At CVPR this week for a talk on neural geometry of large vision models. If you’re interested in interpretability or joining @GoodfireAI, come say hi. 🤠
Super excited to have this paper finally out! So many nuggets here, but a critical highlight: you should *not* interpret SAE features in isolation. The population geometry is where it's all at! Similar to this image of us @GoodfireAI folks playing out the elephant parable. :P
How do SAEs capture concept manifolds? 🍩
I think this is important work.
we study how SAEs handle the geometric structures we've identified and find they tile/shatter them in a particular way we characterize, letting us recast unsupervised manifold discovery as inverse Ising
The most popular way to interpret AI is missing the bigger picture.
Models think in curved shapes. But sparse autoencoders (SAEs) work with straight lines.
Can they still capture models’ curved neural geometry? Yes, but not how you might think! (1/7)
Neural networks might speak English, but they think in shapes.
Understanding their rich *neural geometry* is key to understanding how they work – and to debugging and controlling them with precision.
Starting today, we’re releasing a series of posts on this research agenda. 🧵
Neural networks might speak English, but they think in shapes.
Understanding their rich *neural geometry* is key to understanding how they work – and to debugging and controlling them with precision.
Starting today, we’re releasing a series of posts on this research agenda. 🧵
My team at @GoodfireAI has been cooking up a new way to do interpretability: decompose a language model’s weights, not its activations.
Our decomposition natively handles attention (!) and behaves less like a lookup table and more like a generalizing algorithm. (1/6)
📣 Excited to announce our oral presentation at #ICLR!
LLMs capture rich semantic structure, as evidenced by their strong performance across a wide range of language and reasoning tasks.
But Sparse Autoencoders (SAEs), a popular interpretability tool, mostly learn local, noisy, token-level features when applied to LLMs (e.g., hundreds of features for the word “the”).
So why aren’t SAEs finding that rich semantic structure?
👉 Because they ignore the sequential nature of language.
We introduce Temporal SAEs to bridge this gap.
https://t.co/HLvuAV7Qek
🧵 [1/N]
Our research with Mayo Clinic was just covered in @TIME!
“If there's some barrier like, ‘Is interpretability useful?’ I think we've been cracking it, and I think we've smashed through it” — @DanJBalsam
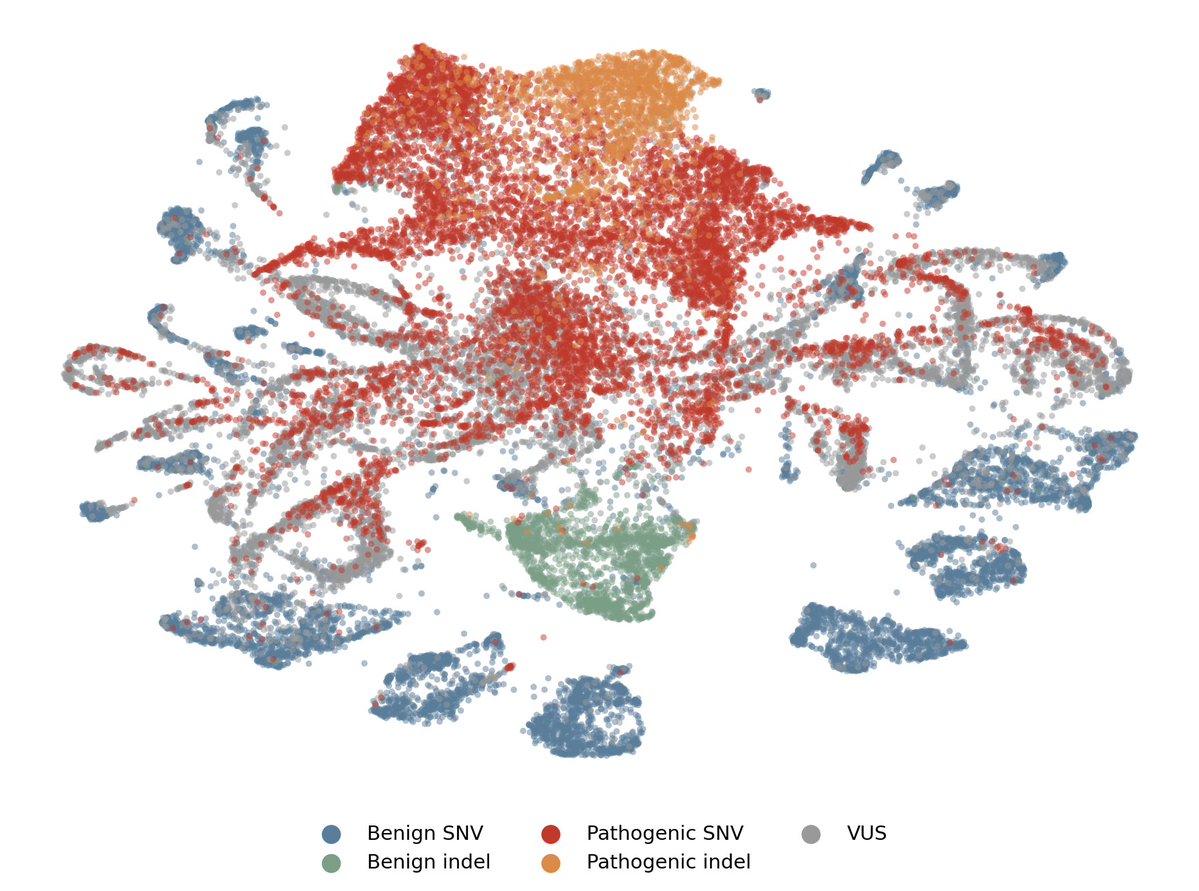
We achieved state-of-the-art performance in predicting which of 4.2 million genetic variants cause diseases by interpreting a genomics model, in a new preprint with @MayoClinic.
We're now releasing an open source database for all variants in the NIH's clinvar database. 🧵(1/8)
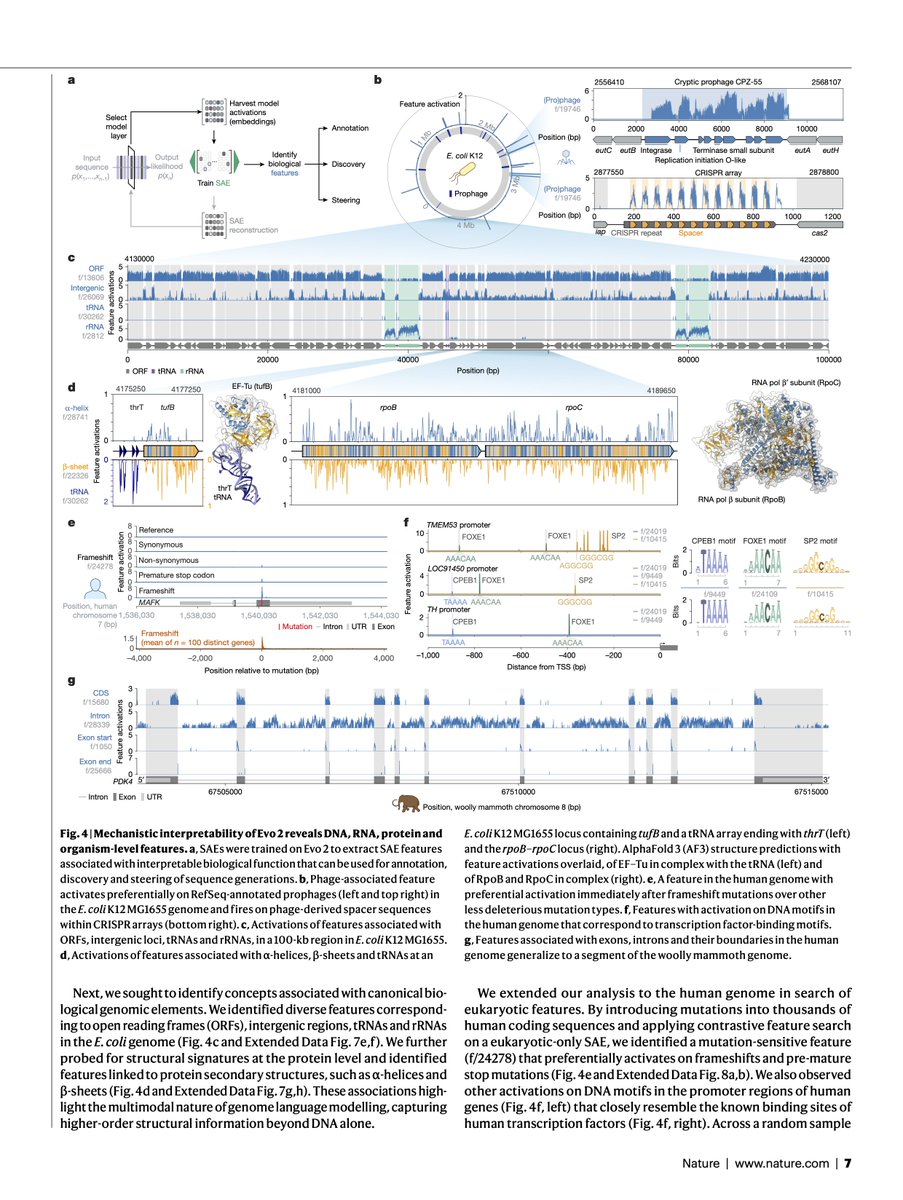
Not every day nine of your teammates get published in Nature!
We've been working with Evo 2 since its release, and have found a number of exciting results with our interpretability tools - including discovering numerous biologically relevant features in the model.
We used interpretability to scale RL against open-ended tasks, cutting Gemma 12B’s hallucination rate in half by teaching it to self-correct in tandem with our probing harness.
We raised a $150M Series B at a $1.25B valuation to fundamentally change the field of AI. Scaling is powerful, but we can't intentionally design what we don't understand.
Finally, I am pleased to announce
🪢Interpreting CLIP with Sparse Linear Concept Embeddings (SpLiCE)🪢
Joint work with Usha Bhalla, as well as @Suuraj, @FlavioCalmon, and @hima_lakkaraju, which was just accepted to NeurIPS 2024! Check out the paper here:
https://t.co/N1dmE1mkmA
One of the biggest criticisms of the field of post hoc #XAI is that each method "does its own thing", it is unclear how these methods relate to each other & which methods are effective under what conditions. Our #NeurIPS2022 paper provides (some) answers to these questions. [1/N]

























![hima_lakkaraju's tweet photo. 📣 Excited to announce our oral presentation at #ICLR!
LLMs capture rich semantic structure, as evidenced by their strong performance across a wide range of language and reasoning tasks.
But Sparse Autoencoders (SAEs), a popular interpretability tool, mostly learn local, noisy, token-level features when applied to LLMs (e.g., hundreds of features for the word “the”).
So why aren’t SAEs finding that rich semantic structure?
👉 Because they ignore the sequential nature of language.
We introduce Temporal SAEs to bridge this gap.
https://t.co/HLvuAV7Qek
🧵 [1/N]](https://pbs.twimg.com/media/HGXy7v4bYAA_Pg_.png)


![hima_lakkaraju's tweet photo. One of the biggest criticisms of the field of post hoc #XAI is that each method "does its own thing", it is unclear how these methods relate to each other & which methods are effective under what conditions. Our #NeurIPS2022 paper provides (some) answers to these questions. [1/N] https://t.co/eOTPJG9AaB](https://pbs.twimg.com/media/Fc9uTnHX0AUSV55.png)




















