🎉 The vLLM community just got a free course, built by @RedHat_AI with @DeepLearningAI. It walks through the full optimize → deploy → benchmark lifecycle for serving open models.
Three labs, each on a live vLLM server:
- Compress: quantize a Qwen model with LLM Compressor, then measure the size vs. accuracy tradeoff
- Serve: deploy with vLLM's OpenAI-compatible API and watch continuous batching, PagedAttention, and prefix caching in the live metrics
- Benchmark: simulate traffic with GuideLLM and check quality with lm-eval
A lot of the work went into visualizing what actually happens under inference, thanks to @cedricclyburn: how tokens flow through the model, how the KV cache grows in GPU memory, and what changes when you move from FP16 to INT8/INT4.
~1.5 hours, 9 lessons, 3 labs. Free on https://t.co/pGAwqbmMdc.
📝 Read more: https://t.co/r8ITc2prI2
New short course: Fast & Efficient LLM Inference with vLLM, built in partnership with @RedHat and taught by @cedricclyburn.
Learn to quantize an open-source LLM, serve it with vLLM, and benchmark your deployment across speed, cost, and accuracy.
Free to enroll: https://t.co/czVwJBnLZ6
Congrats to the @googlegemma team on the Gemma 4 12B launch 🎉 Day-0 support on vLLM is ready to go.
It's an encoder-free unified multimodal model — text, image, audio, and video all project straight into the LLM's embedding space, no separate vision or audio towers. 256K context, built-in thinking, native tool calling.
Reasoning + tool parsers (`gemma4`), vision, and audio all served through the OpenAI-compatible API.
🔗 Recipe: https://t.co/MGJcoQkwzz
Meet Gemma 4 12B!
A unified, encoder-free multimodal model designed to bring high-performance intelligence directly to your laptop, and released under an Apache 2.0 license.
Bridging the gap between edge efficiency and advanced reasoning. Here is what’s new with Gemma 4 12B: 👇
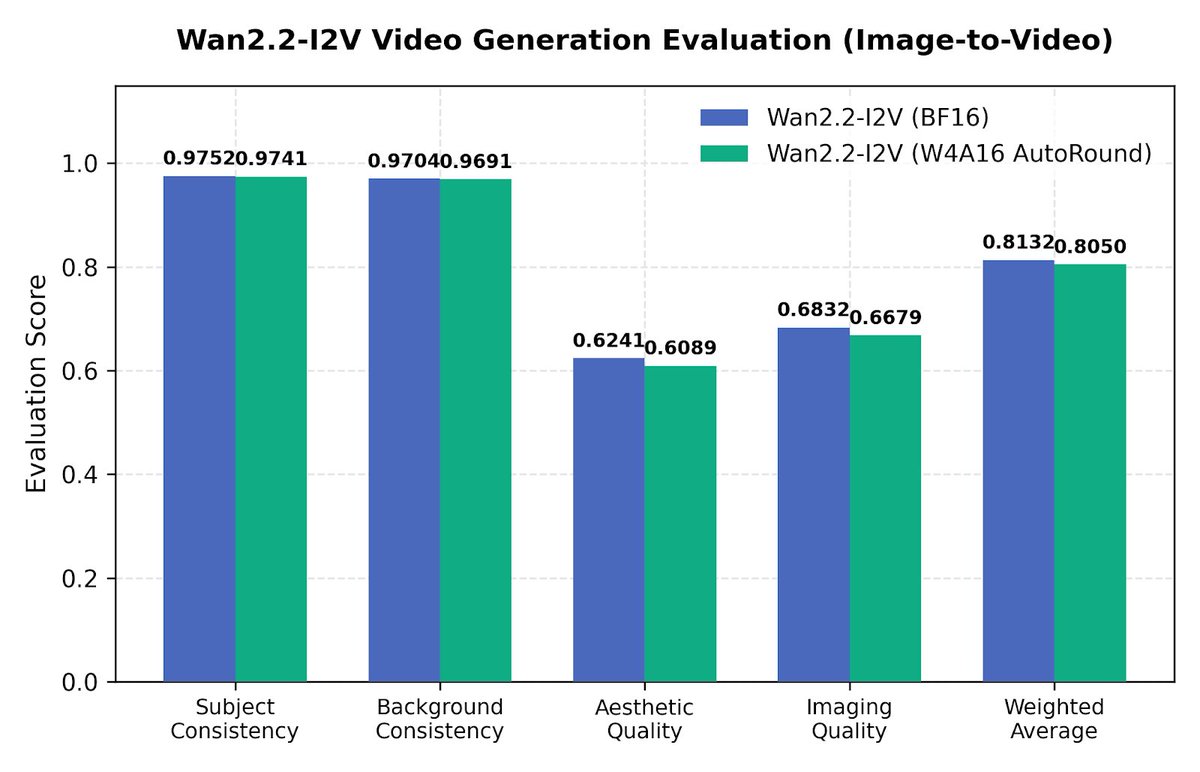
Intel's AutoRound post-training quantization is now integrated natively into vLLM-Omni, bringing W4A16 (4-bit) to Omni multimodal, diffusion image, and video models. It cuts Qwen3-Omni-30B from 66GB to 25GB with no quality cliff. Quantize once offline, then serve with the same command as the BF16 model.
📈 Highlights:
- weights shrink to ~1/4 of BF16, dropping FLUX.1-dev from 4 GPUs (TP=4) to a single one
- accuracy held on OmniBench, with ~1.3% drift on text-to-image
- on Intel XPU B60, the freed memory unlocks CFG Parallel for 1.55-1.67x faster guided diffusion
🙌 Thanks to @IntelAI, @HaihaoShen, and the vLLM-Omni team for the collaboration!
🔗 https://t.co/LRvkwAnNcL
KV Cache re-use is the most important thing for agentic rollouts. We've integrated Mooncake Store into prime-rl with vLLM, you can now use it as a drop-in replacement for native CPU/Disk offloading, giving you cross-node prefix cache reuse to make your agents go brrr🚀
🎉 MiniCPM-o 4.5 has been merged into vLLM-Omni 🎙️
It's a 9B end-to-end omnimodal model: text / image / audio / video in, text + speech out. This first integration brings simplex, non-streaming serving, with duplex streaming up next. 🚀
`vllm serve openbmb/MiniCPM-o-4_5 --omni --trust-remote-code`
Thanks to the @OpenBMB and vLLM-Omni team for the collaboration 🙌
🔗 Recipe: https://t.co/Qp6M74Gdib
🎉 Exciting News! MiniCPM-o 4.5 has officially been merged into vLLM-Omni! 👏
💡 Currently, it supports simplex non-streaming usage—a solid first step for what's to come.
🚀 The journey continues! We will keep pushing forward with the amazing open-source community to integrate duplex streaming capabilities next.
Get ready for an even more powerful and seamless interactive experience. Stay tuned! 💪
https://t.co/tbkwuHoPmv
https://t.co/bRcld16Jco
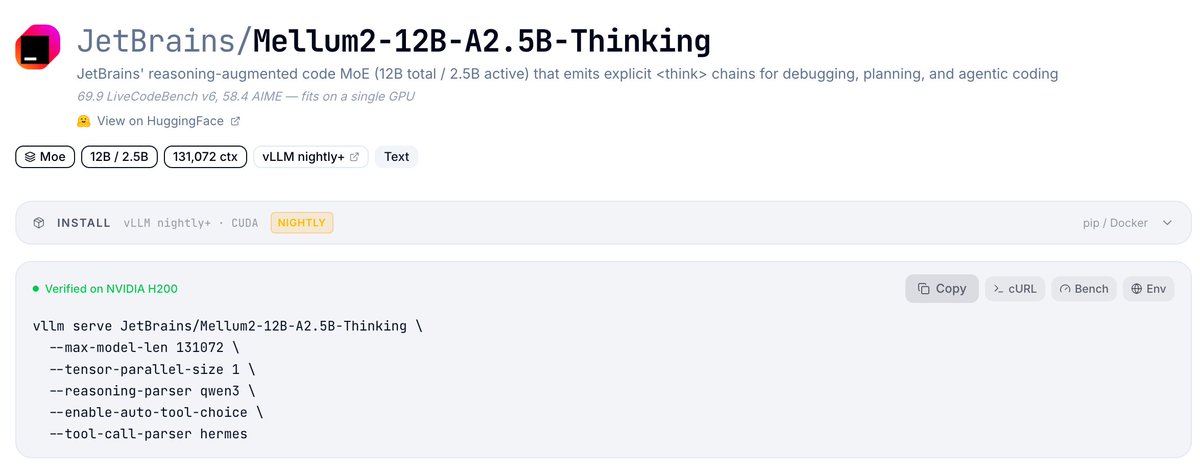
🎉 Congrats to @JetBrains on Mellum2-12B-A2.5B-Thinking, an open-source 12B MoE that activates just 2.5B params, handling both natural language and code with a 128K context.
Mellum2 runs natively in vLLM from day 0, with reasoning parser and tool calling for agentic workflows.
🔗 https://t.co/72E6HDOHNf
Mellum started with code completion.
Mellum2 is built for more – handling both natural language and code.
A 12B-parameter open-source LLM for routing, RAG, and sub-agents, optimized for ultra-low-latency inference.
Now on @huggingface.
Learn more: https://t.co/28sG8Ql52L
🚀 We're excited to partner with @NVIDIARTXSpark pushing local AI agents forward on DGX Spark + RTX!
This is exactly the direction explored in @Inferact's hands-on #vLLM + #DGXSpark blog—serving large NVFP4 models locally on NVIDIA DGX Spark. vLLM is an ideal fit, bringing streaming responses, paged KV cache, runtime tuning, and Prometheus metrics into a familiar serving workflow.
To put it to the test, the team built a live 20 Questions game—using DGX Spark as the local inference endpoint and vLLM telemetry to track real serving behavior.
Key takeaways:
🧠 DGX Spark brings large-model inference closer to developers
⚙️ Unified memory makes serving config especially important
📦 NVFP4 MoE models are a strong fit for Spark's local inference profile
📊 vLLM gives developers the tools and metrics to understand real serving behavior
Try it on your own Spark 👇
https://t.co/bWkBfpKf3M
Local AI Agents are leveling up across DGX Spark & RTX PCs.
NVIDIA OpenShell is coming to Windows alongside new agentic AI optimizations and creator app updates — including NVIDIA Broadcast 2.2, plus upcoming RTX acceleration for Adobe apps and Blender.
More 👇
🚀 Excited to partner with @NVIDIAAI on day-0 support for Cosmos 3 on vLLM-Omni!
A unified Mixture-of-Transformers fusing an AR reasoner + diffusion generator across text, image, video, audio & robot action - all behind a single OpenAI-compatible API, with a ready-to-deploy Docker image!
📖Check out the detailed deployment guide👇
https://t.co/mhLvsZXB4i
Introducing Cosmos 3: Our latest frontier model for Physical AI
Cosmos 3 is the world’s first fully open omnimodel with native vision reasoning, world and action generation.
Today we’re releasing Super (32B) and Nano (8B) variants.
🚀Great to see @RedHat_AI and @poolsideai team up to make Laguna XS.2 faster and cheaper to serve in vLLM. A DFlash speculator built with Speculators drafts 8 tokens per forward pass for 2-3x faster decoding at no quality loss, and LLM Compressor adds FP8 / NVFP4 / INT4 checkpoints so you can match your hardware budget.
🔗 https://t.co/3mguMKtwTt
Laguna XS.2 from @poolsideai is a 33B MoE built for agentic coding.
Red Hat AI trained a DFlash speculator for it: 0.6B drafter, 8 tokens per pass, no quality loss.
FP8, NVFP4, and INT4 checkpoints via LLM Compressor.
Models in comments. Speedup with @vllm_project:
Models, serving, and what to know before upgrading:
🆕 New architectures: MiniCPM-V 4.6, InternS2 Preview, OpenVLA
🦅 Spec decode: custom callable proposers; Gemma3/Gemma4 multi-GPU fixes + batched vision encoders
🔧 Tool calling improvements across multiple model families
⚠️ Breaking:
• Removed deprecated `get_tokenizer` and `resolve_hf_chat_template` locations
• Eliminated deprecated MLA prefill arguments
• Cleaned up dead CUDA kernels and code
🙏 Thanks to all 230 contributors this cycle (63 new).
📖 Full release notes → https://t.co/fUAdzeCogu
Great to work with @NVIDIAAI on running @StepFun_ai's Step-3.7-Flash with vLLM on the DGX Station.🤝
Run it locally, or in production as an @NVIDIA NIM container, both powered by vLLM! Serve it now 🚀
🔗 https://t.co/VnMzyXW75R
Speculators v0.5.0 just dropped with 3 big updates:
- DFlash training support. Draft all tokens in one pass via block diffusion
- Unified online/offline training powered by @vllm_project's hidden states extraction system
- Docs & tutorials overhaul for faster onboarding
https://t.co/tCMZIrgQf2
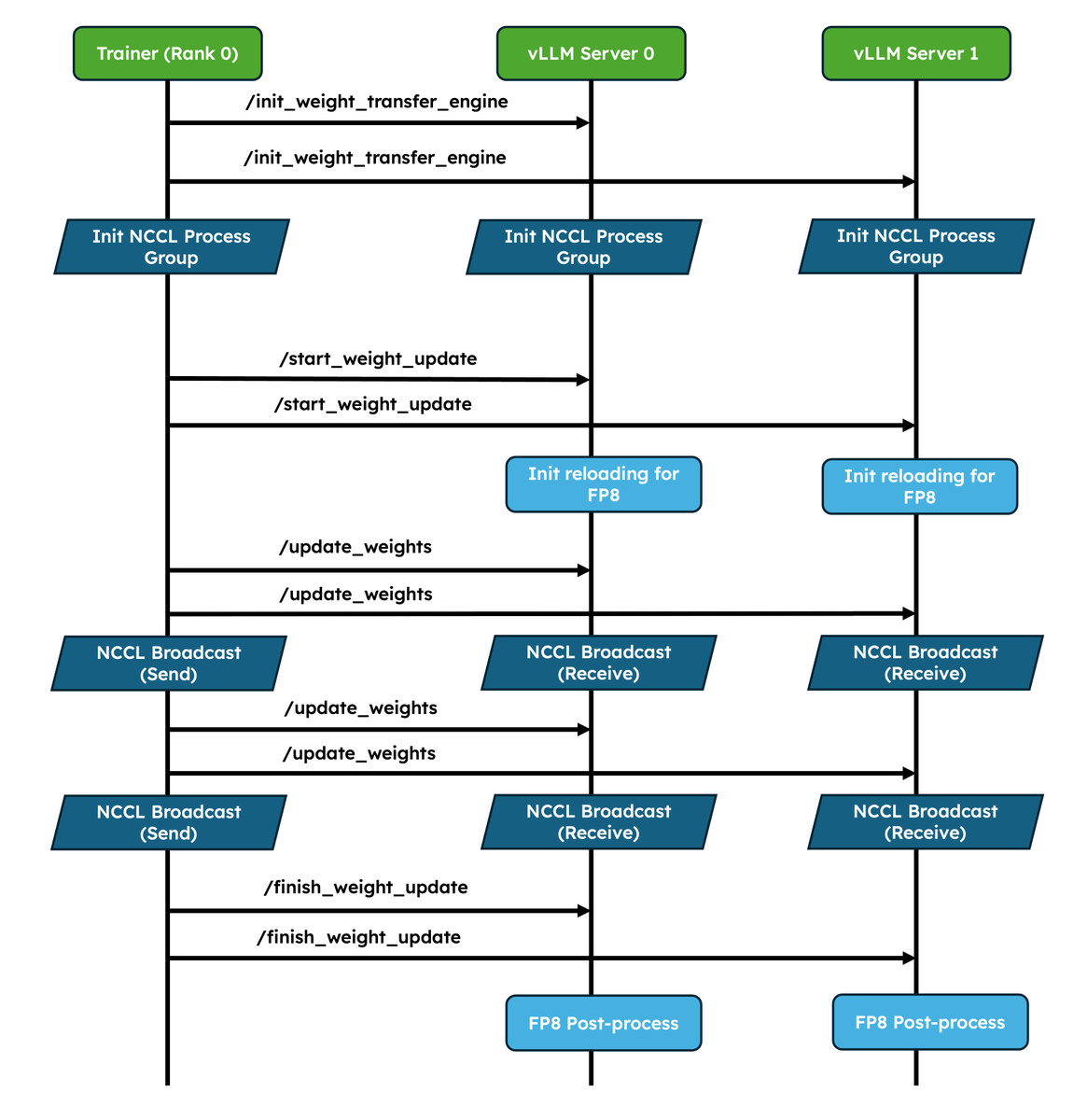
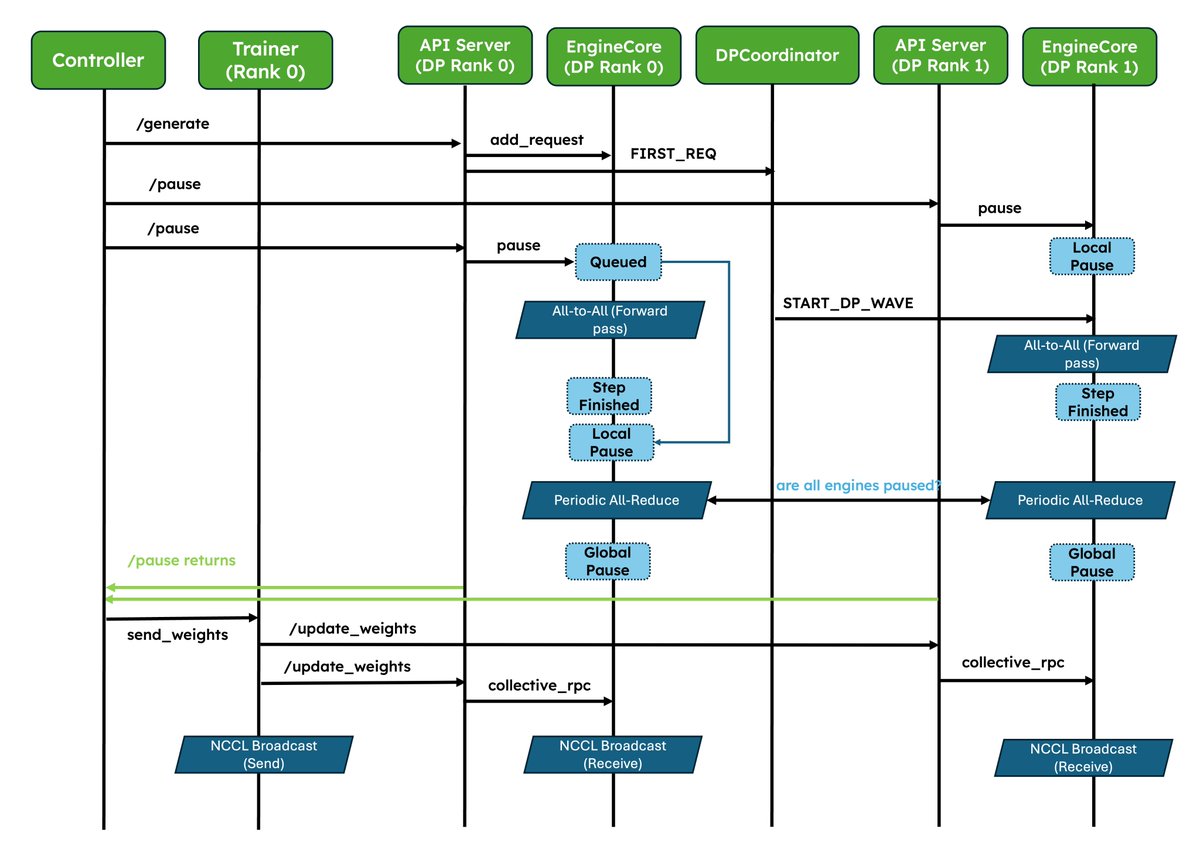
We've shipped two major upgrades for RL✨!
1. Native weight syncing APIs: Standardizes weight transfer, provides optimized implementations for NCCL and CUDA IPC out of the box, and also lets frameworks easily bring their own.
2. Improved pause/resume for Async RL: Careful coordination between DP ranks so that engines don’t deadlock. Validated at scale in P/D, wide-EP setups!
In collaboration with @anyscalecompute, @NovaSkyAI, and @RedHat.
More and more RL frameworks are using vLLM as the default for inference, details in the blog 👇
https://t.co/LLmL8zJLtR
🎉 Congrats to @StepFun_ai on releasing Step-3.7-Flash, with day-0 support in vLLM.
- 198B sparse MoE vision-language model, ~11B active params per token, native image + text input
- 256K context window for long docs, multi-file repos, and dense visual interfaces
- FP8 and NVFP4 quantized weights ready to go
built-in MTP speculative decoding, native tool calling, and reasoning parsing. Serve it now!
🔗 https://t.co/XEqSqFEmVt
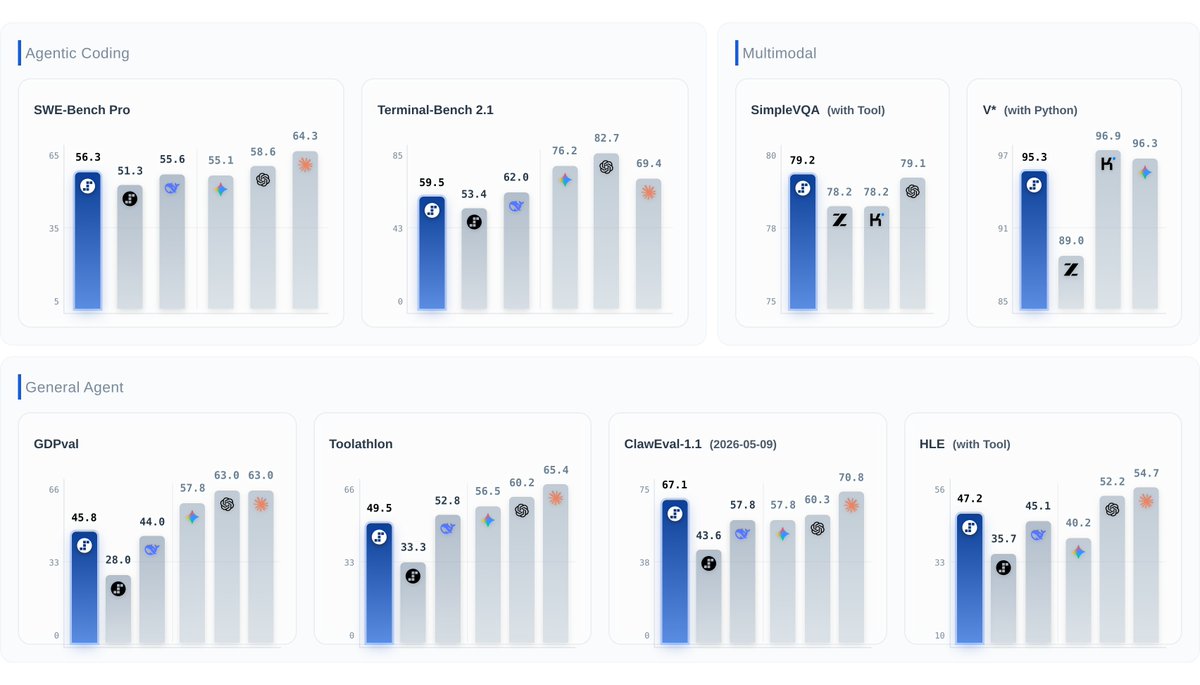
⚡️ Step 3.7 Flash is here: The new frontier is agent efficiency.
#1 ClawEval-1.1 (67.1), #1 SimpleVQA Search (79.2), #2 SWE-PRO (56.3), 95.3 on V* Python. Open weights under Apache 2.0.
Built for agentic, coding, search, and multimodal workflows — balancing speed, cost, and reliable execution.
- 400 TPS. 198B sparse MoE, ~11B active. 256K context, 3 reasoning levels.
- Understands UIs, charts, docs, images — then writes code or calls tools to act on what it sees.
- Web + visual search reaches further: more sources, deeper follow-up.
- Reliable tool use — less drift, fewer broken toolcalls. 98%+ on τ²-bench across all difficulty levels.
- Works with Claude Code, KiloCode, Hermes Agent, OpenClaw, and protocols like MCP.
- Runs locally on Mac Studio M4 Max, DGX Spark, AMD AI Max+ 395.
GitHub: https://t.co/kqlZkVIRHv
HuggingFace: https://t.co/qqceCrgPiw
GGUF: https://t.co/rR6XrnymWG
ModelScope: https://t.co/wney6Tzvqy
API: https://t.co/RvHWzRG7Fu
Blog: https://t.co/BxDiajiQ5G
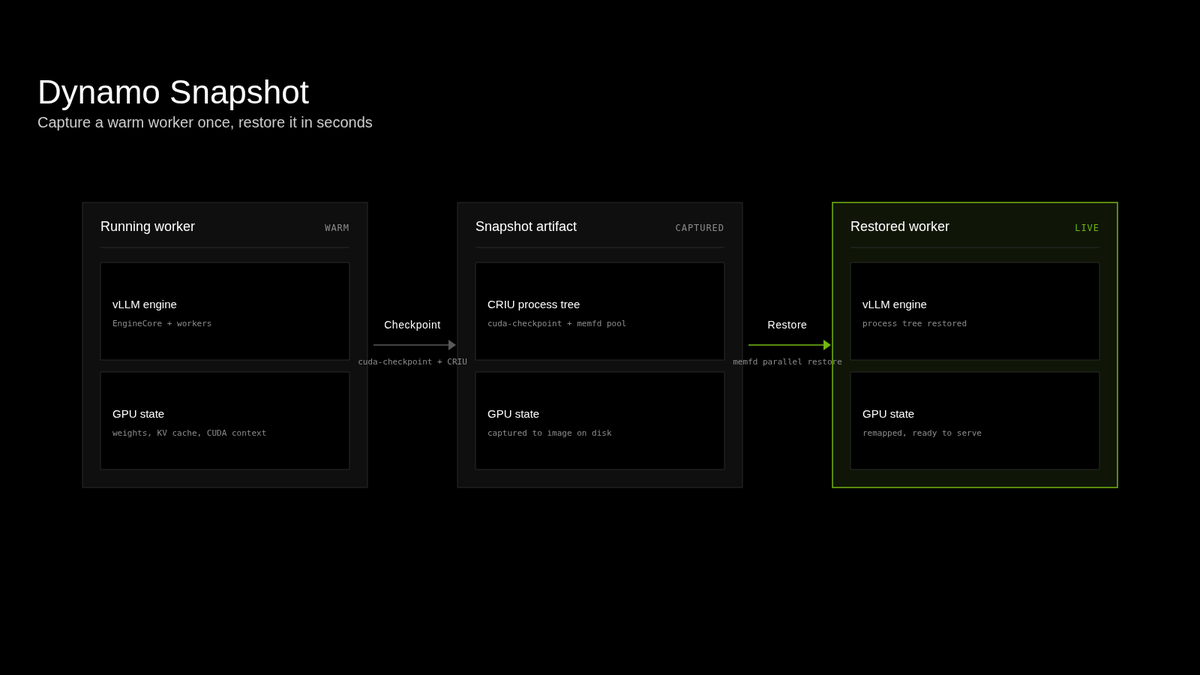
Love seeing vLLM as the engine powering @NVIDIAAI's Dynamo Snapshot.
Checkpoint the full vLLM worker (process tree + GPU weights/CUDA context) via cuda-checkpoint + CRIU, then restore with memfd parallel restore in <5s.
Great work to the @NVIDIAAI team!
Introducing Dynamo Snapshot, our approach for fast startup for inference workloads on Kubernetes, which reduces startup time from minutes to under 5 seconds.
In production inference deployments demand fluctuates over time. Cold-starting inference workloads can take minutes, leaving idle GPUs that generate no tokens and serve no requests.
Snapshot leverages GMS to enable concurrent weight restoration over a high-speed interconnect, while using Linux native AIO and parallel memfd restoration to accelerate CRIU restore performance.
Today, EAGLE powers some of the industry’s most formative AI infrastructure companies and teams.
With EAGLE 3.1, we’re taking another major step toward delivering a core piece of the fastest possible inference stack that exists, open to all.
By improving hidden-state feedback stability and mitigating attention drift across deeper decoding steps, EAGLE 3.1 significantly improves long-context acceptance length and serving robustness in real-world inference environments.
We are thrilled to collaborate with vLLM @vllm_project and TorchSpec @lightseekorg on advancing the next generation of inference acceleration infrastructure.