I get a lot of questions about why Kubernetes isn’t the right foundation for sandbox infrastructure.
It was built for stateless micro-services with predictable traffic patterns, and databases that run forever.
Sandboxes are different, they’re high-throughput like batch jobs and stateful like databases.
You don’t want your vibe-coding agent to install all your app’s dependencies, download code, etc. every time it starts. You want the sandbox, with the agent in it, to start immediately, with code, dependencies, agent memory preserved from the last session. Doing this with Kubernetes at scale is hard, and even with a lot of hacks it would be working around warm pools.
🎉 We're thrilled to announce: .@KubeDB is now an official Red Hat .@OpenShift Certified Operator!
This is a huge milestone for our team at AppsCode — and an even bigger win for OpenShift users who've been looking for a better way to run databases on Kubernetes.
No more cloud lock-in. No more DIY overhead. Just a validated, Kubernetes-native DBaaS platform that works consistently across on-prem, cloud, ROSA, ARO, and air-gapped environments.
Self-service for developers. Governance for platform teams. Any database, one control plane. 🚀
✍️ Read the full story on the AppsCode Blog: https://t.co/wHvQTvDZ6s
📄 Joint Solution Brief: https://t.co/DrmZwIRcAD
🔗 Red Hat Ecosystem Catalog: https://t.co/1S0r9HmMrN
#KubeDB #RedHat #OpenShift #Kubernetes #DBaaS #CloudNative #KubernetesStorage #PlatformEngineering #AppsCode #RedHatSummit #RHSummit #Atlanta2026 #BetterTogether #Innovation #Database #TechCommunity
🚀 Excited to announce our partnership with .@SUSE!
SUSE Rancher Prime + .@KubeDB now delivers a true Kubernetes-native DBaaS — anywhere Kubernetes runs.
✅ No cloud lock-in
✅ Full data sovereignty (on-prem, hybrid, multi-cloud, edge, air-gapped)
✅ Automated provisioning, scaling, HA, backup & recovery
✅ Enterprise governance and self-service for developers
Platform teams finally get consistent, governed database operations with complete control.
Read the full story on the SUSE Blog:
https://t.co/QuxUz7qiQG
👉 Download the joint solution flyer:
https://t.co/GWmow4XudG
#KubeDB #SUSE #RancherPrime #DBaaS #Kubernetes #DataSovereignty
🚨 Argo CD users have a serious problem.
- Low-privilege users could read Kubernetes resources outside their app scope
- ServerSideDiff=true made it worse
- Plaintext Secrets could be exposed with zero redaction
Affected:
- 3.2 < v3.2.11
- 3.3 < v3.3.9
Fix:
> Upgrade now
> Disable ServerSideDiff=true
> Tighten RBAC
> Rotate Secrets if enabled
This one is bad.
https://t.co/KkF9IJx35v
It always blows my mind that #Kubernetes CSI drivers need 8 different sidecars. 🤯 I can never decide if this is absolutely genius (SRP) or just hacky. https://t.co/znEhhRjakc
Starting June 1st, GitHub Copilot will move to a usage-based billing model as GitHub Copilot supports more agentic and advanced workflows.
In early May, you'll see a preview bill experience, giving visibility into projected costs before the transition.
👉 Read more about the upcoming change: https://t.co/4IC9VNHwhk
When this news broke I really wanted to understand how the linux scheduler work. So I started to research.
What I gathered so far: (of course I might be missing something)
Unlike user code, the Linux kernel code isn’t usually preemptable. That is when a system call is executed or a page fault is triggered the kernel runs to completion hogging the cpu core it runs on.
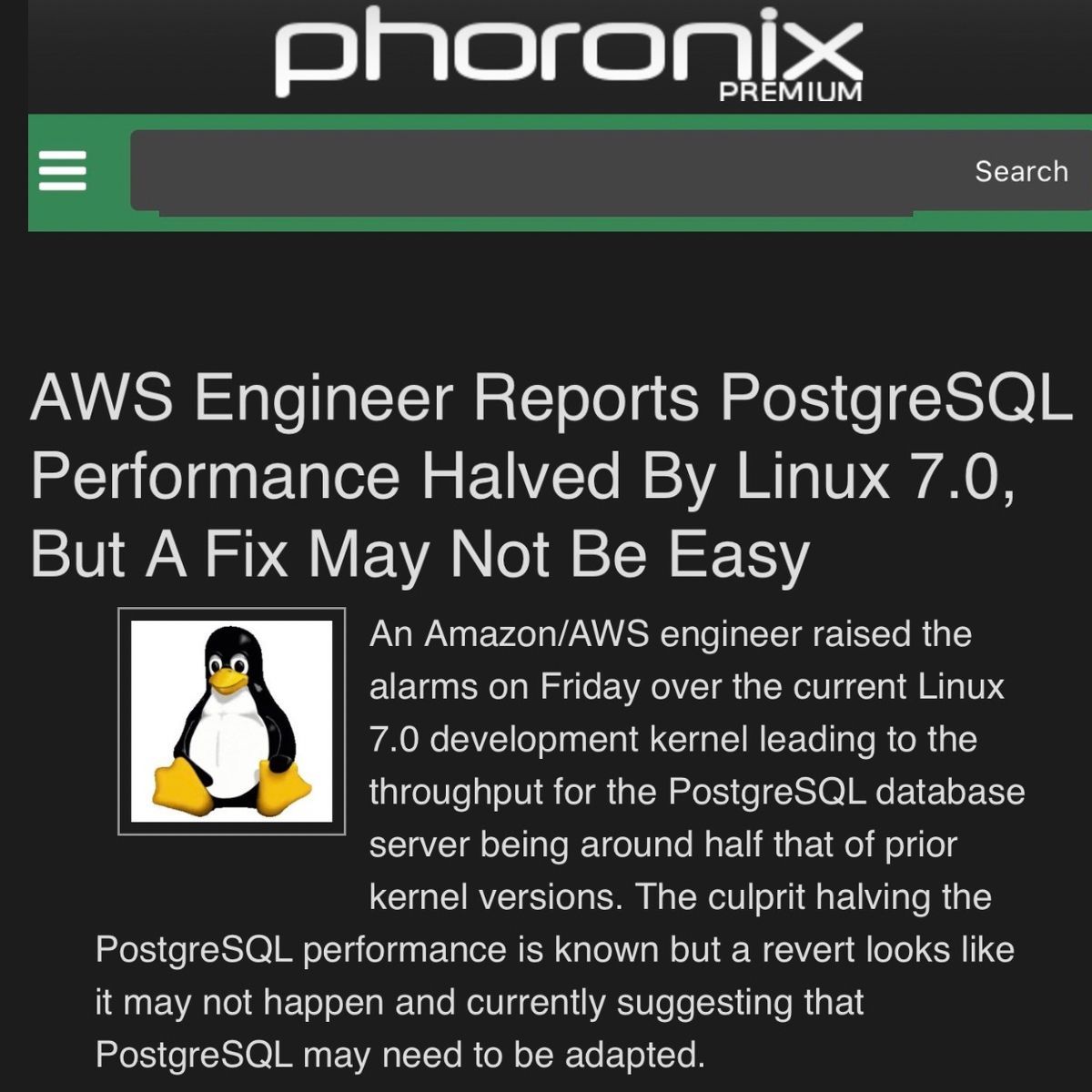
The current Linux 7 tip experimenting a different preemption model for kernel code, so other more critical tasks can be scheduled. With this default mode, Postgres experienced 50% dropped in performance in one test suite 96 cores, with 100GB shared buffers pool.
The theory from the thread discussion is that the large buffer pool 100 GB with the default 4kb kernel vm page size, caused significant number of page faults. Page faults gets triggered to allocate physical memory on first access or on swap (I have a video detailing this).
Page fault runs kernel code to do the allocation of the physical memory and update the page table data structure for the process. If page faults are being preempted, it keeps the user process code in spin lock waiting for access.
Indeed Andreas, the postgres maintainer, was able to prove that even with stable Linux you could see the contention obtaining memory from shared buffers, its just not as obvious with 7.0 where kernel preemption is enabled
Using huge pages significantly reduces page faults, improving the performance.
My Page Faults The Backend Engineering Show
https://t.co/QtcIL4nsZi
Phoronix article
https://t.co/hXMzz0KOi0
Upgraded .@claudeai from $20 to $200 plan on Friday. Today I left my laptop on with some online research. Came back 5 hours later with an email saying the account is suspended. WTF!