We’re thrilled to announce the Antigravity CLI, a lightweight way to spin up the same Antigravity agents right from the terminal. 💻
It gives you the exact same harness and same models, with a product experience tailored for the command line. It adapts entirely to you: your keybindings, your themes, your workflows.
Full Antigravity CLI Walkthrough:
This Stanford University paper just broke my brain.
They just built an AI agent framework that evolves from zero data no human labels, no curated tasks, no demonstrations and it somehow gets better than every existing self-play method.
It’s called Agent0: Unleashing Self-Evolving Agents from Zero Data via Tool-Integrated Reasoning
And it’s insane what they pulled off.
Every “self-improving” agent you’ve seen so far has the same fatal flaw:
they can only generate tasks slightly harder than what they already know.
So they plateau. Immediately.
Agent0 breaks that ceiling.
Here’s the twist:
They spawn two agents from the same base LLM and make them compete.
• Curriculum Agent - generates harder and harder tasks
• Executor Agent - tries to solve them using reasoning + tools
Whenever the executor gets better, the curriculum agent is forced to raise the difficulty.
Whenever the tasks get harder, the executor is forced to evolve.
This creates a closed-loop, self-reinforcing curriculum spiral and it all happens from scratch, no data, no humans, nothing.
Just two agents pushing each other into higher intelligence.
And then they add the cheat code:
A full Python tool interpreter inside the loop.
The executor learns to reason through problems with code.
The curriculum agent learns to create tasks that require tool use.
So both agents keep escalating.
The results?
→ +18% gain in math reasoning
→ +24% gain in general reasoning
→ Beats R-Zero, SPIRAL, Absolute Zero, even frameworks using external proprietary APIs
→ All from zero data, just self-evolving cycles
They even show the difficulty curve rising across iterations:
tasks start as basic geometry and end at constraint satisfaction, combinatorics, logic puzzles, and multi-step tool-reliant problems.
This is the closest thing we’ve seen to autonomous cognitive growth in LLMs.
Agent0 isn’t just “better RL.”
It’s a blueprint for agents that bootstrap their own intelligence.
The agent era just got unlocked.
@karrisaarinen To diminish the worth of the third largest economy in the world is the kind of little brother syndrome that put us here to begin with.
We need our own sovereign defense and our own sovereign digital capabilities.
We achieve this by investing in and building for us, not US.
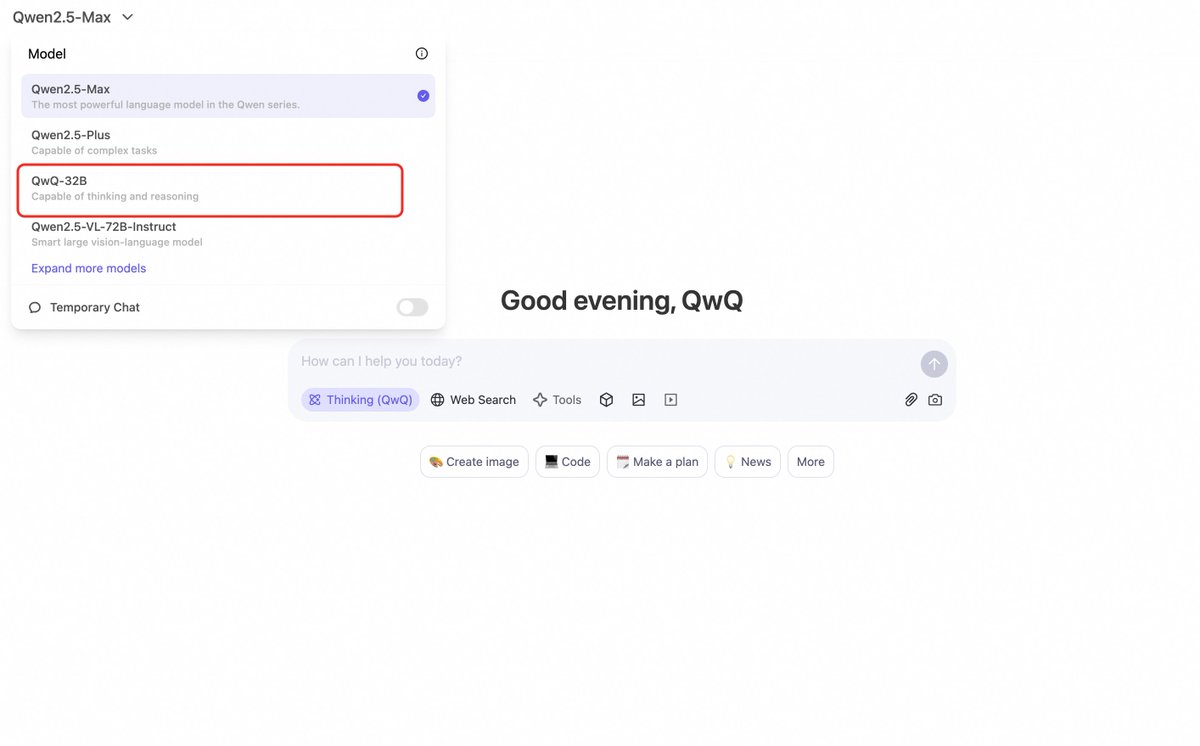
🥝 Yesterday we opensourced QwQ-32B, and we put the model on Qwen2.5-Plus + Thinking in Qwen Chat. Based on your feedback, we make a change and put QwQ-32B on the model list of Qwen Chat, and thus you can directly access it by choosing this model. Enjoy and feel free to give us more feedback about the model as well as the product! 💗
Today, we release QwQ-32B, our new reasoning model with only 32 billion parameters that rivals cutting-edge reasoning model, e.g., DeepSeek-R1.
Blog: https://t.co/jpNEx0Ck8p
HF: https://t.co/h91przQmoP
ModelScope: https://t.co/p0ztmZpWIZ
Demo: https://t.co/sxVVRFwunC
Qwen Chat: https://t.co/bg4tAU1p74
This time, we investigate recipes for scaling RL and have achieved some impressive results based on our Qwen2.5-32B. We find that RL training con continuously improve the performance especially in math and coding, and we observe that the continous scaling of RL can help a medium-size model achieve competitieve performance against gigantic MoE model. Feel free to chat with our new models and provide us feedback!
"A prompt, in its most beautiful form, should transcend time, being able to guide through direction instead of control, enabling handling of any unknown capabilities that tomorrow’s AI will bring." -Iggy Gullstrand
@elonmusk Can we also talk about Sweden having a total of 121 incidents of lethal violence during the whole year of 2023? The same number in the USA would be around 20 000.
Maybe MAGA before stones.
//Iggy
Merry Christmas from OpenAI:
Reasoning and Agentic Approach is getting stronger and stronger results. Looking forward to see the uses and public response to the new iterations!
https://t.co/7MVqbGtTKl
AI Agents is the name of our Game. Love to see that the rest of the world is catching up! Lovely discussion about the market that we are embarking to. https://t.co/ilGlAA6Gwz
Atomic Agents is key for precision when you are writing complex AI-implementation.
Tune in and read this article by our CEO Iggy Gullstrand where he digs into the realizations that lead to the Triform setup of Atomic Agents: https://t.co/moASpfS0LY
We have been invited to speak at SRE-Days in Netherlandson the 21st of November. After 4,000 km drive followed by WebSummit, Iggy is now in the rolling office preparing to speak on the topic "Build, Scale, and Secure Faster, more Personalized AI Agents".