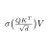Your Hermes Agent can now delegate to RLMs 🙌 Recreated the document analyzer example with the converted skill. 136 PDF pages analyzed. Best part: Auto-configures from HERMES_MODEL / HERMES_PROVIDER env vars @NousResearch@Teknium
https://t.co/ReL1NqwlCQ
Open-weight models have overtaken closed models on OpenRouter.
69.1% of token volume now goes to open-weight models. 30.9% to closed.
Competition is a discovery procedure — and developers are discovering the value of open models.
🧵
Speculators v0.5.0 just dropped with 3 big updates:
- DFlash training support. Draft all tokens in one pass via block diffusion
- Unified online/offline training powered by @vllm_project's hidden states extraction system
- Docs & tutorials overhaul for faster onboarding
https://t.co/tCMZIrgQf2
Project Lightwell is a $5 billion investment that marks a fundamental shift in how we think about our role as open source stewards. I believe it will define the next chapter of Red Hat's engineering mission. We are applying the same discipline, upstream-always commitment, and engineering rigor across all active application layers that modern enterprise environments depend on.
EAGLE 3.1 is out. The team identified attention drift as the root cause of acceptance-length degradation at deeper speculation steps.
Fix: FC normalization + post-norm hidden-state feedback. Result: 2x longer acceptance length in long-context workloads, 2.03x per-user throughput on Kimi K2.6.
Already in @vllm_project nightly. Native support lands in the next release v0.22.0. Open source draft model available now.
🚀 Organizing the Efficient Qwen Competition @icmlconf !
Goal: Minimize LLM inference latency for a single GPU without breaking model quality.
Prizes: $3K / $2K / $1K + present at ICML 2026, Seoul
Getting Started - https://t.co/On1yK4fnu9
Leaderboard - https://t.co/7HUbO2oA3A
What hardware actually powers open-source AI?
Not benchmarks.
Not vendor marketing.
Real-world community usage.
We’re launching @huggingface Hardware:
→ trending GPUs & CPUs
→ VRAM distribution
→ inference hardware trends
→ what the OSS AI ecosystem really runs on
Weight-only quantization powers local LLMs like llama.cpp or Ollama. But SOTA quantized accuracy requires complex kernels that are notoriously hard to implement.
Can we get SOTA accuracy and keep things simple? Our new GSQ (Gumbel-Softmax Quantization) method says yes. 🧵
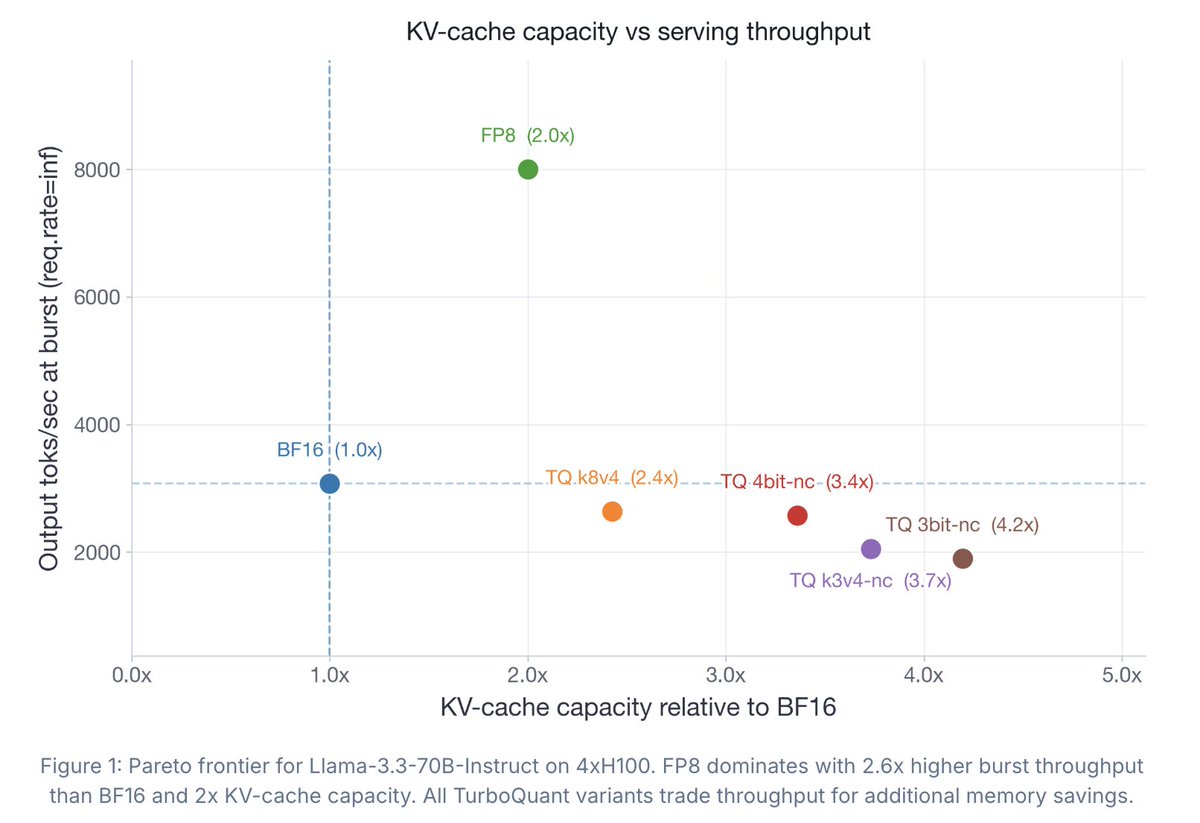
We released experimental MTP Qwen3.6 Unsloth GGUFs!
Qwen3.6 27B MTP now runs at 140 tokens/s. Qwen3.6 35B-A3B MTP gets 220 tokens/s generation on a single GPU.
Qwen3.6 27B and 35B-A3B have >1.4x speed-up over the original GGUFs without any change in accuracy.
Guide + GGUFs + Benchmarks: https://t.co/x9BYC3iXCL
In terms of average speedup, we see a 1.4x for dense models at draft tokens = 2 and for the MoE around 1.15 to 1.2x.
We do not recommend more than 2 draft tokens because the acceptance rate drops precipitously from 83% to 50% with 4 draft tokens, and the forward passes for MTP become less beneficial.
Use `--spec-type mtp --spec-draft-n-max 2`
Thanks to Aman for https://t.co/0WKkIC0kyW!
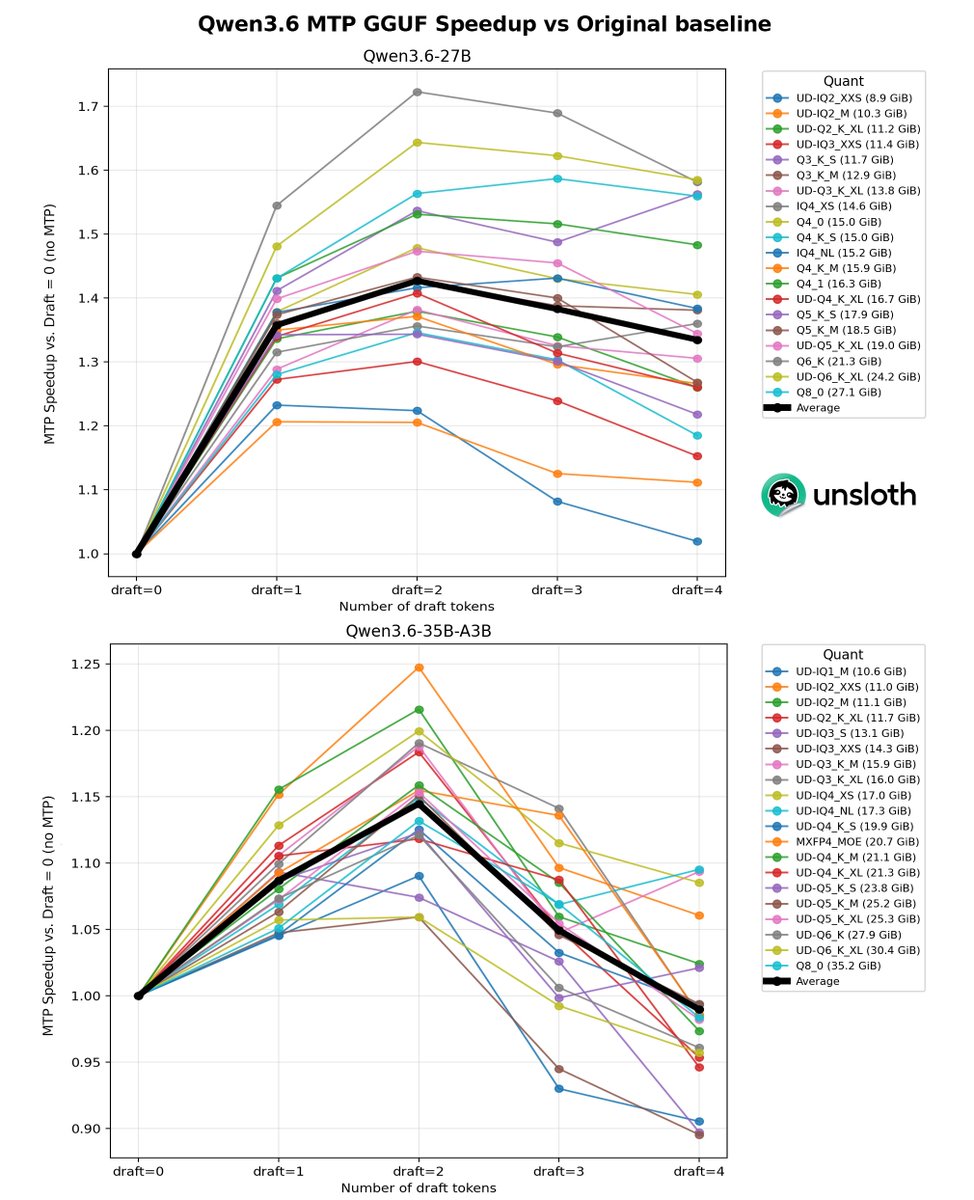
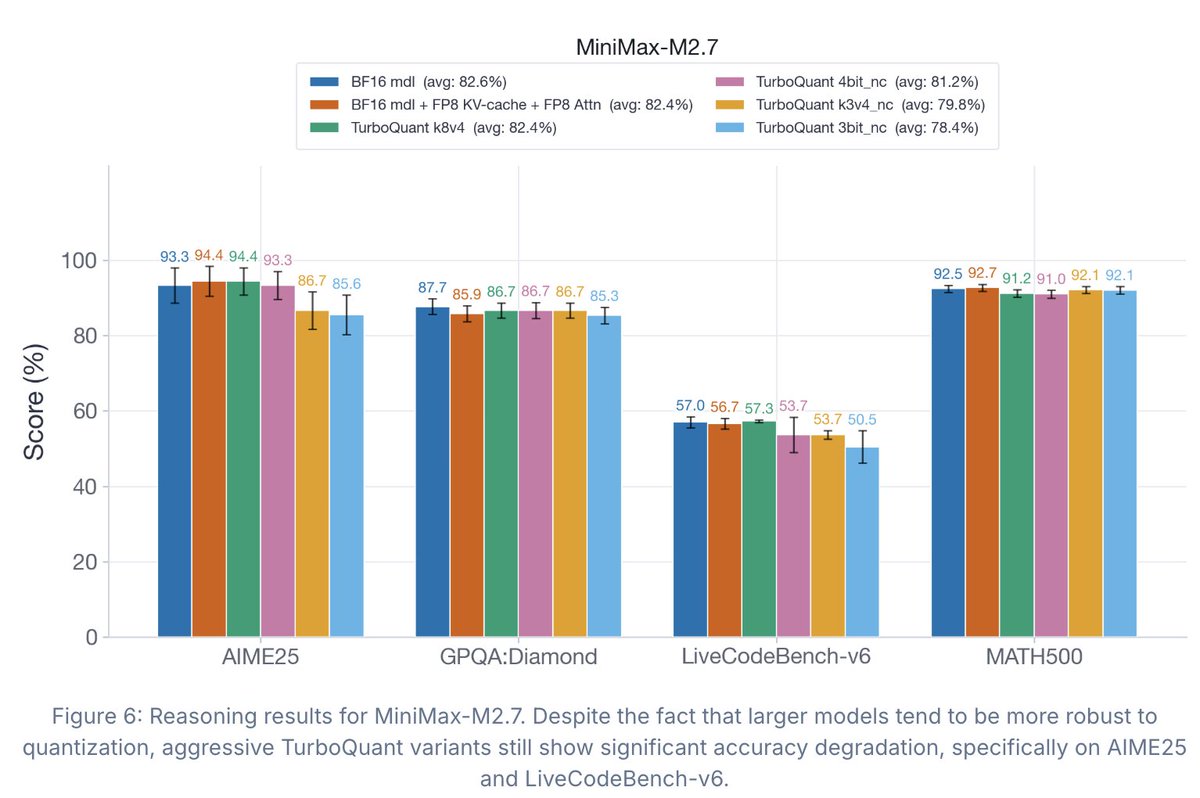
appreciate the comprehensive write-up from @_EldarKurtic, @mgoin_, @RedHat_AI on TurboQuant. data on H100 with native FP8 Tensor Cores looks right for what was tested. few things to add from the non-H100 side, where most of my testing lives:
For more details and results check the full blog at https://t.co/ncAaF5V7vF .
This is joint work with @mgoin_ and Alexandre Marques from @RedHat_AI and @vllm_project .
TurboQuant has drawn a lot of attention recently, but the accompanying evals didn't tell the full story.
So we ran what I believe is the first comprehensive study of TurboQuant: where it helps, where it falls short, and how it impacts accuracy, latency, and throughput.
Findings:
I think @antirez ds4.c is important! I wrote down my thoughts on why I built pi-ds4 and why we need to focus our local model efforts stronger than we do currently. https://t.co/61h4JDHTZL
Welcome to DS4, a specialized inference engine for DeepSeek v4 Flash. https://t.co/UrUJz5I2R1
This project would have been impossible without the existence of llama.cpp and GGML and the work of @ggerganov and all the other contributors. Thanks!
First entry to @LottoLabs localmaxxing: 28k prefill with vLLM serving Qwen 3.6 35B A3B REAP (0.5 ratio) in NVFP4 on a 5070 Ti with 16 GiB VRAM https://t.co/1zuyNZ4oZ7
Check out the model and instructions here https://t.co/wDPaCXGVF8