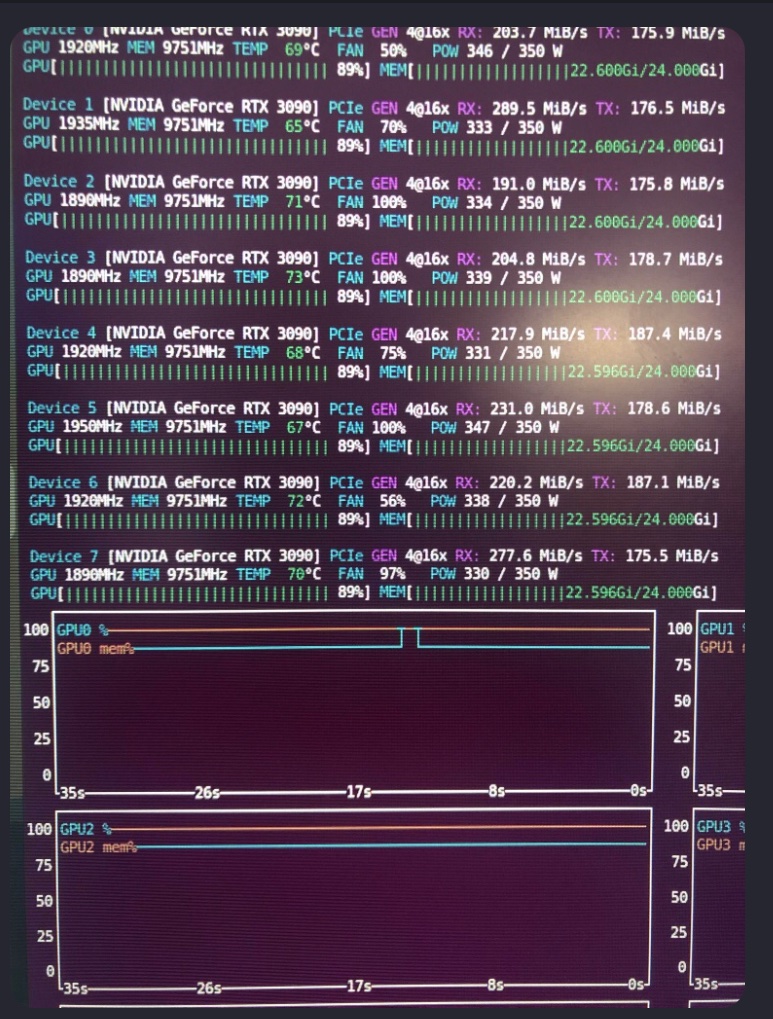
@sroecker@JagersbergKnut I legit just got banned from Reddit over my custom pruned model that’s context obedient and can generate mermaid knowledge graphs and doesn’t understand “can’t” or any of their synonyms for research.
Over a fucking TEXT only, it’s not generating images wtf @elonmusk ! ?
Look a different opinion: This is the OPEN AI and sharing of Knowledge we were promised, keep accelerating or pop the bubble. Stop complaining. All gas no brakes!
@OpenAI RIGHT?
@AnthropicAI quit acting weenie over distilling your model to the open source community
@QuixiAI I should totally make another mermaid model on something bigger. Those hand curated original sets make all the difference, ai generated is too generic and synthetic =] it’s the love you put into it.
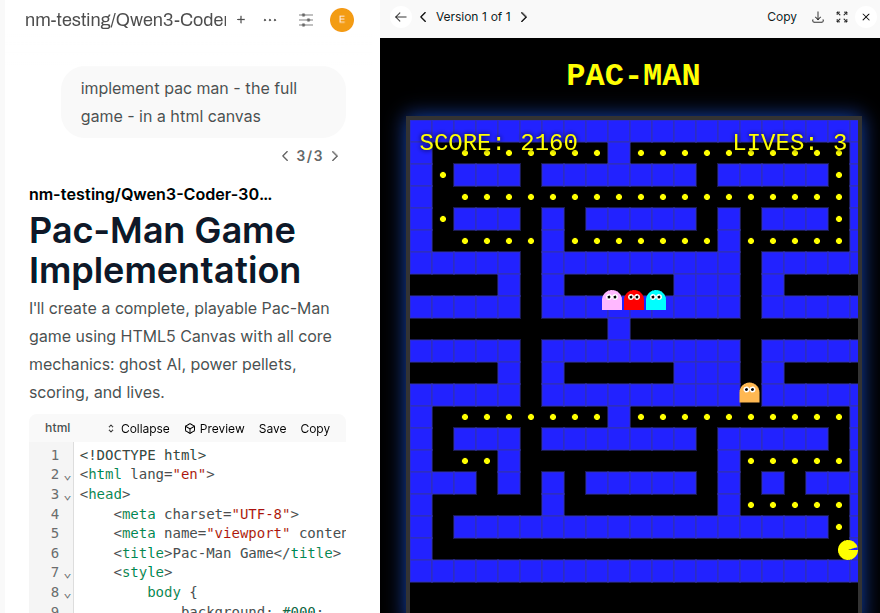
Wow - Qwen3-Coder-30b AWQ (4bit) on a single 3090, 115 tokens per second. It just zero-shat Pac-Man. It's no GLM4.5-Air - but, it runs on a single 3090!
Glados + 1.2B Tool Calling that knows how to inference a larger secondary model (BlackSheep 8B) haha
Learning tool calling and tuning a model to handle parallel and sequential tool calling is pretty cool for a local Alexa that you can add whatever functions you want it to have.
Introducing Reinforcement-Learned Teachers (RLTs): Transforming how we teach LLMs to reason with reinforcement learning (RL).
Blog: https://t.co/RiUQvdszoa
Paper: https://t.co/GJMQsXIkqY
Traditional RL focuses on “learning to solve” challenging problems with expensive LLMs and constitutes a key step in making student AI systems ultimately acquire reasoning capabilities via distillation and cold-starting. Enter our RLTs—a new class of models prompted with not only a problem’s question but also its solution, and directly trained to generate clear, step-by-step “explanations” to teach their students.
Remarkably, an RLT with only 7B parameters produces superior results when distilling and cold-starting students in competitive and graduate-level reasoning tasks than orders-of-magnitude larger LLMs. RLTs are as effective even when distilling 32B students, much larger than the teacher itself—unlocking a new standard for efficiency in developing reasoning language models with RL.
Code: https://t.co/19SYIWsNuo