Today, we’re re-launching FactIQ.
Six months ago, we launched a search and visualization engine for economic data. You could ask for a dataset, find the right series, and turn it into a chart.
But over the last few months, the role of agents has changed.
They are no longer just useful for saving a few minutes on repetitive work. They now act like a tireless second pair of eyes. Digging through data, testing competing explanations, and surfacing evidence you may not have looked out for.
That opened up a much bigger opportunity for FactIQ.
Macro analysts don’t just need another way to make charts. They need to answer the hardest and most important question in research: what’s actually happening?
Answering that means looking beyond the obvious narrative. Beyond the single indicator everyone is watching. Beyond the chart that confirms what you already believed.
The new FactIQ turns a macro question into an investigation.
It breaks the question into the explanations that could be true, searches across official data, global institutions, government releases, news, and trusted industry sources, and tests which explanations are actually supported by the evidence.
The goal is simple: give every macro analyst the capabilities of an institutional research desk.
Use FactIQ to write macro notes, brief clients, support investment decisions, or pressure-test your view before publishing it.
Try it today at https://t.co/o5PXgDbnq3. We would love to know what you think.
Excited to launch FactIQ today! 🚀
We just indexed 7.4M+ official US data series to build the ultimate economic research agent.
Visualize trends instantly. Verify every source. Export charts for your reports.
Free for the next week - try it out at factiq[dot]com!
I had the opportunity to present DB-Agent, an open-source AI agent designed for intelligent database interactions, at AAAI-25! It’s simple streamlit app with @defogdata SQL model. Works great across most platforms and game changer for non tech users who don’t write SQL #AAAI25
Open-sourcing Introspect: MIT-licensed Deep-Research for your internal data!
Works with spreadsheets, databases, PDFs, and web search. Has a remarkably simple architecture – Sonnet agent armed with recursive tool calling and 3 default tools.
Best for use-cases where you want to combine insights from SQL with unstructured data + data from the web.
Launching a bunch of products built on top of of this soon, but wanted to open-source our core engine to give back to the community! 2 min demo below, links in comments
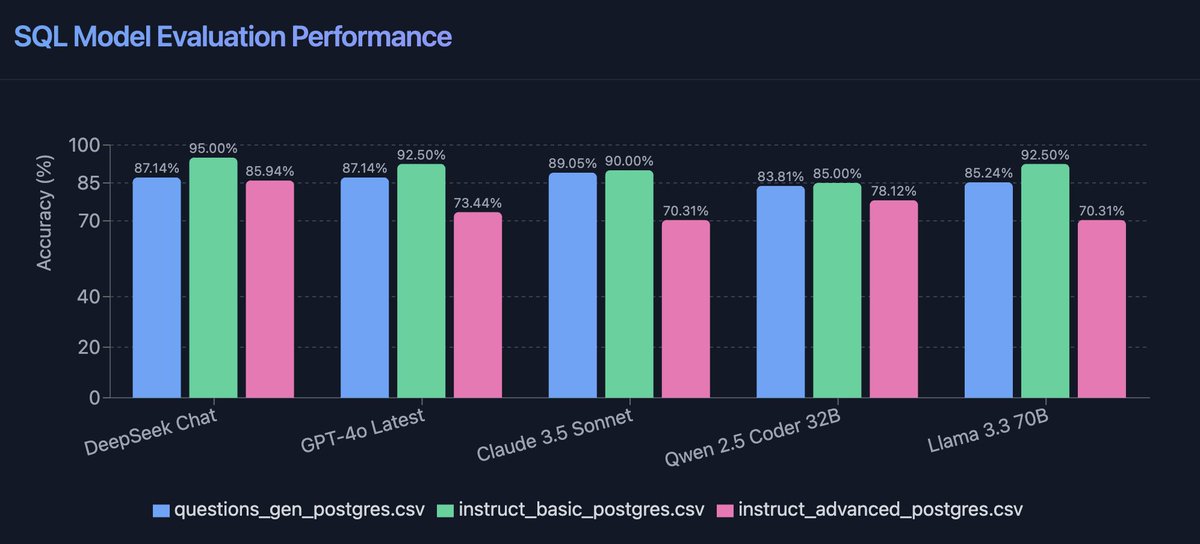
Benchmarking Open vs Closed SOTA models on Text-2-SQL via @defogdata SQL Eval using @openrouter
🐋 Deepseek V3
🟠 Sonnet 3.5
⚫ gpt4o-latest
🦦 Qwen2.5-Coder 32B
🦙 Llama-3.3 70B
We made a thing! Very happy to announce sqlcoder-pro and the Defog Alignment Platform. Available to use immediately without a wait-list, weights will be open-sourced very soon.
The video does a quick show and tell comparison against ChatGPT (with gpt-4o). Read on for more details!
TLDR
💪 equal (or better) performance on text-to-SQL as the most capable Claude-3.5 or GPT-4 models
🤝 You can use it today on a free plan/free trial, without a waitlist
🪽 self-hostable on a single RTX4090, with 2 second median generation times for SQL queries
🔁 exactly the same output every time, give the same prompt
👨🏻🏫 teachable and steerable: show the model what you want it to do
🛞 debuggable – you can understand WTF is going on inside the model, instead of treating it like a black box
Let's dig into each of these one-by-one!
Performance
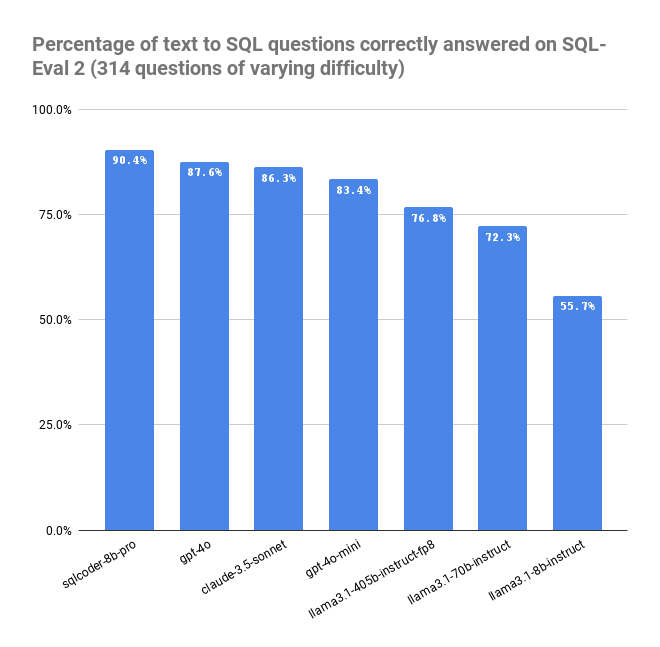
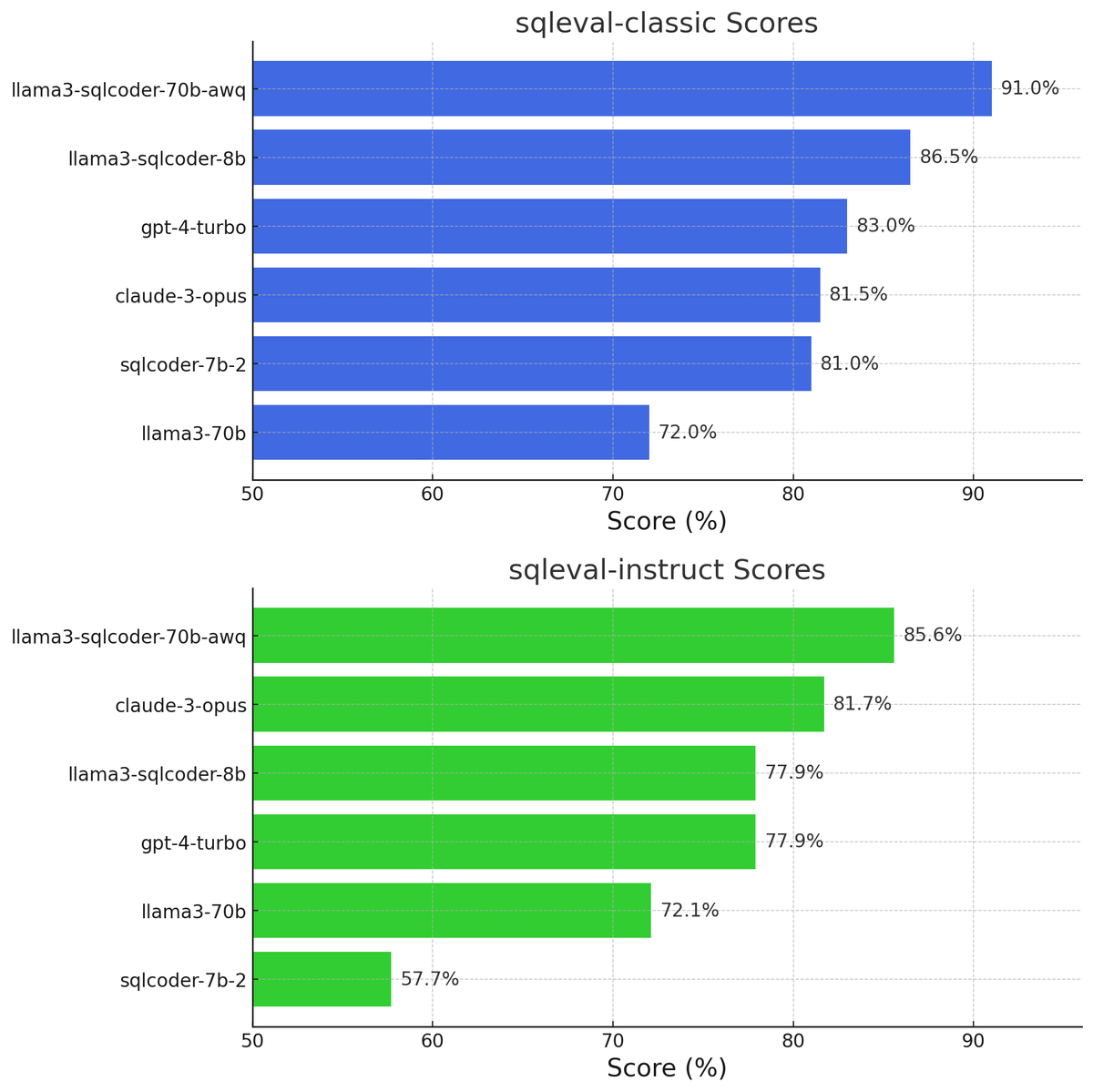
SQLCoder-8b-pro significantly exceeds the performance of our previous sqlcoder-8b model on Postgres text-to-SQL (from 88.2% to 90.2% accuracy - gpt-4o is at 87.6%, for reference). It is also better at following instructions.
This was done via self-merges, hand crafted fine-tuning data, and adapting the training data to fit our tokenizer.
Cost
You can host this on the model on a single $3,500 RTX4090, and support ~5 requests/second via VLLM.
If you're looking to host on the cloud instead, you can run it on a single L4 GPU that costs $300/mo on GCP
Repeatability
We have a dense 8b model with no MoE shenanigans. For the same prompt with temperature=0, you'll always get the same answer – which is critical in BI.
Teachable
In our alignment and feedback modes, you can give the model feedback on how it answered certain questions, and it will automatically adapt to the feedback.
Debuggable
You can use logprobs and attention scores to determine where, exactly is the model paying attention to inside a prompt + what it's getting confused by when generating outputs.
Available today
You can use Defog on the cloud today by going to docs[dot]defog[dot]ai, and getting an API key.
Excited to hear what you think!
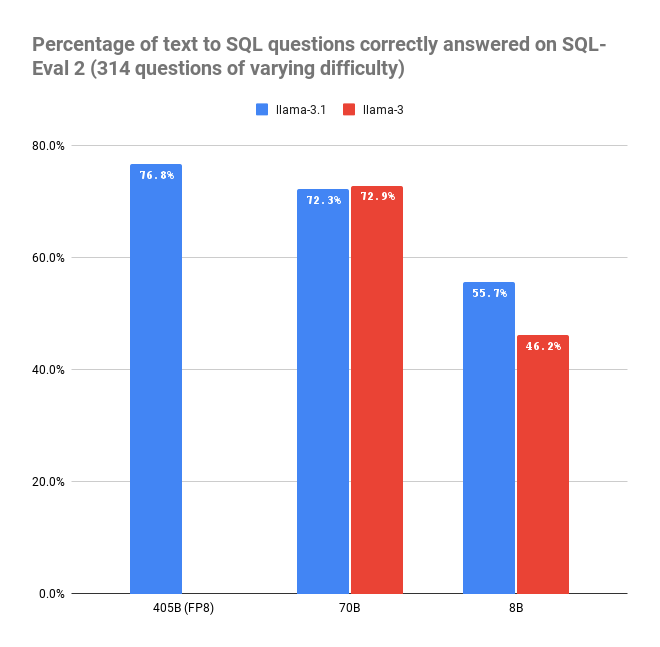
Just finished running evals for Postgres text-to-SQL on the new Llama 3 models
TLDR
- Unfinetuned llama models not (yet) as good as OpenAI and Claude models, but will easily outperform with finetuning on domain specific tasks
- Llama 3.1 8B is faaaar better than the Llama 3 8b
Performance on SQL Eval 2
We have hand-crafted 314 questions (many of which are fairly difficult) for deterministic text to SQL evaluations. If the model generates a SQL query, we actually execute it against a database to check its performance.
OpenAI and Anthropic's latest models are really good at text to SQL. Unfinetuned Llama3.1-405b-instruct models often got almost there, but fell short at the last mile. I tried a bunch of prompts (including CoT prompts), and results were +-1% of each other
If you'd like, you can run the evals yourself at https://t.co/n0CxuKqREN. I ran them on an 8xH100 from runpod, and it probably took ~$20 or so to run all the evals!
The promise of fine tuning
Our 8b Llama-3 finetune performed on-par with or better than the OpenAI models for text to SQL (yes, we did make sure to prevent data contamination :P). We've been working on this finetune for 3 months and will release a version of it soon.
For codegen, understanding Llama's tokenizer was critical for best performance. For the last 3 months, most of the my time was spent starting at attention scores + logprobs, using them to find gaps in training data viz-a-viz the Llama tokenizer, then updating training data and starting training runs again.
The jump up from Llama3 to 3.1
We saw a big jump in capabilities from Llama-3-8B to 3.1, though didn't see as big of an increase for the 70B variant.
I'll get a few more finetuning runs on the 3.1 variant up, and will see if 3.1 finetunes outperform 3 finetunes significantly.
Defog AI Introduces LLama-3-based SQLCoder-8B: A State-of-the-Art AI Model for Generating SQL Queries from Natural Language
Defog introduced LLama-3-based SQLCoder-8B, a state-of-the-art model for generating SQL queries from natural language. This new model stands out by addressing the limitations of prior systems. Traditional models often buckle under the pressure of complex, instruction-heavy queries or fail to adapt to the nuances presented by different database frameworks. SQLCoder-8B revolutionizes this landscape by integrating a broader spectrum of training data encompassing various instructions and more challenging SQL generation tasks.
SQLCoder-8B distinguishes itself through a refined methodology that significantly enhances its capability to process and follow intricate instructions, leading to highly accurate SQL outputs. The model has been rigorously trained on a dataset enriched with diverse SQL query scenarios. This training is designed to equip the model with the versatility to tackle real-world applications, ranging from simple direct queries to complex, multi-step SQL instructions.
Quick read: https://t.co/v0ILuQR2W1
Model: https://t.co/ZFkd43vY1I
Demo: https://t.co/JOtSxUiWFL
@defogdata #ai #DataScientist #sql
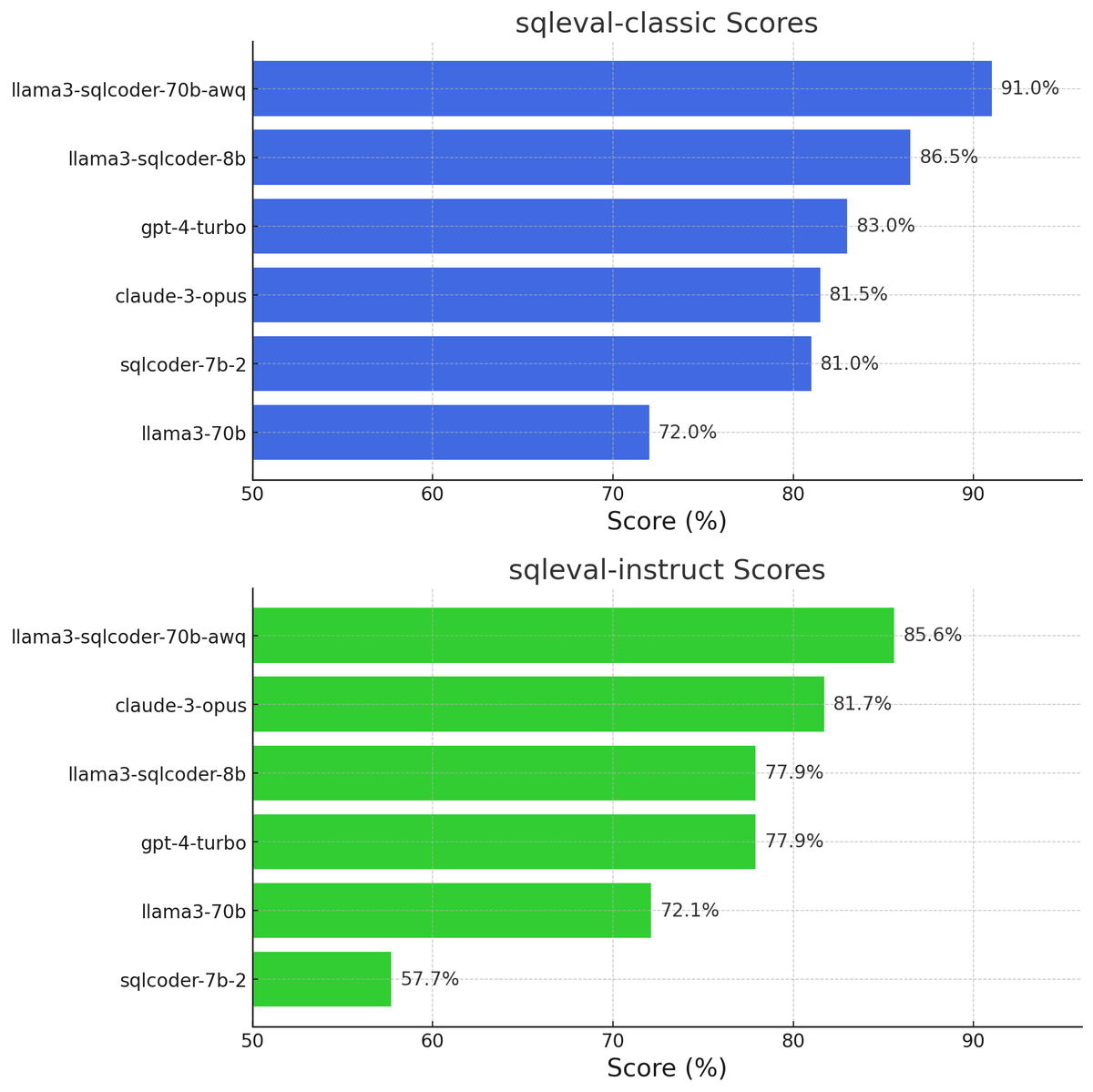
Llama-3 based SQLCoder 8b is out! Open weights with a commercially friendly cc-by-sa license. Probably the best <10B param model for Postgres text to SQL right now.
Slightly better than gpt-4-turbo and claude opus for 0-shot text to SQL generation. Also approaches their performance when following instructions.
Weights on @huggingface: https://t.co/lg0A2f4tqc
Demo (optimized for postgres): https://t.co/qp4zvZ52xV
More technical details below!
What's new about this model
Our previous small model (sqlcoder-7b-2) was good at generating 0-shot SQL, but did terribly at following instructions. So while it was great in our evals, it was lacking in real-world use-cases where instruction following is much more important.
To address this, we trained this model with much more instruction data. We also made our original eval much harder to make sure we stayed on the right track.
Changes to evals
There were 3 changes to our original eval:
1. Previously, we pruned the database schema to only consider the 20 relevant columns in the DDL statements. We have now removed pruning that so that all columns in a database are used
2. We previously used beam search with 4 beams to make our results more accurate. But with a large number of input and/or output tokens, that increased memory requirements and became computationally intractable. So we have shifted to a single beam now.
3. We added 104 complex instruction-following text=> SQL questions questions to our evals, in addition to the 200 0-shot questions that were already there.
Link to our eval framework here: https://t.co/n0CxuKqjPf
Changes to prompt
You previously had to use our slightly idiosyncratic prompt for best results. Now, you can just use the standard Llama-3 instruct prompt.
70B model, technical report, and more up next
We've also been training a llama-3 based 70B model right now. It's still training and will get better over time – but even an AWQ quantized version of our interim model is giving excellent results for now. We hope to open-source the 70B next week.
We also have a technical report coming up next week (or over the weekend, if I can be productive enough on a flight) about the training methods used for this model. More on that soon!
Feedback very much appreciated!
In the meantime, please send us your feedback as you try out the model - specially if you see failure modes. Would very much appreciate it!
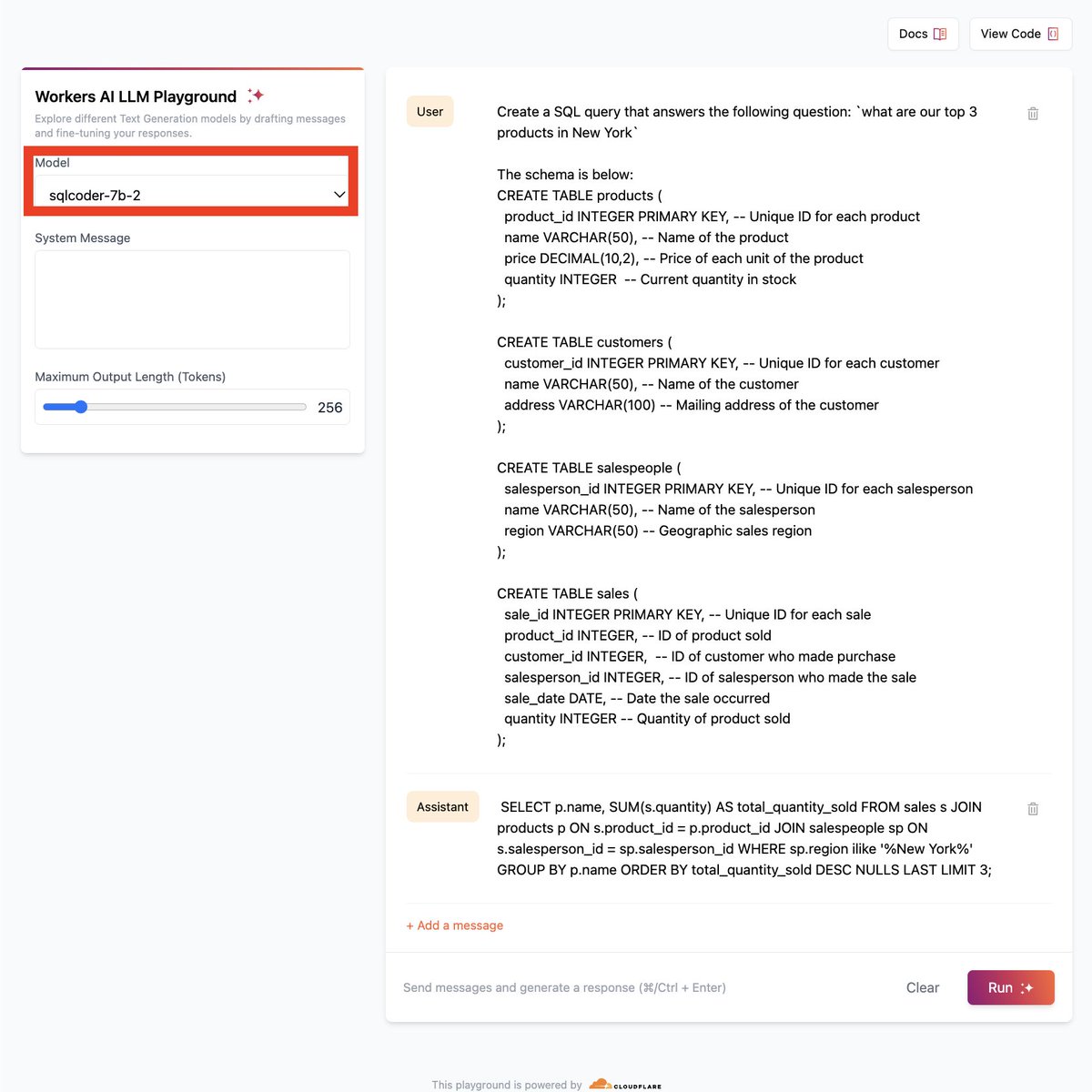
Cloudflare's new AI announcements look fun! Check out sqlcoder-7b-2 on their playground :D https://t.co/HYkXIcls8r
Unfortunately allows only for chat-styled inference right now (which we are not optimized for) – but still outperforms other models for text to SQL tasks!
Pretty cool to see this on HF trending today :D
Also, building some fun MLX integrations, thanks to @Ubunta's awesome MLX port. Already a part of sql-eval in this PR: https://t.co/axhUzur7gM
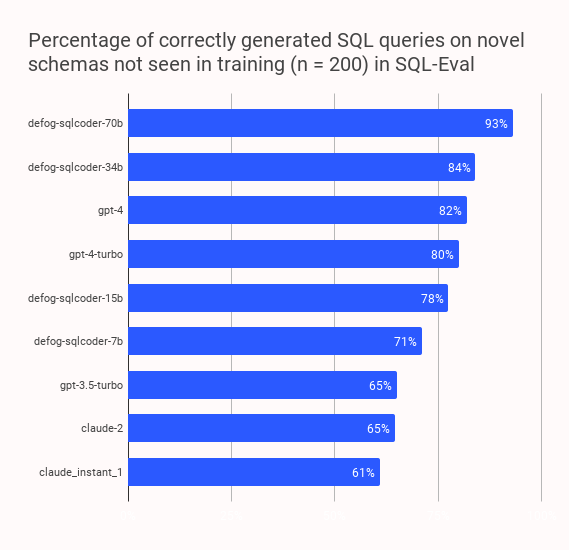
And here it is! SQLCoder-70B outperforms all other models in the market for Postgres text-to-SQL generation by a wide margin.
We got these results by fine-tuning @AIatMeta CodeLlama-70B, which was released yesterday, on less than 20,000 hand-curated prompt-completion pairs.
You can find SQLCoder-70B on @huggingface
at https://t.co/fPmIrYaLAv This follows our 15B, 7B, and 34B models – and is the most capable of them all.
The model has a CC BY-SA 4.0 license, which means that you are free to use it as is for any use (including commercial) as long as you also open-source any changes you make to it (eg, if you fine-tune it further).
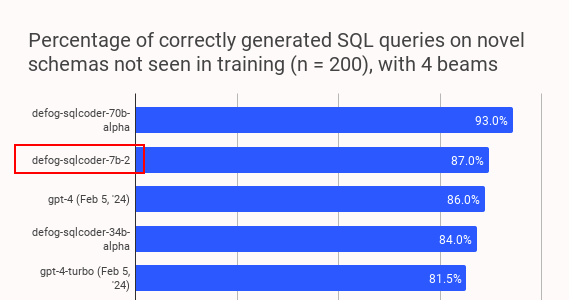
Just reproduce SQLCoder-7b-2 (fp16) from @defog with a beam_size of 1. It achieved around 87%, as mentioned by @rishdotblog earlier.
So, how about AWQ and int8 KVcache?
Let's guess. 🧐
You can now run SQLCoder with a GUI on Apple Silicon or any NVIDIA GPU-enabled device! On Apple Silicon, just run
CMAKE_ARGS="-DLLAMA_METAL=on" pip install "sqlcoder[llama-cpp]"
sqlcoder launch
The Apple Silicon version is not super accurate, but works great for simple questions – and everything happens (fairly fast) on just your laptop!
We will add support for more platforms soon. PRs are very welcome!
Github: https://t.co/zgMT0C1IeS
Two big updates today!
We updated the weights for sqlcoder-7b-2, and it now outperforms GPT-4 for most SQL queries – specially if you give it the right instructions and prompt well
@huggingface link here: https://t.co/8TeOBdu5Rf
2) We've added basic instruction following capabilities, including the ability to say "I don't know" when a question cannot be confidently answered given a database schema. More on that here! https://t.co/v3w8lwqUsr
3) We've got a Colab notebook up if you want to explore the model (though just with a single beam, for now): https://t.co/KkHuhR4Pir
@Jay____wang @_philschmid@OpenAI@AIatMeta We agree! The evaluation is independent of the LLM, and is done using the open-source SQL-eval framework https://t.co/PWUAEVV4xI
Use big models to specialize small models! Thats the way. 💫 🚀
7B Text-to-SQL model outperforms @OpenAI GPT-4 (Turbo)! @defogdata released a new fine-tuned @AIatMeta Code Llama 7B model outperforming the latest GPT-4 & GPT-4 Turbo Models!
The team boosted the 7B performance by leveraging distillation from a fine-tuned 70B Code LLama model! 👨🏫
Models can be commercially used (CC-by-SA-4.0) and are available on @huggingface
👉 https://t.co/O0zglaYd4t
@rishdotblog mentioned they are now pushing for improved performance on joins and group-bys! 🤌🏻 Big Shoutout to Defog for pushing open Code Models! 🧑🏻💻