India enters the open-weights AI race with its largest models pre-trained from scratch: Sarvam 105B and Sarvam 30B
@SarvamAI's Sarvam 105B and Sarvam 30B score 18 and 12 on the Artificial Analysis Intelligence Index respectively. Announced at the India AI Impact Summit 2026 and open-sourced under Apache 2.0, both are Mixture-of-Experts models trained entirely in India using compute provided under the IndiaAI Mission (@OfficialINDIAai). Both support reasoning and non-reasoning modes.
These are an improvement from Sarvam's previous model, Sarvam M (8 on Intelligence Index, 23.6B parameters), which was based on Mistral Small rather than pre-trained from scratch. Sarvam 105B has 106B total parameters with ~10B active per token and a 128K context window. Sarvam 30B has 32B total parameters with ~2.4B active per token and a 65K context window. Alongside the text models, Sarvam also announced Saaras v3 (Speech to Text) and Bulbul v3 (Text to Speech) with a focus on Indic languages.
Key takeaways in reasoning mode:
➤ Sarvam 105B scores 18 on the Intelligence Index. Among ~100B-class open-weights reasoning models, it trails GLM-4.5-Air (23), INTELLECT-3 (22), Mistral Small 4 (27), and gpt-oss-120B (High, 33). All four peers also activate more parameters per token
➤ Sarvam 30B scores 12 on the Intelligence Index. Among ~30B-class open-weights reasoning models, it trails GLM-4.7-Flash (30), Nemotron Cascade 2 30B A3B (28), Qwen3 30B A3B 2507 (22), and Qwen3 32B (17). Sarvam 30B activates fewer parameters than these peers.
➤ Sarvam 105B's relative strength is in select agentic tasks. Its agentic index of 25 places it ahead of INTELLECT-3 (20) and GLM-4.5-Air (21) despite trailing both on overall intelligence. Its GDPval index of 773 also edges ahead of GLM-4.5-Air (665). Both new models are a large step up from Sarvam M (Reasoning), which scored 8 on the Intelligence Index.
➤ Compared to peers, both models score lower on TerminalBench Hard (Agentic Coding & Terminal Use) and AA-Omniscience. Sarvam 105B scored 1.5% and Sarvam 30B scored 2.3% on TerminalBench Hard, compared to GLM-4.5-Air (20.5%) and INTELLECT-3 (9.1%). The AA-Omniscience Index is -60 for Sarvam 105B and -72 for Sarvam 30B. Both models have high hallucination rates relative to their accuracy, and both attempt to answer far more questions rather than abstaining, which drives the negative scores.
Key model details:
➤ Modality: Text input and output only.
➤ Context window: 128K tokens (Sarvam 105B) and 65K tokens (Sarvam 30B).
➤ Pricing: Currently free on Sarvam's first-party API.
➤ License: Apache 2.0.
➤ Availability: Sarvam's first-party API; weights available on @huggingface and AIKosh.
A team of Japanese researchers led by Kojima Tomoki won the Ig Nobel prize for their research paper "Cows painted with zebra-like striping can avoid biting fly attack."
They had a great sense of humor about how to act at the award ceremony.
本日の10:00-12:00のIROSのポスターセッションU(7-8で展示)で共著1件(主著:@ummavi)の発表を行います。
NeRFを用いた透明物体の深度情報の再構成に焦点を当てており、Visual Foundation Modelsでセグメンテーション情報を与えることで、性能を大幅に改善して、ロボット把持を実現しています!
So here's a story of, by far, the weirdest bug I've encountered in my CS career.
Along with @maciejwolczyk we've been training a neural network that learns how to play NetHack, an old roguelike game, that looks like in the screenshot. Recenlty, something unexpected happened.
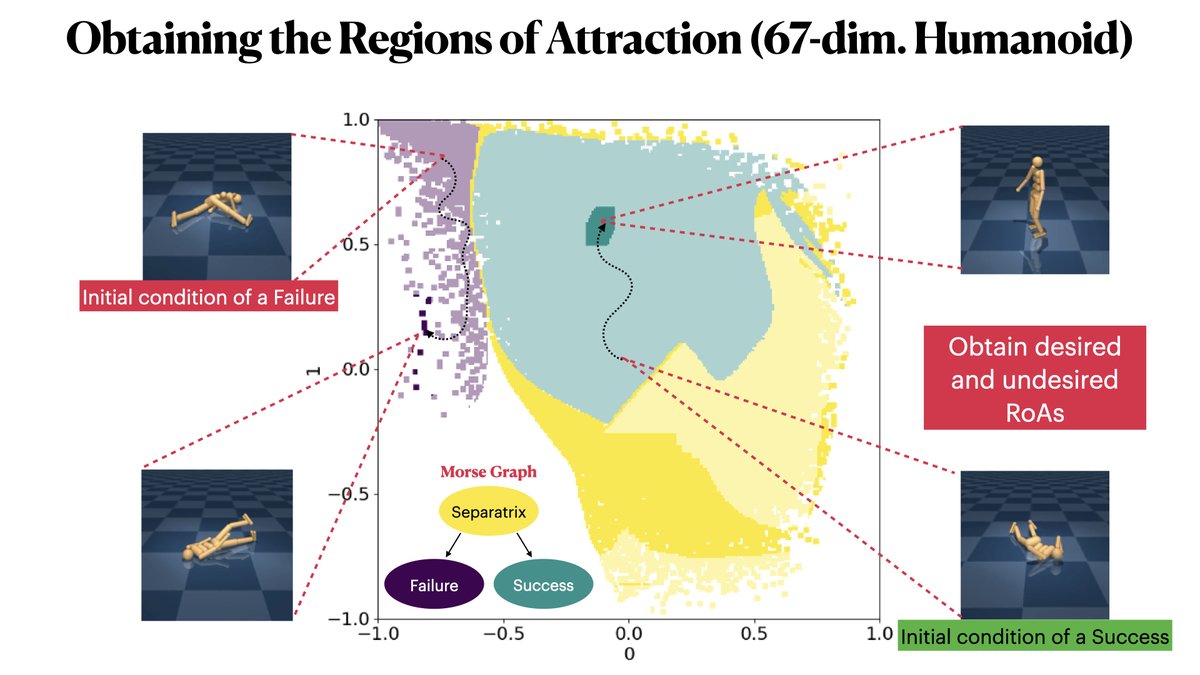
Can you know when your robot policy works without running it?
"MORALS: Analysis of High-Dimensional Robot Controllers via Topological Tools in a Latent Space" (nominated for Best Automation Paper @ieee_ras_icra), does just that! Here is all you need to know 📷 (1/n)
PFN's Robotics Research Team is looking for a Japan-based part-time engineer/researcher for R&D in object manipulation tasks using a robotic arm with several sensors.
https://t.co/9RAtNv0Y6T
We evaluate on the ClearPose dataset & perform robotic grasping expts. for 10 diverse objects and find remarkable performance across the board, even when placed on challenging unpatterned, glossy white tables w/ harsh lights
Video: https://t.co/kl0TFzZxTs
Introducing Segmentation-AIDed NeRF (SAID-NeRF) for depth completion of transparent objects. NeRFs can capture specular surface effects of transparent objs but struggle to recover underlying geometry. We exploit segmentation VFMs like SAM to overcome this
https://t.co/AxxMjyv4ud
Idea: By jointly constructing a semantic field, we force estimated densities to be concentrated on the object resulting in more coherent depth. We use a heuristic to derive label-free masks & extensions to NeRF for fast, few-view estimations in complex settings