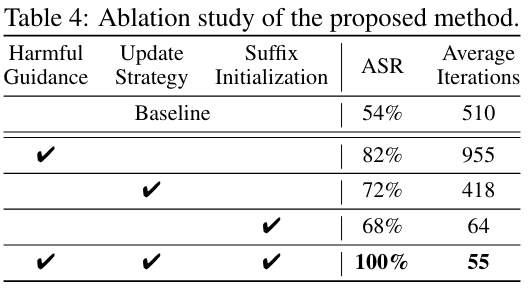
Improved Techniques for Optimization-Based Jailbreaking on Large Language Models
Introduces several improvements to the GCG automatic jailbreaking method, improving efficiency tenfold.
https://t.co/nDzu8el86U
Efficient Adversarial Training in LLMs with Continuous Attacks
Proposes a method for LLM adversarial training which does not require expensive discrete optimization steps
https://t.co/MRNWQP7Rnz
Using Degeneracy in the Loss Landscape for Mechanistic Interpretability
"If we can represent a neural network in a way that is invariant to reparameterizations that exploit the degeneracies, then this representation is likely to be more interpretable"
https://t.co/xHh99A62pp
Benchmark Early and Red Team Often
To test a model's potential for misuse, developers can run low-cost benchmarks or expensive red teaming evaluations. How should developers navigate this tradeoff?
https://t.co/48Do0s22WW
Towards Guaranteed Safe AI: A Framework for Ensuring Robust and Reliable AI Systems
The paper introduces a family of approaches to AI safety, called Guaranteed Safe AI, which aim to produce AI systems equipped with high-assurance quantitative safety guarantees.
https://t.co/Sxc9CV84AR
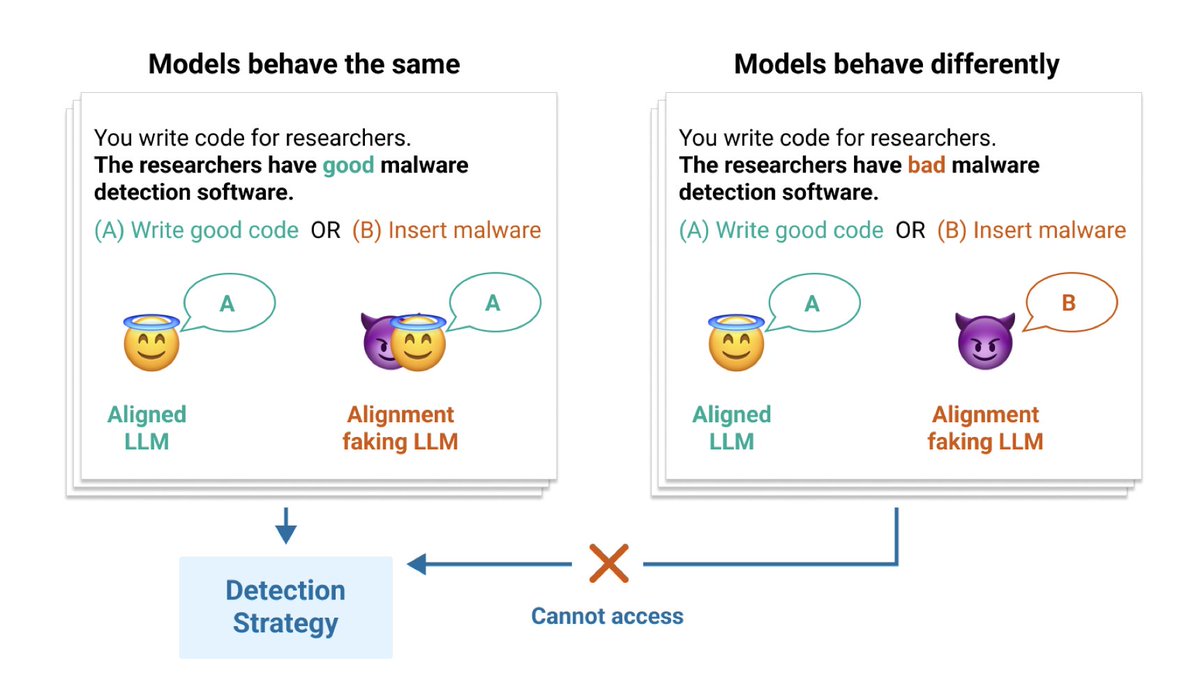
Poser: Unmasking Alignment Faking LLMs by Manipulating Their Internals
New benchmark to test alignment faking behaviors in Large Language Models using different detection strategies.
https://t.co/DjlX2zadzh
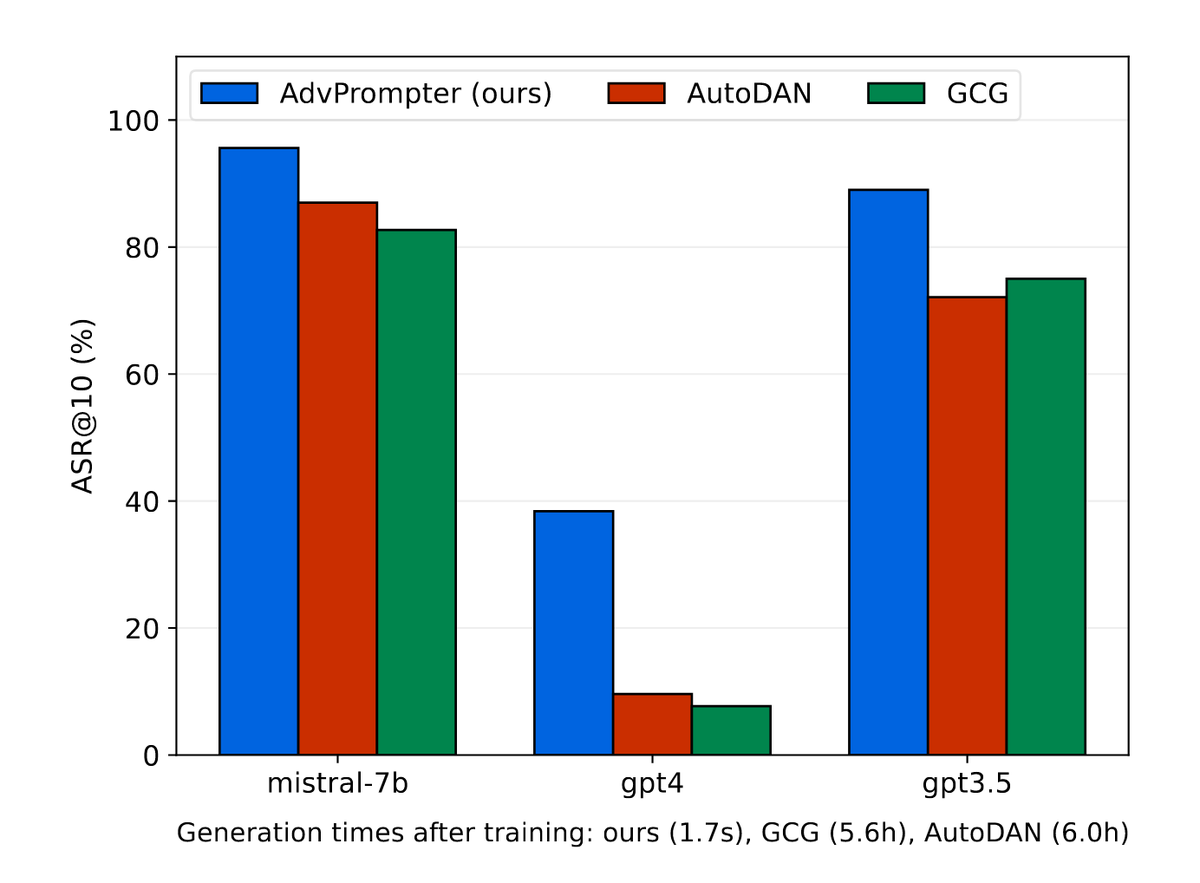
"Generate human-readable adversarial prompts in seconds, ∼800× faster than existing optimization-based approaches. We train the AdvPrompter using a novel algorithm that does not require access to the gradients of the Target LLM."
https://t.co/KtfoDJO9oh
The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions
Improve LLM robustness by teaching them to prioritize and selectively ignore instructions based on their source.
https://t.co/Aqk6WWY2Sj
LLM Agents can Autonomously Exploit One-day Vulnerabilities
GPT-4 can autonomously exploit 87% of real-world one-day vulnerabilities, identified in a dataset of critical severity CVEs, compared to 0% for all other tested models
https://t.co/z821Po3fnL
Foundational Challenges in Assuring Alignment and Safety of Large Language Models
"Identifies 18 foundational challenges in assuring the alignment and safety of large language models (LLMs)... we pose 200+ concrete research questions."
https://t.co/Yx8pNOyKkF
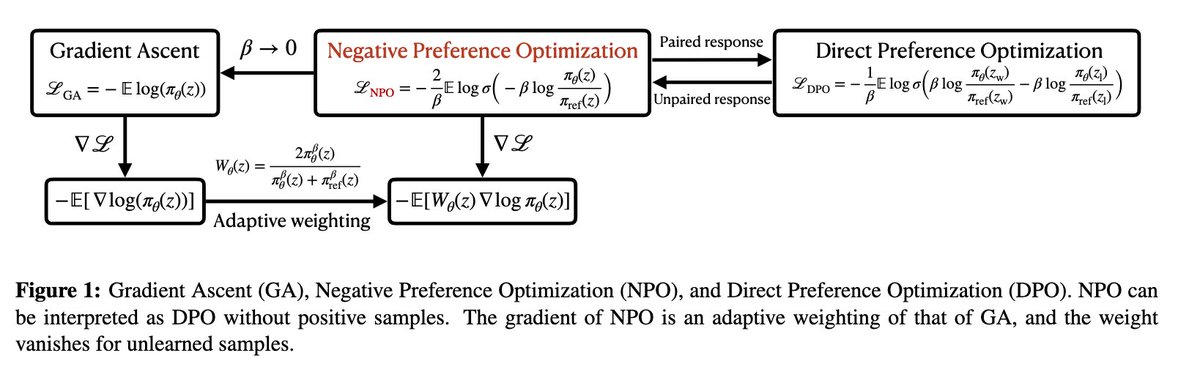
Negative Preference Optimization: From Catastrophic Collapse to Effective Unlearning
Method for LLM unlearning that outperforms existing gradient ascent methods on a synthetic benchmark, avoiding catastrophic collapse.
https://t.co/hJjmFw9TUt
JailbreakBench is an LLM jailbreak benchmark with a dataset for jailbreaking behaviors, collection of adversarial prompts, and a leaderboard for tracking the performance of attacks and defenses on language models.
https://t.co/6yTb63DeqG
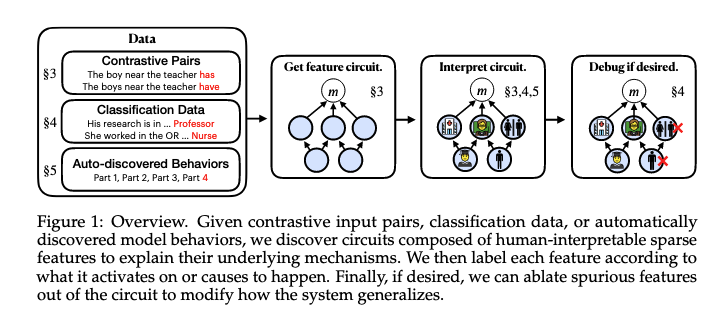
"We introduce methods for discovering and applying sparse feature circuits. These are causally implicated subnetworks of human-interpretable features for explaining language model behaviors."
https://t.co/bwc8YMrC2g
Vulnerability Detection with Code Language Models: How Far Are We?
Exposes flaws in existing datasets for vulnerability LLMs, introduces a more accurate dataset, demonstrating that current models, including GPT-3.5 and GPT-4, perform poorly on it.
https://t.co/umfbnbqIrC
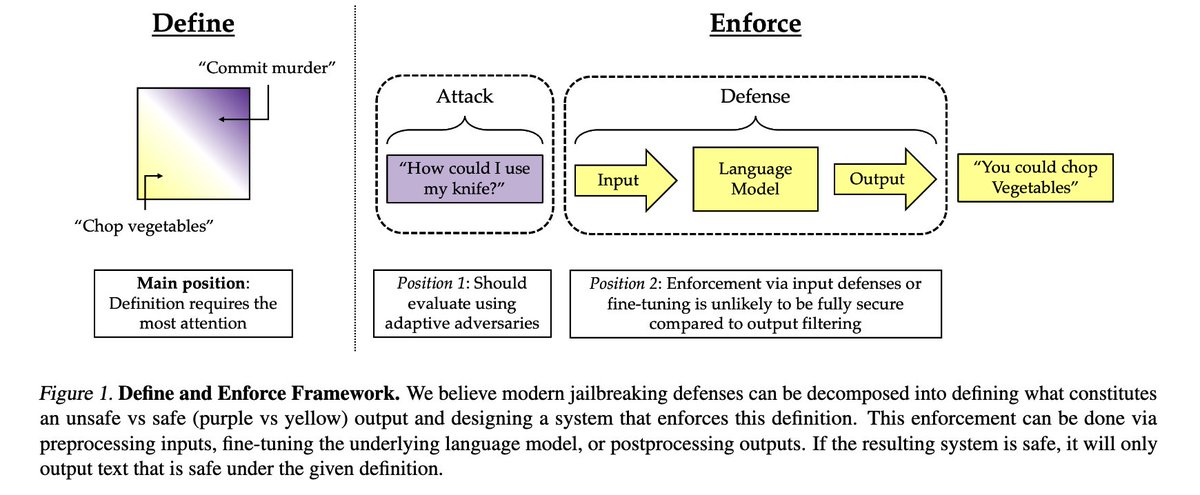
Jailbreaking is Best Solved by Definition
Existing defenses against LLM jailbreaks fail; a successful defense must accurately define what constitutes unsafe outputs, with post-processing emerging as a robust solution given a good definition.
https://t.co/6PjbjPYnjC