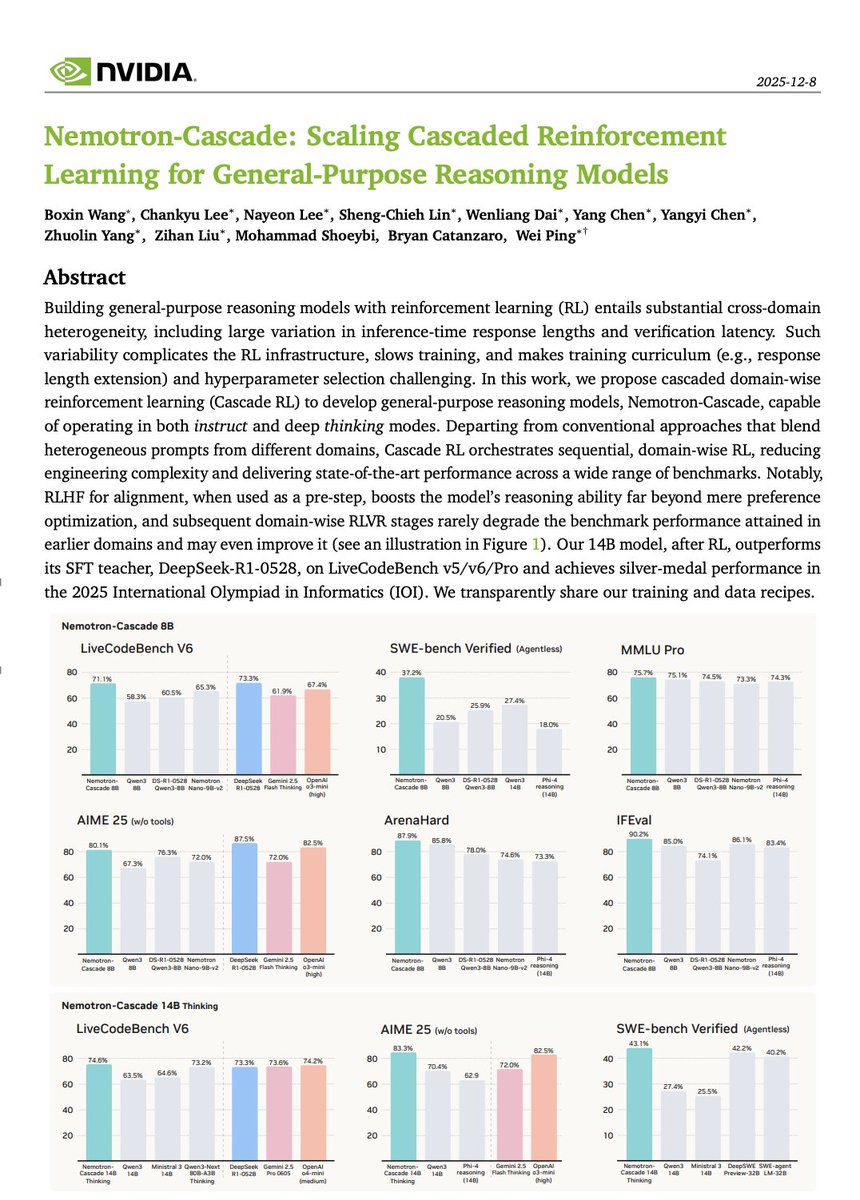
🥈 Silver Medal at IOI 2025 & Outperforms DeepSeek-R1-0528 on LiveCodeBench.
Instead of mixing different tasks together, we scale *Cascade RL* to develop general LLMs in curriculum (RLFH -> Instruct -> Math -> Code -> SWE).
So many learnings, check out our report!👇
🚀 Incredible work on AceReason-Nemotron-1.1! Huge gains in math (📈53.6 → 64.8%) & code (📈51.8 → 57.2%) benchmarks.
Key insight: scaling # of responses per prompt in SFT is a game-changer.
And the best part? Data is open-source!
📄 A must-read for reasoning model researchers.
📢We conduct a systematic study to demystify the synergy between SFT and RL for reasoning models.
The result? We trained a 7B model - AceReason-Nemotron-1.1, significantly improved from version 1.0 on math and coding benchmarks.
✅AIME2025 (math): 53.6% -> 64.8%
✅LiveCodeBench v5 (code): 51.8% -> 57.2%
Lots of interesting findings in the paper!
The 4M SFT data and RL data are open-source! 😊
Here’s the lesson we learned 🧵
➡️First, we scaled up SFT. But how?
1. "So I Just add more SFT prompts?"
❌No! We tried 7 versions of data and found an often overlooked secret - scaling the # responses per prompt is super effective and we see a large jump in performance.
2. "Do I SFT for 2 epochs to avoid overfitting?"
Don't stop training! Do it 5 epochs and the model keeps improving.
➡️Now with a strong SFT model, we applied our stage-wise RL recipe. This is where the magic happens.
3. "Does a stronger SFT model lead to a better RL model?"
Yes. A better starting point gives a better finish!
BUT here's the power of RL: it significantly closes the gap between different SFT models (from 6% to 1.6% on AIME24).🤯
4. "When the response is too long, what's better: penalize it or ignore it?"
For 8K, ignore it so the model does not confuse.
For 24K, penalize it so the model learns to reason more efficiently.
5. "Does RL still boost pass@k with a strong SFT model?"
YES! it consistently outperforms the SFT parent across pass@1 to 128 - meaning the model solved problem it couldn't previously